全球生成式 AI,不仅仅只有 ChatGPT



日前,看到一个关于爆火的 ChatGPT 的笑话:在一个充满一线投资基金与顶尖 AI 创业者的微信群,谈论着日益火爆的 ChatGPT , 因为 OpenAPI 也有开放 API , 所以,以简单粗暴的方式,就可以集成类 ChatGPT 的聊天机器人。而且的确不少人已经这么干了,并收取XXX元的年费。而同时,考虑到微信的敏感内容审查机制,所以一个开发者往往要申请好多个微信号,以做好随时被封号的准备。加上国内跟风速度之快,所以一个大胆的预测是,很快将在国内市场看到 类聊天机器人应用数目超过使用者数目的奇观。但愿这只是一个笑话。
其实,全球生成式 AI ,不仅仅只有 ChatGPT 。为此,炫氪特转发一篇深耕该领域的创业团队的一篇观点文章,以飨读者。
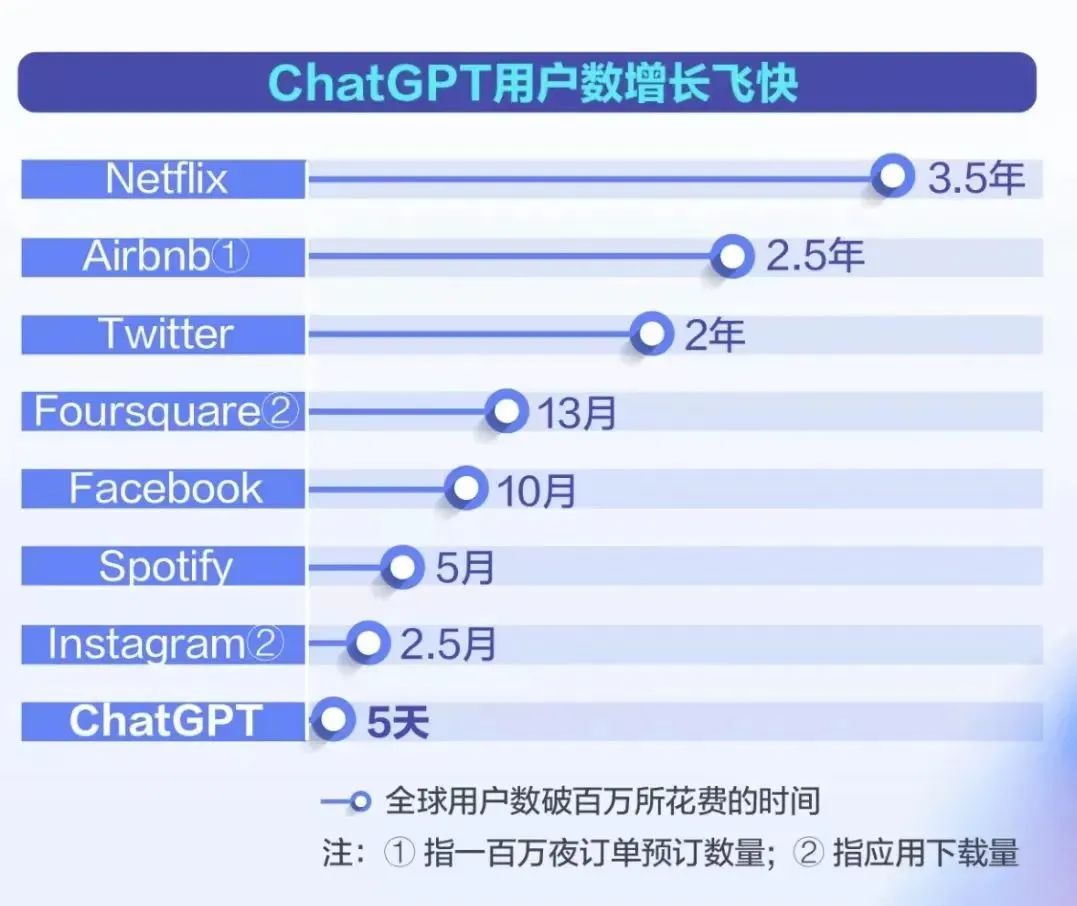
生成式 AI 飞速的发展,正在扭曲我们对时间的感知。你能相信 Stable Diffusion 发布才不到半年的时间,ChatGPT 成为历史上在最短时间内用户量级达100万的应用吗?更可怕的是两个月余的时间,月活跃用户数预计已达1亿!你稍微不留神,可能几天内就会错过 AI 行业很多的新发展!
