榕树网络BanyanNetwork(BBN)介绍、网址及交易平台



数据是大数据产业发展的基础,具有商业价值的数据能帮助企业洞察客户、数字化运营、风险管控、精准营销、预测和决策等。具有商业价值的数据,配合商业分析,能真正帮助企业提升业务,创造出新的价值。尤其是把不同维度的数据关联在一起,交叉挖掘分析,就有可能发生“化学反应”,因共享而增值。
全球的大数据市场还不成熟,很多大数据企业拥有的数据具有片段性,难以形成完整且具有商业价值的数据。商用化的数据供给和数据需求存在较大的差距,数据普遍具有孤立性,缺乏流动性,或者因未经清洗、加工融合而无法发挥价值。并且随着数据发掘的不断深入,在各行业的应用不断推进,大数据安全的“脆弱性”逐渐凸显。
随着区块链时代到来,正发生着由技术权威垄断到去中心化的本质转变,大数据和分布式的结构二者存在密不可分的关联。
数据源层面:数据获取门槛较高,数据不完整且割裂封闭,每个数据源只能提供部分可用信息;数据误差大,缺乏多重数据源校正,精确度难以保证。
数据产品层面:产品化程度低,接口无标准且接入复杂;解决问题方式单一,效果无法衡量。
数据安全层面:欠缺合规体系,数据来源难追溯,前置授权难获知。
大数据+区块链
榕树网络去中心化的核心优势是通过契约关系形成智能合约或智能资产,区块链成为数据价值链中的一个万能账本。链上记录保证任何数据无法被非合规复制、截流、沉淀或修改,数据价值不存在被盗用及弱化,从而极大降低数据源对榕树网络的信任成本。另一个优势是突破地缘和时间限制,提高各参与方的透明性、延展性和效率,促使产生更大的数据流动性和更高的数据价值。
在此之上, 榕树网络数据为人工智能的数据供应基础设施,满足其应用开发的几乎所有数据源供给、数据服务采购以及高性能的分布式数据处理能力,为人工智能的未来提供充足的燃料。
榕树网络一方面加速工具和平台的落地,一方面持续的评估现有底层公链对大数据场景的适用性,尤其是支持和外部数据交互的智能合约。榕树网络将会在 2018 年第四季度发布底层公链评估结果并征求社区意见,来决定是否投入开发面向大数据行业的垂直公链。
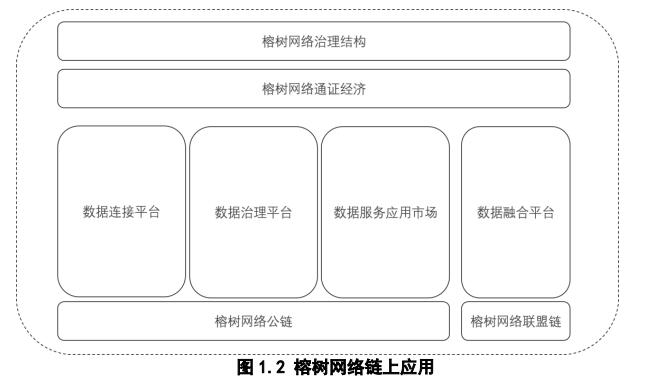
数据连接平台
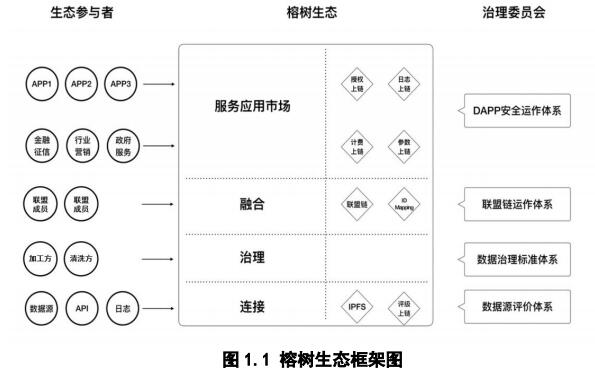
1 数据连接平台
数据连接平台致力于成为全球最好的大数据超级应用服务平台。平台将整合全球所有优质数据源,形成一站式数据网关接口,通过连接一切数据,构建多方安全的数据融合服务生态,以全息视角为企业提供多维数据洞察应用,专注于打造全球最优秀的一站式数据生态体系。
数据连接平台以大数据和区块链技术为驱动力,以去中心化为本质,实现全域 ID-Mapping。从数据的角度出发,为全球企业解决业务难题。
目前数据连接平台对外开放使用,逐步对接全球主流数据源,逐步开放部分数据类型包含电商数据、运营商数据、政府数据、金融数据、互联网行为数据等各种主流数据源。
