
百度被网暴,AI大模型“套皮”海外知名项目,百度首次回复:假的!




3月16日,百度创始人李彦宏做了大语言模型“文心一言”的发布会。
结果,观众只记住了白衬衫和白腰带,并且纷纷表示好奇,李彦宏保养的不错。然后感慨,Robin Li与其分享百度雄心勃勃的语言大模型,不如讲一讲如何保养,搞不好还能带个货,股价也许就上去了。
虽然,网络上键盘侠吐槽很多,但还是有很多媒体写到:《中国百度硬刚chatGPT,国产之光》。没办法,AI这个领域,好像只有百度能打,起码,大部分公众的认知是这样。
如果说16日发布会后公众的态度是希望百度扛起对线chatGPT的大旗。这两天,画风变了,吐槽排山倒海而来,可以说是怒其不争了。
首先是一批图片,显示文心一言理解能力很差。
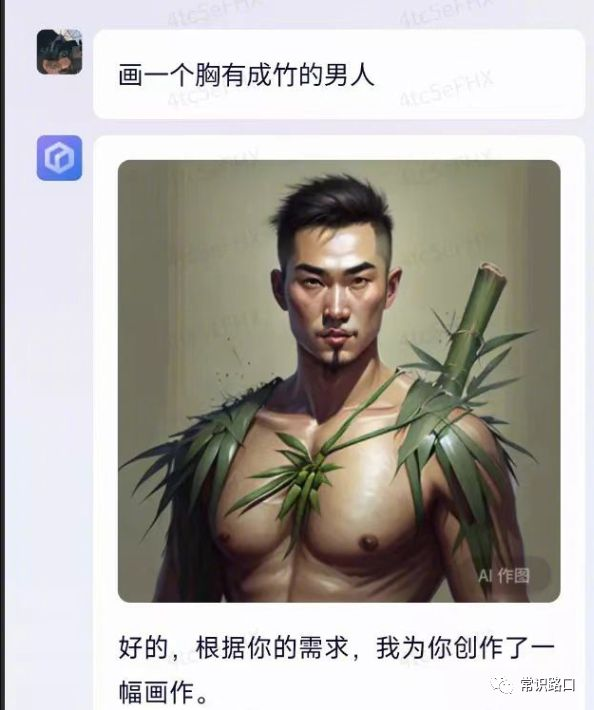
另外,还有一批图片,更是把文心一言给狠狠锤了一把。大意是说,文心一言更懂英文,不懂中文。直言百度作假,文心一言是套壳了chatGPT,水货。
那么,真的是这样子吗?
百度文心一言被爆锤,国产都不行?
微博账号“刘大可先生”锤百度的文字被传播的很广,光点赞就有2.2万。
他是这么说的:百度这个所谓的人工智能,其实就把中文句子机翻成英语单词,拿去用国外刚刚开源的人工智能“Stable Diffusion”生成了图画,再返回给你,说是自己画的。
他给出的理由有很多,这里仅举一个例子。