图源 | 网络
回顾2022年的 AI 格局,正是由生成式 AI 的大模型(foundation models)所驱动。这些大模型正在迅速地从研究实验室走出来,扑向真实世界的各个场景与应用,2023年影响的层面会更大,发展的速度会更快。另外两个由大型语言模型(LLM, large language model)技术驱动的新兴领域,则是帮助人做决策的 AI 代理(游戏,机器人等), 以及应用在科学领域的 AI for Science。
Vitally AI 团队一直广泛地关注 Generative AI,因此我们总结了全球范围内的16点观察与您分享。
01 Text-to-image 前驱者
DALLE-2
DALLE-2 是扩散模型(Diffusion Model)比较具代表性的大模型之一,也是由 OpenAI 公司所开发的,能根据文本生成逼真的高分辨率的高质量图像,用于图像生成。它是基于原先 DALL-E (原先用的是 GLIDE 模型)的版本来改进,具有更高的生成质量和更大的模型尺寸,推动 AI 在全球的艺术革命。
DALLE-2 的核心主要包括 CLIP 模型 和 Diffusion 模型;CLIP(Contrastive Language-Image Pre-training)是通过将文本与图像进行对比的预训练大模型,学习文本与图像之间的关系,而 Diffusion 负责听 CLIP 的引导生产图片。
DALLE-2 目前还是闭源的,用户可以通过它的 WEB 界面或 API 来使用它。

图源 | OpenAI 官网
02 开源的 Stable Diffusion
横空出世
继 DALLE-2 之后继续颠覆艺术革命、也引起技术界轰动的 Stable Diffusion(文中简称 SD),是一个基于 Latent Diffusion Models(潜在扩散模型)来实现文字转图片的大模型,类似 DALLE-2 和谷歌的 Imagen 等类似技术,SD 可以在短短几秒钟内生成清晰度高,还原度佳、风格选择较广的 AI 图片,这让 SD 在同类技术中脱颖而出。
SD 最大的突破是任何人都能免费下载并使用其开源代码,因为模型大小只有几个G而已!因此在短时间内 huggingface 网站上有100万次模型的下载,也是破了 huggingface 网站的历史记录。这让 AI 图片生成模型不再只是业内少数公司自我标榜技术能力的玩物,许多创业公司和研究室正在快速进入,集成 SD 模型来开发各种不同场景的应用,包括我们 Vitally AI 公司。
SD 以掩耳盗铃之势迅速迭代,开源社区也在不断改进 SD。在 SD v2.0 上线不到两周的时间,就迅速更新到 v2.1 版本。相比于前一版本,主要放宽了内容过滤的限制,减少了训练的误伤,也有这三大特色:图片质量更高、图像有了景深、负向文本的技巧更好地约束 AI 生成的随机性,也支持在单个 GPU 上运行。


图源 | Stable Diffusion官网
SD 官网上写着 “by the people, for the people” 的使命,与热烈追求民主化的开源,已被证明是改写了 AI 赛道的游戏规则,同时也让 Stability AI 公司在不到两年的时间内迅速变成独角兽公司,快速融资了1亿美金。高质量!免费开源!更新快!这几个关键词就已经决定了 Stable Diffusion 的出世必定绝不平凡!借助这一突破性技术尝试给你的宠物照片变个身吧!?
