ChatGPT 算力消耗惊人,能烧得起的中国公司寥寥无几



作者:吴俊宇 编辑:谢丽容

图片来源:由无界 AI 生成
高性能GPU数量或性能不够的结果是,AI推理和模型训练的准确度不足,即使做出类似的对话机器人,机器人的“智商”也会远低于ChatGPT。
国内云厂商高性能GPU芯片缺货,正在成为限制中国生成式AI诞生的最直接因素。
2022年12月,微软投资的AI创业公司OpenAI推出了聊天机器人ChatGPT。这是生成式AI在文本领域的实际应用。所谓生成式AI,是指依靠AI大模型和AI算力训练生成内容。ChatGPT本质是OpenAI自主研发的GPT-3.5语言大模型。该大模型包含近1800亿个参数。
微软的Azure云服务为ChatGPT构建了超过1万枚英伟达A100 GPU芯片的AI计算集群。
美国市场研究机构TrendForce在3月1日的报告中测算称,处理1800亿个参数的GPT-3.5大模型,需要的GPU芯片数量高达2万枚。未来GPT大模型商业化所需的GPU 芯片数量甚至超过3万枚。更早前的2022年11月,英伟达在官网公告中提到,微软Azure上部署了数万枚A100/H100高性能芯片。这是第一个采用英伟达高端GPU构建的大规模AI算力集群。
鉴于英伟达在高性能GPU方面的技术领先实力,在国内,云计算技术人士公认的一个说法是,1万枚英伟达A100芯片是做好AI大模型的算力门槛。
《财经十一人》了解到,目前国内云厂商拥有的GPU主要是英伟达中低性能产品(如英伟达A10)。拥有超过1万枚GPU的企业不超过5家,其中拥有1万枚英伟达A100芯片的企业最多只有1家。也就是说,单是从算力这个衡量指标来看,国内能在短期内布局类似ChatGPT的选手十分有限。
ChatGPT看似只是聊天机器人,但这却是微软的AI算力、AI大模型和生成式AI在消费市场的一次肌肉展示。 在企业市场,这是云计算的新一轮增长点。微软Azure ML(深度学习服务)已有200多家客户,包括制药公司拜耳、审计公司毕马威。Azure ML连续四个季度收入增长超过100%。这是微软云旗下云、软件、AI三大业务中增长最快的板块。
今年2月,包括阿里、百度等中国企业宣布将研发类ChatGPT产品,或将投入生成式AI的研发。在国内,AI算力、AI大模型和生成式AI被认为只有云厂商才有资格下场。华为、阿里、腾讯、字节跳动、百度都有云业务,理论上有跑通AI算力、AI大模型和生成式AI应用的入场券。
有入场券不代表能跑到终点。这需要长期高成本投入。GPU芯片价格公开,算力成本容易衡量。大模型需要数据采集、人工标注、模型训练,这些软性成本难以简单计算。生成式AI的投资规模通常高达百亿元。
多位云计算厂商技术人士、服务器厂商人士对《财经十一人》表示,高性能GPU芯片短缺,硬件采购成本、运营成本高昂,国内市场中短期商业化困难,这三个问题才是真正的挑战。他个人认为,具备资金储备、战略意志和实际能力的企业,暂时不会超过3家。
芯片数量决定“智商”
决定AI大模型“智商”的核心因素是三个,算力规模、算法模型的精巧度、数据的质量和数量。
AI大模型的推理、训练高度依赖英伟达的GPU芯片。缺少芯片会导致算力不足。算力不足意味着无法处理庞大的模型和数据量。最终的结果是,AI存在智商差距。
