Rollup排序器完全指南:概念、现状与共享排序



原文作者:James Prestwich
原文 编译: 0x11 ,Foresight News
共享排序器正在飞速发展,是时候对它是什么及其存在的原因进行深入分析了。这篇文章分析的对象仅限于 Optimistic Rollup,欢迎 ZK 关注者前来指教。
排序器是什么?
排序器是 Optimistic Rollup 中的半信任化角色。虽然交易可以由主链本身进行排序,但这并不经济,用户必须单独提交其 Rollup 交易对应的主链交易,并支付主链上费用。排序器通过允许 Rollup 交易共享单个主链交易来为用户解决这些问题。
排序器聚合链下的多笔用户交易来补充主链的排序,并将它们作为单个交易集合提交到主链,交易成本在用户间分摊。排序器还可以压缩交易集合,进一步节省主链数据可用性成本。与依赖 排序器的用户相比,自主排序的用户将为包含在 Rollup 中的交易支付更多费用。
但是,排序器可以对交易集合中的交易排序进行控制。它可以选择不包含用户交易,从而迫使用户自行排序,支付更高的主链成本。它还可以通过重新排序和插入提取的方法在交易集合中提取 MEV。它们实际上拥有对 Rollup 的优先写入权限。值得注意的是,因为排序器可以与合约交互,所以只有绝对可靠的交易才能通过链上机制可靠地强制执行,不可靠的交易在强制排序时很可能会失败。
这使得排序器成为 Rollup 用户的半信任方。虽然排序器无法阻止用户访问 Rollup,但他们可以延迟用户的访问,导致用户承担额外的费用,并从用户的交易中提取价值。通过去中心化进一步约束排序器的行为是一个活跃的 研究课题 。
排序和执行有什么区别?
排序器是主链排序的补充,它不计算 Rollup 的状态,实际上它可能会选择对无效交易进行排序。Rollup 节点必须解析和清理排序数据,导出 Rollup 的有效历史记录,并执行历史记录以生成最新状态。排序器则完全不参与此过程。
不过,正如我的朋友 Fred 不断提醒我的那样,一旦交易被排序,结果就是确定的。这意味着所有 Rollup 节点将根据排序器生成的顺序达成一致结果。给定已知历史,Rollup 有一个正确的状态。一旦节点找到这个状态,一个或多个提议者会将其提交给主链的 Rollup 合约。
理论上,任何节点都可以是提议者,不需要任何权限。提议者将状态连同保证金一起提交给主链。如果欺诈证明结果是状态无效,保证金就会被没收。该合约在计时器结束后接受证明,然后其中包含的用户交易在主链上执行。执行节点通过欺诈游戏确保提议者诚实,我们倾向于将执行节点称为「Rollup 全节点」或「验证者」。
换句话说,一旦排序被提交到主链,状态就变成最终的和不可变的。提议者计算并报告最终状态给 Rollup 合约,以维护 Rollup 到主链的资产桥的利益。提议者不会创造状态,他们只是计算并证明它。Rollup 合约不会创建或最终确定 Rollup,它只是从提议者那里获得 Rollup 状态。
为什么要将排序和提议分离?
这是一个复杂的问题。从根本上说,将它们分开是因为它们本身是分开的。这听起来像是同义反复,但似乎每个人都花了很长时间才意识到这一点。我们蓦然回首,才发现 Rollup 的思想历史多年来一直在 Plasma 和状态通道中曲折发展。在基于比特币的 proto-Rollup 早期,并没有排序器,用户只需将他们的交易发布到主链。之后,这种设计消失多年,最终因为 Barry 的工作重新出现。在 Barry 和 Celestia 之间,Rollup 的研究主要集中在 Rollup 桥与主链的交互上。在 Sovereign Rollup 出现之前,甚至没有人意识到我们其实在构建更好的 Mastercoin。
抛开出处不谈,排序器解决了一个特定的问题:用户交易成本最小化。然而,这个过程中又引入了一个新问题:排序器可以同时对同一交易产生多个排序结果。如果排序完全由主链完成,将会有一个单一的规范排序,但用户交易费用会更昂贵。我们选择使用排序器来改善 Rollup 中的用户体验。
假设存在很多个排序器,因为有多个提议者。排序器们可以提交相互冲突的排序,我们现在需要一种机制来「规范」主链上的特定排序批次。当前的 Rollup 通过一个单一的、特定的、已知的、半可信的排序器来实现这一点。选择单个排序器使我们能够解决这个问题,直到去中心化排序器到来。因为我们想要多个提议者,但只需要一个 排序器,所以必须将这两个角色分开。