图源 | 网络
Vitally AI 公司的产品底层就集成了 SD 的各个版本模型,虽然做成应用,我们在模型底层和产品应用中间层还是要做非常多的工作,不过 Vitally 非常看好 Stability AI 这家公司, 也期待他们下一步能继续惊世骇俗。
03 谷歌两个未开源
Text-to-image 扩散模型
2022年 Google AI 还有2个 Image-to-text 模型。Imagen 和 Parti 分别是扩散模型(Diffusion Model)和自回归模型(Auto-regression model),两者不同但互补,代表了谷歌的两个不同的探索方向,模型都没有开源或可以集成的 API ,所以 Vitally 团队无法动手研究,但论文仍富有有趣的见解。不管这些大模型再怎么厉害,对 Vitally AI 这样做产品应用的公司而言,“只能仰望和远观,不能亵玩焉”。
Imagen大模型网址:
imagen.research.google

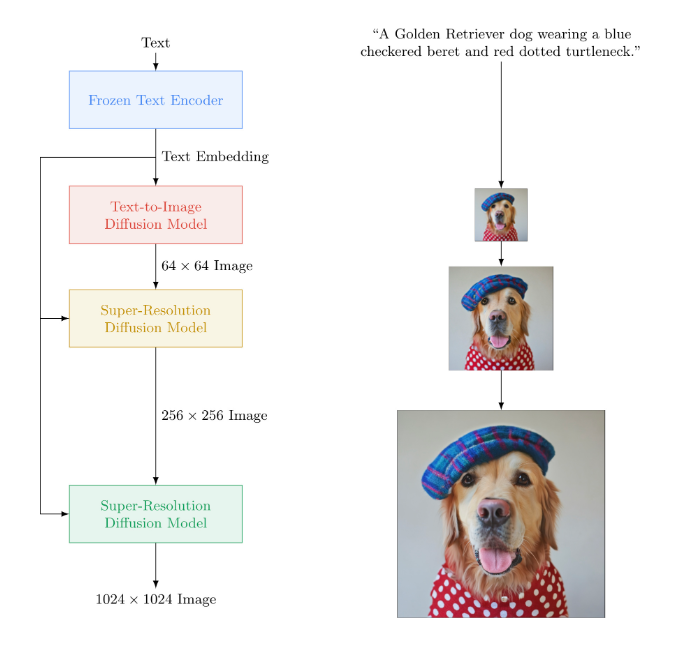
Imagen 不同于其他已知的文本出图的大模型,其更注重深层次的语言理解。Imagen 的预训练语言模型(T5-XXL)的训练集包含800 GB的纯文本语料,在文本理解能力上会比有限图文训练的效果更强。Imagen 的工作流程为:在输入 prompt 后,如“一只戴着蓝色格子贝雷帽和红色波点高领毛衣的金毛犬”(A golden retriever dog wearing a blue checkered beret and red dotted turtleneck),Imagen 先使用谷歌自研的 T5-XXL 编码器将输入文本编码为嵌入,再利用一系列扩散模型,从分辨率 64×64 → 256×256 → 1024×1024 的过程来生成图片。