2 数据源评价平台
为保证让各大数据源的接入方和应用方放心的使用源头数据,榕树网络将构建数据源评价体系,并将进入评价体系内的数据源评分结果实时上链。数据代理方或者数据的使用企业可以实时查看各类数据源的评分等级并据此选择接入的数据源,数据源也可以依据自己的评分不断的去优化完善自身的数据精准度。
2.1 标准数据源评分体系
从数据的准确率、覆盖率、时效性、数据源性能等角度构建一个评价体系,用于数据科学性客观性的评级,以市场各大标准数据源为评级案例,评级系统可覆盖各大银行数据、银联数据、运营商数据、互联网电商数据等。榕树网络会定期的对各类标准数据源进行阶段性的评分并实时上链,数据源评价体系的公开性、不可更改性,可推进数据源本身处理数据问题的严谨性和规范性,也为接入方接入优质数据源提供了科学性的可量化标准。
2.2 非标准数据源评分体系
除去数据市场上众所周知的垄断性数据源,还会有各类爬虫数据,针对这些非标准化的数据源头,榕树网络也会依据自身的数据基础建立一套针对各类非标准数据源的评分体系,并将评分结果定期上链。
数据治理平台
数据价值的准确与否在于数据本身质量的好坏。数据的清洗理一直是大数据应用的关键环节,所谓 garbage in,garbage out,只有将数据治理充分,排除噪音,才能为后续的数据挖掘建模打下坚实的基础。
1 治理规范
榕树网络在数据治理上提供了一系列规范和工具,供数据参与方和社区使用。
数据完整度规范:评估字段完整度的规范。格式化的数据由不同的字段组成,每一条数据字段是否齐全,字段不全的数据占比多少;每一条数据的每一个字段是否有值,无值的占比多少等等完整度问题,这些都由该规范进行定义。
数据类型规范:数据字段都可以归纳定义为一种类型,包括数值类型、字符串类型、日期类型、枚举类型等等,不同的类型有其不同的格式、内容要求,例如十进制的数字类型不应出现 0~9 之外的字符,日期类型都有一定的格式,枚举类型必须包括有限的内容等等,该规范对各种数据类型应满足的条件进行定义。
数据统计规范:整体数值分布的规范。例如是数值类型,则数据数值的分布区间如何,最大值最小值是多少;如果是枚举类型(例如性别),各值占比多少等等,该规范对数据整体统计上的维度进行定义。
社区开发者都可以向治理委员会提交规范,并通过开发者社区投票表决,如果规范通过,相应开发者将获得 BBN 激励。
2 治理工具
数据抽样工具:当数据达到一定的量后,无法全部逐条进行评估,数据抽样工具会根据实际场景需求,按照随机抽取、特征值抽取、区间抽取等等条件提取评估样本。
数据评估工具套件:针对数据规范,发布相应的评估工具,包括单机版、大数据平台版等等。同时根据规范制定的开发协议,社区开发者可以开发提交自己的评估工具(包括多语言、多平台版本)。
3 治理平台
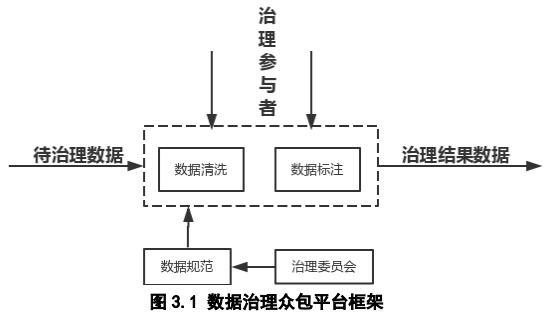