数据依赖性是另一个重要的原因:提议者需要排序,但是排序器不需要状态。提议者依赖于排序器工作的输出,但是排序器不依赖于提议者。因为数据依赖是单向的,所以需要在角色之间划定界限,并允许参与者专注于单一角色。
为了回答最初的问题,我们将提议者和排序器分开,因为它们本身是分开的。提议者在排序器的下游工作。Rollup 将信任和权威授予了排序器,而提议者只是一个普通工作人员。
排序器、提议者和验证者现状
Arbitrum 和 Optimism 是两种常见的 ORU 方案。我想简要介绍一下他们中的主要角色,不会涉及到代码,只是规范和文档。Optimism 的讨论将仅限于(尚未部署的)Bedrock 设计。
Arbitrum
除了批处理和压缩用户交易外,Arbitrum 排序器还运行一个完整的节点。交易被直接发送到排序器,它在交易排序时创建一个可信的 WebSocket 提要。Arbitrum 将此提要作为「软」确认来源。排序器对排序结果作出承诺,用户通常可以依赖该排序。节点、MEV 搜索者或其他参与者可以使用此提要来预先计算 Rollup 状态。
排序器会定期将经过排序的压缩交易发布到主链。主链最终确定代表 Rollup 的「硬」确认。一旦主链确定了排序,它就成为 Arbitrum 链上不可更改的部分,其中排序的所有交易都成为最终状态,结果状态也成为最终状态。
自然地,因为排序器设置交易顺序,所以它具有优先写入权限。排序器可以控制排序的内容,从而控制 Rollup 历史中交易的排序。当然,用户可以通过主链上的 delayed inbox 强制包含交易。搜索者已经竭尽全力将 WebSocket 交易提要的延迟降到最低,因此他们很可能会形成一个强大的 MEV 市场来对 Arbitrum 交易进行排序。
有 13 个经过许可的 Arbitrum 提议者,他们中每一个都在名为「 RBlock 」的特定承诺中托管了 ETH。用户可以选择依赖一定比例的质押来做出关于 Rollup 的最终决定,而无需运行 Rollup 完整节点。虽然 Arbtirum 验证者可以识别欺诈,但只有提议者可以通过欺诈证明质疑承诺的有效性。实际上,只有提议者可以成为完整的验证者。

正义,就像一个排序器,是盲目的,它必须带着剑
Optimism
与 Arbitrum 一样,除了批处理和压缩用户交易外,Optimism 排序器也运行一个完整的节点。交易直接发送到排序器,排序器在排序时创建可信的预确认。Optimism 用户可以使用这些确认作为最终软确认的来源。排序器对排序作出承诺,用户通常可以依赖该排序。节点、MEV 搜索者或其他参与者可以使用这些确认来预先计算 Rollup 状态。
排序器会定期将经过排序的压缩交易发布到主链。主链最终确定代表 Rollup 的「硬」确认。一旦主链确定了序列,它就成为 Optimism 链历史中不可更改的一部分。其中排序的所有交易都成为最终状态,结果状态也成为最终状态。
自然地,因排序器设置交易顺序,所以它具有优先写入权限。排序器可以控制排序的内容,从而控制 Rollup 历史中交易的排序。当然,用户可以通过在主链强制包含交易。作为 MEV 拍卖概念的发起者,一个用于排序 Optimism 交易的强大 MEV 市场似乎将要形成。
Optimism 有 1 个 经过许可的提议者 。该提议者签署了对主链的特定承诺,称为「状态输出」或「L2 输出根」。用户在做出关于 Rollup 的最终决定时可以选择依赖提议者 ,而无需运行 Rollup 全节点。虽然 Optimism 验证者可以识别欺诈,但只有一个经过许可的挑战者可以通过签名来挑战承诺的有效性。挑战者可以随时删除一个 L2 输出根,无需欺诈证明。实际上,只有获得许可的挑战者才能成为完整的验证者。
小结
当前两个主要的 Rollup 都集中在同一种设计上,它可能会变得非常混乱。他们经常对同一个概念使用不同的名称,但他们的设计几乎相同。

共享排序器
在对排序器有了新的理解后,让我们继续讨论我真正想谈的内容:共享排序器。当 Rollup 共享同一个排序器时会发生什么?
不同的 Rollup 是什么意思?