3月5日,第十四届全国人民代表大会第一次会议开幕式结束后,科技部部长王志刚在全国两会“部长通道”接受媒体采访时评价,ChatGPT作为一个大模型,有效结合了大数据、大算力、强算法。它的计算方法有进步,特别是在保证算法的实时性与算法质量的有效性上。“就像发动机,大家都能做出发动机,但质量是有不同的。踢足球都是盘带、射门,但是要做到梅西那么好也不容易。”
英伟达是全球知名的半导体厂商,在数据中心GPU市场占据超过90%以上的份额。英伟达A100芯片2020年上市,专用于自动驾驶、高端制造、医疗制药等AI推理或训练场景。2022年英伟达推出了性能更强的新一代产品H100。A100/H100是目前性能最强的数据中心专用GPU,市面上几乎没有可规模替代的方案。包括特斯拉、Facebook在内的企业,都利用A100芯片组建了AI计算集群,采购规模均超过7000枚。
多位云计算技术人士对《财经十一人》表示,运行ChatGPT至少需要1万枚英伟达的A100芯片。然而, GPU芯片持有量超过1万枚的企业不超过5家。其中,拥有1万枚英伟达A100 GPU的企业至多只有1家。
另有某大型服务器厂商人士对《财经十一人》表示,即使乐观估计,GPU储备规模最大的企业也不超过5万枚,且以英伟达中低端数据中心芯片(如英伟达A10)为主。这些GPU芯片分散在不同数据中心中,单个数据中心通常只配备了数千枚GPU芯片。
此外,由于美国政府去年8月开始实施的贸易限制,中国企业早已无法获取英伟达A100芯片。现有A100芯片储备均是存货,剩余使用寿命约为4年-6年。
2022年8月31日,英伟达、AMD两家半导体企业旗下生产的GPU产品被美国列入限制范围。英伟达被限制的产品包括A100和H100,AMD受管制GPU产品包括MI250。按照美国政府的要求,未来峰值性能等于或超过A100的GPU产品也被限制出售。
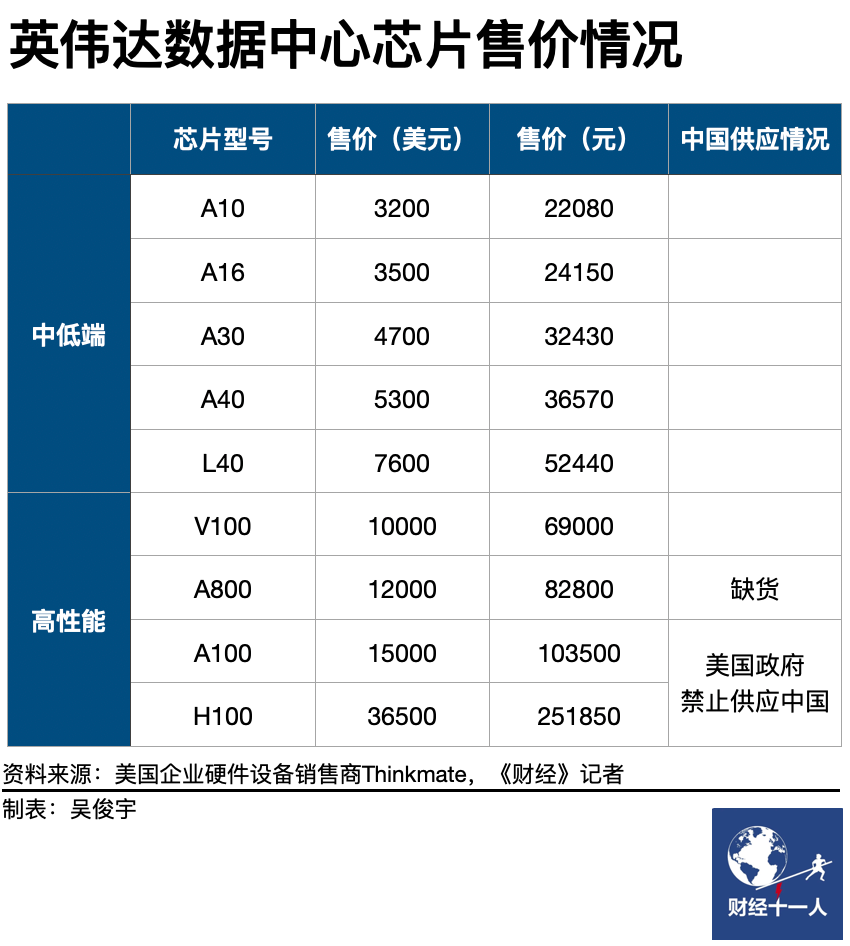
中国企业目前能够获取的最佳替代品,是英伟达的A800芯片。A800被视为是A100的“阉割版”。2022年8月,A100被禁止销售中国市场后,英伟达在当年三季度针对中国市场推出了特供的A800芯片。 该产品计算性能与A100基本相同,但数据传输速度被降低了30%。这会直接影响AI集群的训练速度和效果。
不过,A800芯片目前在中国市场也严重缺货。虽然是A100“阉割版”,A800京东官网定价超过8万元/枚,甚至超过A100官方定价(1万美元/枚)。即使如此,A800在京东官网仍是缺货状态。
有云厂商人士对《财经十一人》表示,A800实际售价甚至高于10万元/枚,价格还在持续上涨。A800目前在浪潮、新华三等国内服务器厂商手中是稀缺品,一次只能采购数百片。
GPU数量不够或性能不够的结果是,AI推理和模型训练的准确度不足。这会直接导致中国企业即使做出类似的对话机器人,机器人的“智商”会远低于ChatGPT。国内云厂商高性能GPU芯片缺货,正在成为限制中国版ChatGPT诞生的最直接因素。
成本高昂
AI算力和大模型是比云还要烧钱的吞金兽。
即使有足量的高性能GPU,中国云厂商接下来还要面临高昂的硬件采购成本、模型训练成本以及日常运营成本。面对上述成本,具备资金储备、战略选择和实际能力的企业不超过三家。
OpenAI能做出ChatGPT,背后有微软提供资金和算力。2019年微软向OpenAI投资10亿美元。2021年微软再进行了一轮未透露金额的投资。今年1月,微软宣布将在未来数年陆续向OpenAI投资100亿美元。
