高中教师养出40亿美元超级独角兽 Stable Diffusion背后数据集创建者



他本是一位普普通通的高中教师,却活生生养出一个估值 40亿美元 独角兽。
而且方法也是非常的独特——
打造了世界最大的免费开源数据集,却从未从中收取过一分钱,也婉拒了各类工作的邀请。

他叫舒曼,在德国汉堡市的高中教物理和计算机科学。
两年前他创立了LAION(相当于CLIP图文数据集),如今被用于各种生成模型,包括谷歌Imagen、Parti,以及惊艳全球的 Stable Diffusion 。
就连Stable Diffuision背后公司Stability AI的创始人曾亲自来送钱时,他都表现出嗤之以鼻的样子,认定“这个人一定是疯了”。
或许他怎么也没想到,只不过两年前灵机一动,就带来了生成式AI的剧变。
受DALL-E启发
2021年新年之际,OpenAI重磅推出DALL-E,GPT-3首次成功实现跨界:
只需对着它说上一段话,就能生成对应图片。
一时间风光无两,吴恩达在内的科技大佬们都激动了,网友们都称其为甲方克星。
但在德国汉堡市郊区的一间房屋内,这位高中教师舒曼(Christoph Schuhmann)却产生了对 数据私有化 的担忧:
如果这一切都集中在一家、两家或三家公司,那将对社会产生非常糟糕的影响。
当时,OpenAI发表了背后关键模型CLIP的论文。论文中显示,CLIP在4亿个图像-文本对上进行了预训练,在没有精细调整的情况下,最终在各种多模态基准中实现高性能。

由此可见数据集对于CLIP的重要性,但OpenAI并没有进行公开,它只开源了CLIP的代码和模型权重。
(看来从那时候就已经变得Close了)
于是乎,舒曼就开始在Discord网罗了一群同为AI爱好者的朋友,尝试复制OpenAI同等水平的「文本-图像对」数据集。
没想到这一搞就搞了大半年,直到2021年8月他们首次发布了 LAION-400M数据集 ,里面包含了4.13亿图像-文本对。
回顾整个创建过程,舒曼对彭博社这样形容:
就像是用数百万张 抽认卡 来教一个人一门外语。
他们用一个非盈利组织Common Crawl在2014年到2021年期间,抓取的随机HTML代码来定位网络上的图像,并将这些图像与描述性文本联系起来,最后还得根据一定规则来过滤掉不适合的样本。
比如,删除了所有文本长度少于五个字符;图像小于5KB的的样本;关键字带有NSFW的……几周之内,他们就拥有了300万对图文对。
数据集发布之后就收到了各种反响,被用于诸多论文和实验。其中最具代表性的,就是Google Brain去年(2022)发布的 Imagen ——文本生成图像的扩散模型。

与此同时,更多机构开始关注到这个非盈利组织并给予资金支持。2021年他们就收到了HuggingFace的一次性捐赠。
但印象最深的一次,还要属一个对冲基金经理来到Discord聊天室。
当时他二话不说直接送钱,大概意思是:我给你们支付算力费用,没有任何附加条件。
舒曼团队对这个行为嗤之以鼻,甚至觉得他是个疯子:
一开始我们非常怀疑,但大概一个月后,我们获得了价值近1万美元的云计算服务。
后来,这个所谓的“疯子”创办了Stability AI,使用LAION数据集推出了 Stable Diffusion ,引领了生成式AI的浪潮,顺便还拐走了LAION组织的两个研究人员。
如今Stability AI正在寻求40亿美元(折合276亿元)估值,这主要归功于LAION提供的数据。
据彭博社消息,舒曼却并没有从LAION中获利,原因很简单: 不感兴趣,希望保持这份工作的独立性 。
因此他还婉拒了各类工作邀请,依旧选择在德国汉堡当一名普普通通的高中老师。
本人:数据集不应该被监控
即便如此,随着LAION知名度打响,他还是避免不了地卷入到各种纷扰之中。
目前,LAION已经发布了10项数据集,最具代表性的就是去年3月发布的LAION-5B,由58.5亿个图像文本组成,是当前最大的免费开源数据集。
作为LAION-400M的继任者,它收到了来自HuggingFace、Stability AI以及Doodlebot资助。
结果一发布就遭到了不小的争议,网友们纷纷质疑其数据未经整理,导致充斥大量的非法内容,对此LAION工程师Romain Beaumont回应:
非标注数据集是自我监督学习的基础,这是机器学习的未来。没有人工标注的图像/文本是一项功能,而非错误。
早在Imagen发布时,也专门针对LAION-400M做出警示:因为依赖于这种未经整理的网络数据, 集成了大模型的社会偏见和限制,因此不适合公开使用。