借用 Ben 的定义 ,我们应该将 Rollup 视为状态、状态转换函数和证明系统。Rollup 有合约和账户,它有一个虚拟机来处理交易以更新这些合约和账户,而非主权 Rollup 有一个证明系统来运行与主链的桥接。每个组件有多种设计,它们可以在一定程度上混合搭配。
但是,有些组件比其他组件更平等。总的来说,我们大概应该把状态看作是链的本质。链不倾向于改变它们的状态。毕竟,以太坊开发者多次更改虚拟机,多次更改共识机制,但只更改过一次状态。状态即是 Rollup,虚拟机和证明系统的存在是为了支持它。因此,不同的 Rollup 具有不同的状态。它们可能共享一个证明系统或一个 STF,但两个 Rollup 永远不可能共享相同的状态。
提取、检查和过滤
Rollup 从主链历史中获取它们的状态。为了做到这一点,每个 Rollup 都必须定义一个「提取」函数。提取函数将主链历史分为 Rollup 历史和 non-Rollup 历史。STF 处理 Rollup 历史以创建 Rollup 状态。实际上,提取功能变成了一个「镜头」,Rollup 通过它检查主链。
Rollup 使排序器能够选择提取函数下一次运行的输出。排序器选择 Rollup 节点下一步将看到和处理的数据,因此对 STF 的操作和下一个状态有一定的控制。
在排序器创建主链数据视图后,Rollup 节点运行过滤功能。因为排序器不一定知道它所服务的 Rollup 的状态,所以允许在其排序中包含无效交易。提取后,Rollup 节点会看到这些无效交易,并将其删除。当给定无效交易时,Rollup 节点不会出错(就像主链那样),而是简单地忽略它并继续。L1 必须禁止垃圾信息以保持共识,而 Rollup 则不需要。
共享排序器
共享排序器为两个或多个 Rollup 的提取函数提供输入。因此,它为两者设置新的历史记录,控制 STF 的输入。它可以单独为每个 Rollup 执行此操作,也可以同时为两者执行此操作。单独设置历史记录时,它的工作方式与未共享的排序器完全相同。
然而,当同时为两个 Rollup 创建新的历史记录时,共享排序器可以通过原子「链接」两个 Rollup 的历史记录来行使一些额外的权力。排序器同时为每个 Rollup 生成序列,并确保两者都确认或都不确认。这允许排序器对两条链的历史进行控制,因此对 Rollup 的下一个状态有一定程度的控制。
原子包含(不是原子执行)
在这一点上,我必须重申,排序器可以对其产生的排序行使很大的自由裁量权。这意味着虽然用户可以使用共享排序器在多个 Rollup 上进行交易,而无需与主链进行交互,但他们不一定依赖 排序器在这些交易之间产生任何特定的关系。共享排序器的支持者设想了一种新结构,用户可以在其中指定包含的原子性,即可以强制排序器通过共享强制排序机制同时对多个 Rollup 中的一组交易进行排序。这将允许用户确保所有这些原子交易都包含在 Rollup 历史中,或者全部不包含。
这并不像看起来那么好。因为只有绝对可靠的交易才能强制排序,只有绝对可靠的交易集才能保证在原子包含时原子执行。正如我们之前所说,包含和执行是分开的。Rollup 在包含之后和执行之前通过过滤器功能过滤掉无效交易。假设排序器获取用户的原子集,并导致一个交易失败或失效。该交易将在排序后被过滤,并且不会执行。这意味着原子包含不足以保证原子执行,除非涉及的所有交易都是绝对可靠的。
具体而言,可以原子执行简单的发送和取款,但任何容易出错的东西,如交换或 DeFi 交互,都不能。不幸的是,大多数高价值交互都包含 1 个或多个容易出错的交易,因此似乎很难使原子包含发挥作用。这有效地排除了通过共享排序器进行交叉 Rollup 的 DeFi 可组合性。共享排序器不是灵丹妙药,用户的资产可能被锁定在异步跨链模型中,直到流程结束。
Rollup 组合的原子执行
还记得之前谈到的排序器如何在将排序发布到主链之前提供可信的执行保证吗?您可以设想一个共享排序器针对多 Rollup 系统做同样的事情。共享排序器可以运行每个 Rollup 的完整节点,并使用它们来确定交易是否成功。然后它可以承诺它不会产生原子交易集不全部成功的排序。
当然,这个系统是值得信任的。你会相信排序器不会说谎。您现在可能在想「我们可以通过限制排序器的行为将其转换为免信任的系统吗?」 我很高兴 / 悲伤 / 困惑地说答案是「是的,但是」。是的,但我们这样做的方法是组合每个 Rollup 的 STF,以创建一个执行所有组合 Rollup 交易的单个 STF。也就是说,我们必须使所有 Rollup 之间的所有虚拟机原子化。这相当于使它们成为相同的 Rollup。所以是的,我们可以实现不受信任的原子执行,方法是通过将多个 Rollup 合并为一个。这可能是个好主意 1, 但我怀疑它的可行性。
偶然性关系的原子执行
我在别处写过这个,另一个可靠的选择是在交易和 Rollup 状态之间集成显式的偶然关系。这会将评估突发事件的负担转移到提议者身上,因为他们必须根据他们对远程 Rollup 的信任来计算和提议状态根。但是,我认为我们可以通过重复应用过滤器功能来简化它。假设偶然性在某个交易和区块中是明确的,我们可以运行两次过滤器,一次假设预测的状态有效,一次假设预测的状态无效。这可以扩展到 n 个预测状态,代价是对过滤器函数进行 2 ^n 次评估.