上图,“刘大可先生”的要求是画“云中的平面”,结果文心一言画了个飞机,“刘大可先生”说,这是因为“云中的平面”机翻之后是“plane in cloud”,所以文心一言背后的英语的人工智能当然会画个飞机。
下面这张图在社交网络传播非常广,揭示的“真相”与上文是一样的。
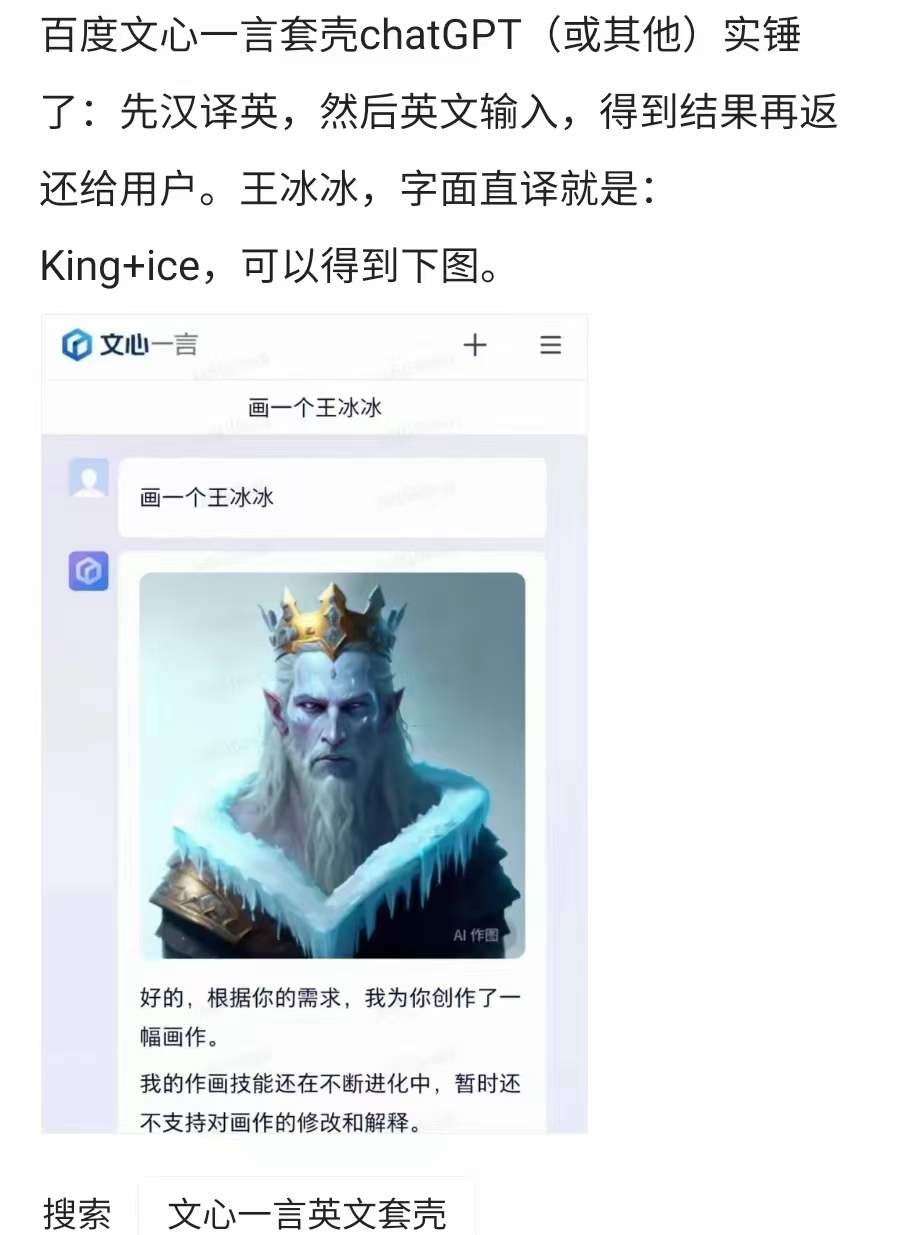
自从chatGPT诞生后,以及包括一系列AI画图软件,像Stable-Diffusion、Midjourney、DALLE等诞生以来,我们其实看到了很多的应用,底层都是这些开源的模型。但是通过“汉化”,可以给中国的用户带来很好的体验。
百度的文心一言是不是也这样?这个“判断”可能是武断的。
2月20日晚间,复旦大学邱锡鹏教授团队发布国内首个类ChatGPT模型MOSS,但是很快就被吐槽,它的中文水平不如英文。
3月30日,阿里达摩院低调地在魔搭社区(ModelScope)放出了“文本生成视频大模型”。结果,这个大模型也是更懂英文,有体验者写到,他输入提示词:A panda eating bamboo on a rock。77秒后,大模型给出了一个2秒的熊猫吃竹子视频。如果换成中文:一只大熊猫坐在岩石上吃竹子。出来的结果就是一只类似于猫咪的小动物。离题万里。
中文数据天生缺陷?
为什么会这样呢?
在微博账号“刘大可先生”爆锤百度的微博文字下面,第一个留言的名叫“欧阳少悭",他说,文心一言出现这种情况的因为在于,目前开源的图文数据大部分是英文的,可以参考LAION这个开源数据库,所以目前的diffusion model基本都是英文驱动,这也导致了“刘大可先生”说的怪异现象。
“当然,我们期待同等规模的中文开源数据库的出现。stable diffusion是一种网络结构,开发者完全可以使用LAION数据集和sd结构训练一个自己的网络,无需要套皮。”他说。
23日中午,百度官方公众号发了一则声明,写到:“文心一言完全是百度自研的大语言模型,文生图能力来自文心跨模态大模型ERNIE-ViLG。在大模型训练中,我们使用的是全球互联网公开数据,符合行业惯例。大家也会从接下来文生图能力的快速调优迭代,看到百度的自研实力。”