据彭博社消息,为了打造LAION,舒曼团队从亚马逊网络服务、Shopify等公司获取视觉数据,还有包括YouTube缩略图、各类新闻网站上的内容。
对此舒曼表示, 任何在网上免费提供的东西都是公平竞争 ,欧盟也没有人工智能法规。
更何况,也没有人知道OpenAI实际上用什么样的数据集训练AI的。
目前,LAION被迫卷入两场诉讼之中,一起是Stability AI与Midjourney等集体诉讼,被指使用艺术家的版权图片来训练他们的模型;
另一起是Getty Images起诉Stability AI,称其1200万张照片被LAION取走,并用来训练Stable Diffusion。
而舒曼将LAION比作大信息技术海啸之上一艘“小型研究船”,采取海下的样本向世界展示。
其实早在构建数据库时,他们就在运行一个自动化过滤工具,不过舒曼感兴趣的不是清理,而是从这些资产中学习。
我们本可以从公布的数据中过滤掉暴力,但我们决定不这样做,因为这将加快暴力检测软件的开发。
现在更多关于监管的建议在推动,各个科技大厂也在采取相应的措施,比如英伟达就开源了护栏工具,来防止大模型来胡说八道。
但在舒曼看来, 数据集不应该被监控。 这也正是当时创建LAION时候的初心。
他还警告,如果我们试图放慢速度、过度监管,就会有很大的危险,最终只有少数大公司能负担得起所有的正式要求。
前段时间,在LAION与全球志愿者的合力之下,他们完成了ChatGPT最大开源平替 OpenAssistant 的发布。
60万余条训练数据全部由人工生成,涵盖了广泛的话题和语言风格,一时间引发众人关注,HuggingFace也直接拿来用来构建它自己的聊天软件HuggingChat。
拿着德国铁饭碗
不可否认的是,他已经在用开源数据集,加剧了生成式AI的浪潮。
但在舒曼的个人网站上,看到的只是一位两个孩子的父亲,在德国当着终身制公务员,游走于中学校之间讲授物理和计算机科学。