对云厂商来说,AI算力和大模型需要面临高昂的硬件采购成本、模型训练成本以及日常运营成本。
其一,硬件采购成本和智算集群建设成本。 如果以1万枚英伟达A800 GPU为标准构建智能算力集群,在10万元/枚的价格标准下,仅GPU采购成本就高达10亿元。一台服务器通常需要4枚-8枚GPU,一台搭载A800的服务器成本超过40万元。国内服务器均价为4万-5万元。一台GPU服务器的成本是普通服务器的10倍以上。服务器采购成本通常是数据中心建设成本的30%,一个智算集群的建设成本超过30亿元。
其二,模型训练成本。想要算法模型足够精准,需要进行多轮算法模型训练。 有某外资云厂商的资深技术人士对《财经十一人》表示,ChatGPT一次完整的模型训练成本超过1200万美元(约合8000万元)。如果进行10次完整的模型训练,成本便高达8亿元。GPU芯片价格公开,算力成本相对容易衡量。但AI大模型还需要数据采集、人工标注、模型训练等一系列工作,这些软性成本难以简单计算。不同效果的模型最终成本也不同。
其三,日常运营成本。 数据中心内的模型训练需要消耗网络带宽、电力资源。此外,模型训练还需要算法工程师负责调教。上述成本也以亿元为单位计算。
也就是说,进入AI算力和AI大模型的赛道,前期硬件采购、集群建设成本就高达数十亿元。后期模型训练、日常运营以及产品研发成本同样高达数十亿元。一家管理咨询公司技术战略合伙人对《财经十一人》表示,生成式AI的投资规模高达百亿元。
微软大规模采购GPU组建智算集群,这在商业逻辑上行得通。 2022年微软在云计算基础设施的支出超过250亿美元,当年微软营业利润828亿美元,微软云营业利润就超过400亿美元。 仅微软云利润大于支出,大规模投资AI算力、大模型业务,这与微软的财务现状是相匹配的。
微软的AI计算有产品、有客户、有收入,形成了新的增长点。微软的客户通常会在云上租赁数千枚高性能GPU,进行语言模型学习,以此使用自己的启用生成式 AI。
微软旗下包括Azure ML和OpenAI。Azure ML有200多家客户,包括制药公司拜耳、审计公司毕马威。Azure ML连续四个季度收入增长超过100%。微软云甚至已经形成了“云-企业软件-AI计算”三条轮动增长的曲线。其中公有云Azure营收增速约为30%-40%,软件业务营收增速约为50%-60%,AI算力营收增速超过100%。
中国企业用于云基础设施的资本支出有限,投资智算集群、AI大模型需要从有限的预算中分走支出。更大的挑战是,中短期内不仅无法盈利,还要亏更多钱。
科技公司的资本支出通常被用于采购服务器、建设数据中心、购置园区土地等固定资产。以亚马逊为例,2022年资本支出580亿美元,超过50%用于投资云基础设施。《财经十一人》查阅阿里、腾讯、百度最近一个财年的资本支出发现,三家数据分别为533亿元、622亿元、112亿元。
三家均未披露用于投资云基础设施的资本支出情况。假设三家企业与亚马逊相同,50%的资本支出用于投资云基础设施,数据分别为266亿元、311亿元、56亿元。投资数十亿元对资本支出宽裕的企业来说可以承受,但对资本支出不足的企业来说,则是负担。