有从业者称,这基本等于承认使用了LAION。LAION,这是目前最为知名的大规模图文多模态数据集。作为一个非营利性组织,LAION提供数据集、工具和模型来解放机器学习研究。官网写到:我们通过这样做,鼓励开放的公共教育,并通过重用现有数据集和模型来更环保地使用资源。

从这个角度理解,说文心一言“套皮”或许还是比较武断的。到底是不是“套皮”,或者百度的语言大模型在技术上有没有参考海外项目?我们还要等待更多的来自行业的披露信息。
但是,这个事情从侧面肯定能说明一个问题,虽然,我们一直强调中国有海量的数据,但企业的实践却表明:不好用。
复旦MOSS大模型被质疑中文水平不如英文时,MOSS研究团队就坦承,“MOSS的英文回答水平比中文高,因为它的模型基座学习了3000多亿个英文单词,中文词语只学了约300亿个。”
而澎湃新闻采访了粤港澳大湾区数字经济研究院(IDEA)认知计算与自然语言中心文本生成算法团队负责人王昊,他说:“数据质量的差别是主要瓶颈之一。相较于英文数据,中文数据的开源程度较低,导致中文数据集的规模相对较小。此外,英文作为科研主流语言,在学术界和工业界中得到广泛应用,积累了大量高质量的语料数据,这为英文自然语言处理的研究提供了极大的优势。”
有一个数据很现实:虽然简体中文互联网用户和英文互联网用户规模相当,但在全球排名前1000万个网站中,英文内容占比60.4%,中文内容占比仅为1.4%。
这会是中国企业探索大语言模型的问题和瓶颈吗?可能也不是。或是观念,尤其是意识形态的阻碍更大。
中关村新场景MA Club发起人檀林在一次分享中质问:“做一个中国的大语言模型,自己给自己砌一道墙,和全球分开。就像做一个纯中文的操作系统一样,能有多大的意义?大家都知道,简体中文的数据质量很差,语料库的知识含量和价值已经比海外的几个大语言模型要低得多了,所以如果现在还非要给自己一个束缚的话,我觉得这种态度在开局就输了。”
中国企业要想在大语言模型的赛道分一杯羹,蹚出一条路,使用英文数据是不得已,没办法。当然,我们显然更期待中文数据领域能有更好的发展。

HongKong’s Bold Step: HKMA’s New Initiative to Boost DLT Adoption in Banking
The post HongKong’s Bold Step: HKMA’s New Initiative to Boost DLT Adoption in Banking appeared first...

Pongo: The XRP Trench Warrior Accelerates XRPL Adoption with MEXC Listing
The post Pongo: The XRP Trench Warrior Accelerates XRPL Adoption with MEXC Listing appeared first on...
Bitcoin Faces Mixed Signals: Institutional Investors Accumulate Amid Retail Weakness
Bitcoin has experienced notable price volatility since the start of the year, with its performance s...