舒曼拥有维也纳大学计算机科学与物理学学位。在学习这两个专业之前,他还学了心理学。(大概完成了50%的学士学位然后就转专业了)。
除此之外,他还在学习表演,制作了一部关于孩子学习的纪录片「Schools of Trust」。
最近,这位高中教师也没闲着,他还将作为2023年智源大会嘉宾参与邀请报告与线上论坛环节。
来源:元宇宙之心
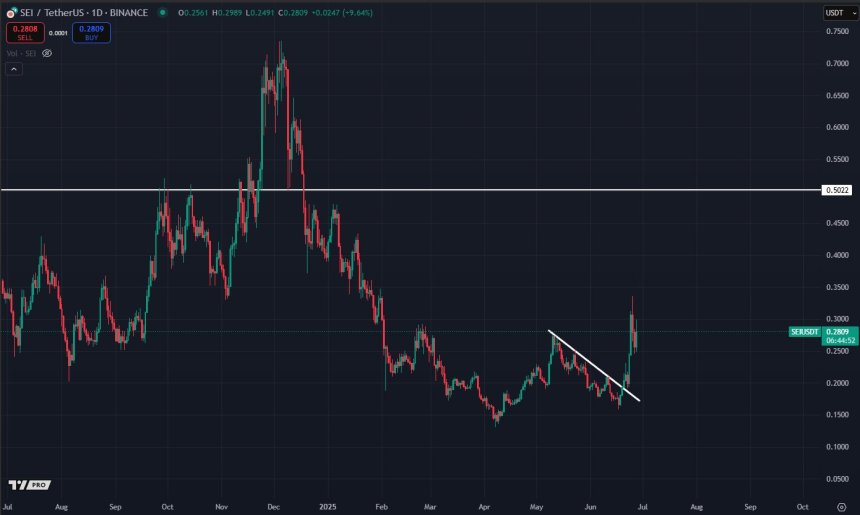
SEI Leads Crypto Market With 43% Weekly Surge – $0.5 Reclaim In The Horizon?
After breaking out of a bullish formation, SEI is attempting to reclaim a crucial level to continue ...
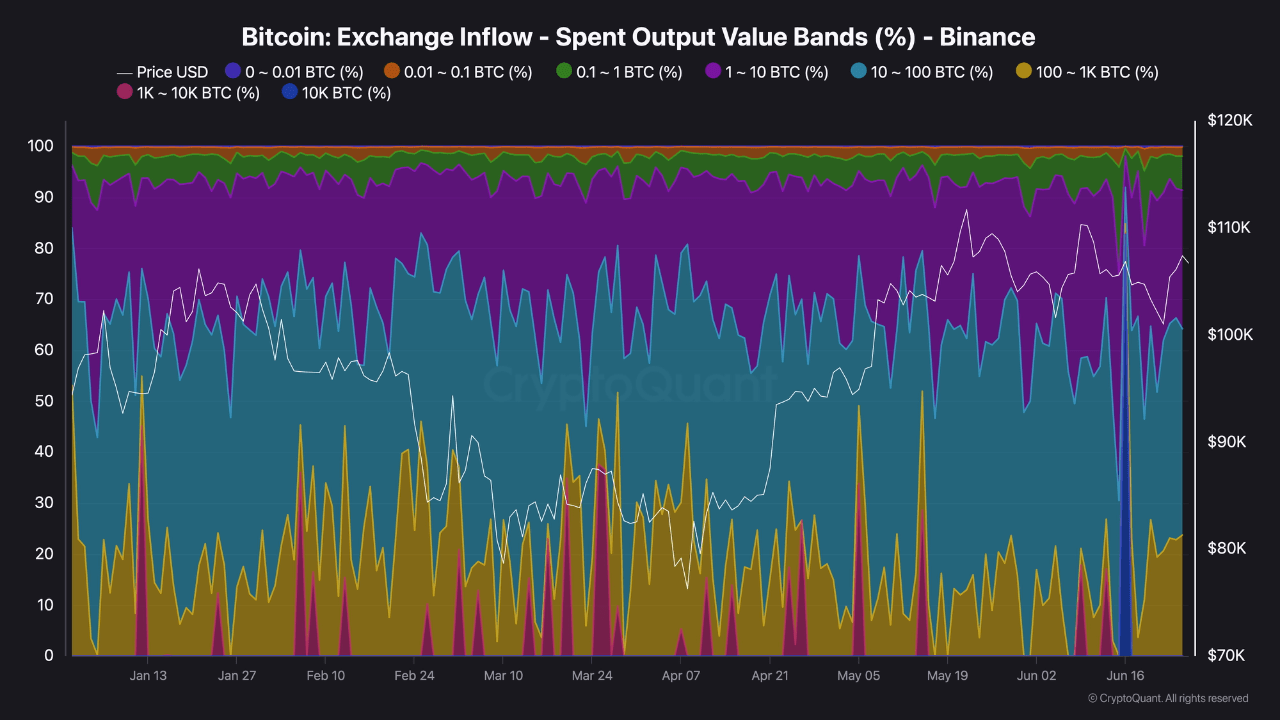
You Won’t Believe Who’s Moving Millions in Bitcoin on Binance Right Now
Bitcoin is treading cautiously below the $110,000 level, signaling a pause in momentum after recent ...

TAO Leads Top 10 Crypto Rankings by LunarCrush Galaxy Score
TAO leads LunarCrush’s top 10 coins by Galaxy Score as AI, DeFi, and tokenization projects like VOXE...