榕树网络通过社区达成共识的数据治理规范,来发布和运营数据治理众包平台。数据方可以将待处理的数据包发布到平台上,通过众包的形式发布任务,由社区参与治理。
场景一:数据清洗。数据初步格式化后,有些字段在商业场景应用时,无法直接使用,需要进一步清理。当计算机无法通过模型算法来完成时,就需要人工的介入。这种情况下可以发布到众包平台上,社区参与者可以根据要求进行清洗。
场景二:数据标注。数据建模机器学习过程需要各种各样的样本数据,样本可以发布到众包平台上,平台会根据内置的算法自动预处理样本,减少人工的工作量,同时根据人工标注的结果再进一步优化预处理算法。
数据源方支付 BBN 给众包治理参与者。平台会将数据治理的结果保存到区块链上,保证各方利益。
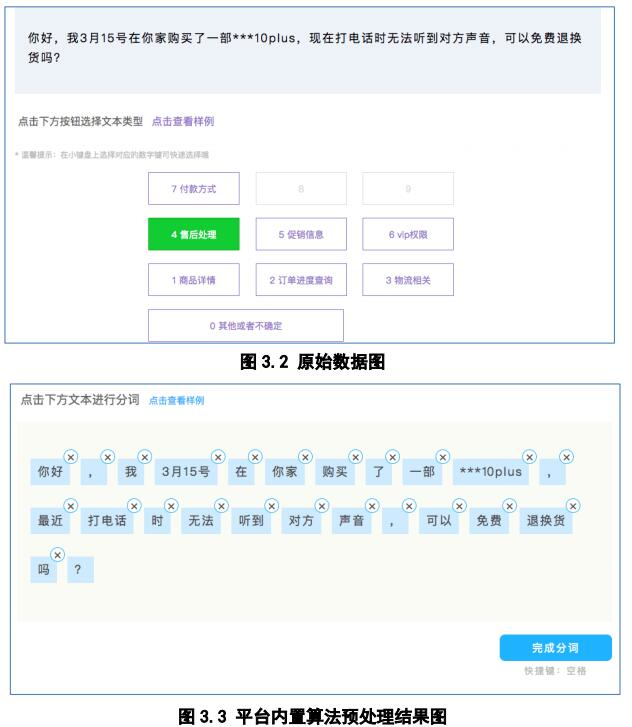
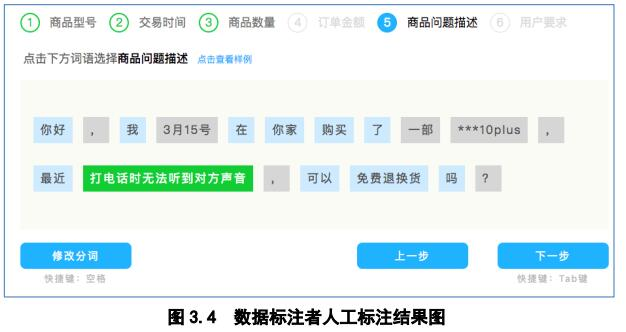
目前平台一期在测试使用阶段,其中一个场景就是电商客户的客服系统文字分词标注。
如下图所示:图 3.2 为初始文本输入到标注平台中,图 3.3 是平台利用自然语义分词算法进行分词,但是该分词只是纯粹的算法预处理,可能不适应业务场景,所以需要图 3.4 的人工标注,例如 “打电话时无法听到对方声音”拼成一句话,得到一个商品问题的维度。
4 区块链使用
数据治理平台的各种数据,例如数据评估结果、数据标注结果等都会保存到区块链上。由于目前公链的性能限制,不会把结果数据直接保存到公链上,而是将数据保存到 IPFS 上,通过 Merkle Tree结构将节点 hash 保存到公链上。

Breaking: New Hampshire Becomes First U.S. State to Officially Hold Bitcoin in State Reserves
The post Breaking: New Hampshire Becomes First U.S. State to Officially Hold Bitcoin in State Reserv...
Raoul Pal: Bitcoin Could Hit $450,000 In Liquidity-Driven Supercycle
At Sui Basecamp, macro investor and Real Vision co-founder Raoul Pal delivered a characteristically ...

Solana price prediction: Can SOL rally as Pump.fun tops Ethereum in annual fees?
Solana price prediction: Can SOL rally as Pump.fun tops Ethereum in annual fees?