在这个世界上,提议者可以证明 2 ^n 个根,每个根都有明确的偶然关系。例如,提议者可以证明「根是 X 取决于远程 Rollup 状态 A,否则是 Y」,而不是说「根是 X」。这样,提议者就不会永远评估远程 Rollup 区块。相反,他们会根据来自其他状态的假设信息,多次评估自己的过滤函数和状态。这真的很酷,因为它保留了 Rollup 的分离,同时仍然允许复杂的即时交叉 Rollup 通信。
结论
排序器是钟表匠巧夺天工之作,它设置 Rollup 历史记录,然后看着它滴答滴答地走到它的命定状态。Optimism 和 Arbitrum 并无多大差别,但两者安全性确有不同。没有人知道排序器是做什么的。共享排序器可以进行原子包含,但不能进行原子执行,如果没有 Rollup 组合或其他一些执行机制,就无法将原子包含纳入原子执行。所有这些关于共享排序器实现无缝互操作性的吹嘘都是垃圾科学。
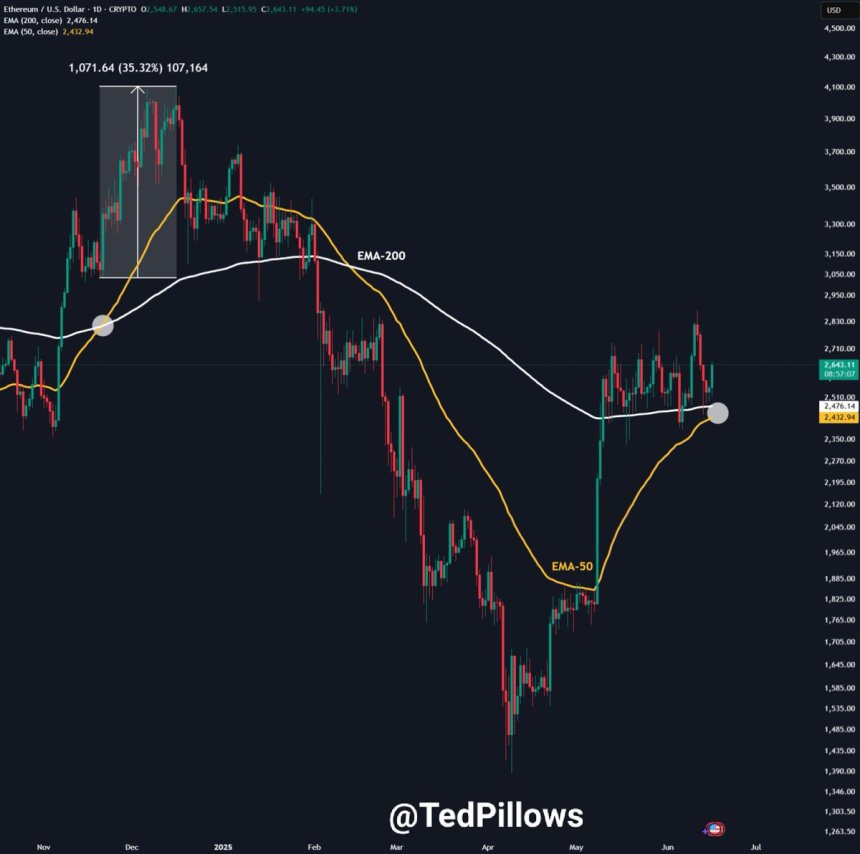
Ethereum Golden Cross Approaching – Will History Repeat?
Ethereum has faced intense volatility in recent days as escalating tensions between Israel and Iran ...

U.S. Senate Overwhelmingly Supports Stablecoins’ GENIUS Act: Next to the House of Representatives
The post U.S. Senate Overwhelmingly Supports Stablecoins’ GENIUS Act: Next to the House of Represent...
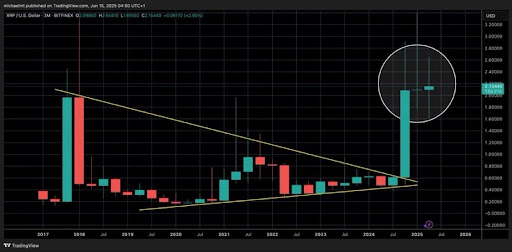
XRP To End 7-Month Consolidation After 700% Surge – Is A Major Move Coming?
After months of sideways movement, XRP may finally be gearing up for a significant breakout. Accordi...