国内宣布已建设智算集群的企业包括阿里云、华为、百度,但智算集群内GPU芯片数量不详。2022年,主要云厂商均把提高毛利、减少亏损作为战略重点。在这个阶段采购高性能GPU、建设智算集群需要巨额投入。不仅会加剧亏损,还需要依赖集团输血。这将考验企业管理层的战略意志。
大模型没条件,先做小模型
华为、阿里、腾讯、字节跳动、百度都有云业务,理论上有做出中国版ChatGPT的入场券。
有云计算技术人士评价,有入场券的几家企业也会有实际的战略考量。比如,腾讯、百度、字节跳动有云也有大量数据,但云业务在亏损,长期投入的资金储备、战略意志存疑。华为靠自研昇腾芯片建立了大模型技术,但因“断供”影响无法获得英伟达的GPU芯片,而且作为硬件厂商缺少互联网公司的数据积累。
由于上述限制,能实现AI大模型商业化的企业少之又少。最终同时具备资金储备、战略意志和实际能力的企业将聊聊无几。
目前,没有一家中国云厂商像微软一样拥有数万枚A100/H100芯片。中国云厂商的高性能GPU算力目前暂时不足。一种更务实的观点是,中国云厂商即使真的获取1万枚英伟达高性能GPU后,也不应该简单投入到中国版ChatGPT这种大众的消费场景。
算力资源稀缺时,优先考虑是投入行业市场,为企业客户提供服务。一家管理咨询公司技术战略合伙人对《财经十一人》表示,ChatGPT只是对话机器人,商业应用场景展示暂时有限。用户规模越大,成本也就越高,带来的亏损也会越大。AI算力和大模型如何在细分领域实现商业化,获取正向现金流才是关键。
中国市场的AI算力、大模型的商业化尚处于起步期。目前国内自动驾驶、金融等领域的少数客户开始采用AI算力。比如,小鹏汽车目前已经采用阿里云的智算中心进行自动驾驶的模型训练。
有数据中心产品经理对《财经十一人》表示,国内银行金融客户反欺诈已经大量运用模型训练技术,通常只需要租赁使用数百枚性能更低的GPU调教模型。同样是AI计算和模型训练,这是更低成本的解决方案。事实上,通用大模型无法解决行业具体问题,无论是金融、汽车、消费等各个领域都需要行业模型。
中国暂时没有足够的高性能GPU做大规模AI模型训练,可以先在细分领域做小模型。AI技术发展之快速超越了人们的认知,对中国公司来说,持续布局战略性发力才是根本之道。
TRON Surges Past 8 Million Daily Transactions as TRX Holds Above $0.27
TRON (TRX) has experienced relatively stable price movement over the past week, fluctuating within a...

INTO Commences Partnership with Dragonfly to Broaden Web3 Accessibility
The partnership with Dragonfly permits the platform to fulfill its objective by integrating unique r...

Elon Musk vs Donald Trump: What Led To a Billion-Dollar Fallout?
The post Elon Musk vs Donald Trump: What Led To a Billion-Dollar Fallout? appeared first on Coinpedi...