结果表明,预训练大语言模型和多联扩散模型在生成高保真图片方面效果很好。
Parti 大模型网址: parti.research.google

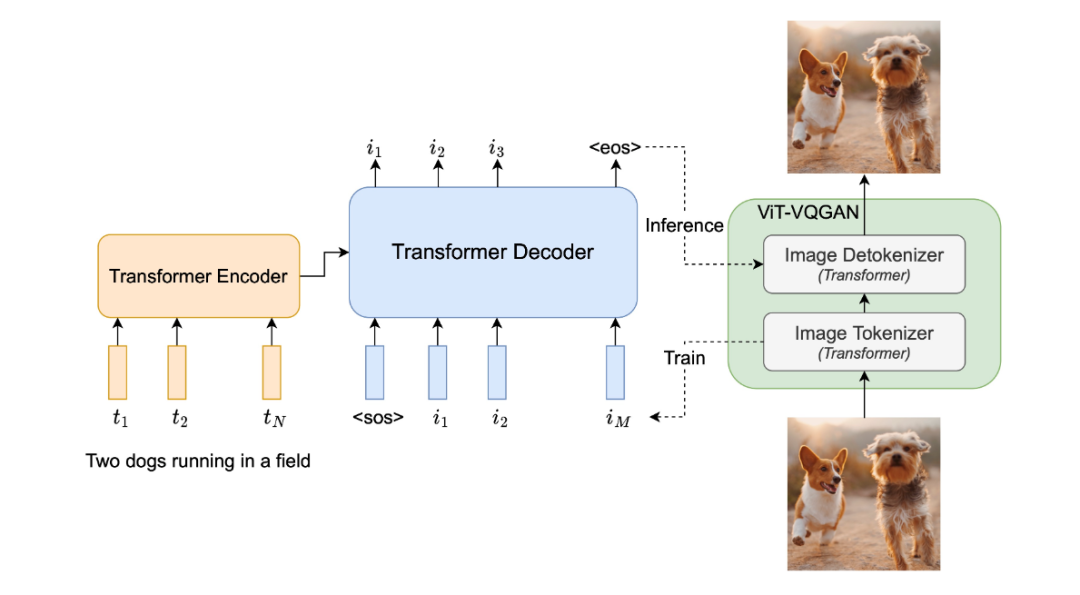
Parti 是一种自回归文本生成图片模型(Pathways Auto-regressive Text-to-Image model),其将文本到图片的生成视为序列到序列的建模问题,类似于机器翻译,这使其受益于大语言模型的进步。在输出图片 token 序列后,Parti 使用图像标记器 ViT-VQGAN 将图片编码为离散 token 序列,并利用其重建图片 token 序列的能力,使其成为高质量、视觉多样化的图像。
04 将颠覆搜索并冲击许多领域的
ChatGPT!
ChatGPT!史上唯一5天内获得100万用户的应用,两个月时间用户量达1亿,打破上个记录保持者——用9个月时间将用户量冲上1亿的 TikTok。ChatGPT 的快速发展与日益智能的知识助理角色,挑战了像谷歌这样的传统信息搜索巨头的产品形态与商业模式。
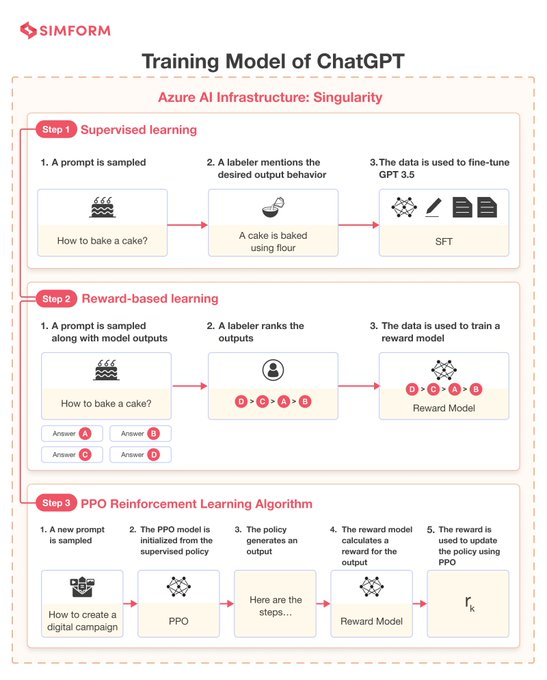
ChatGPT 让机器学习如何更好地理解人类语言,从而更好地回答问题,更好地跟人类写作,甚至进一步启发人类的创造力。本次 OpenAI 发布的 ChatGPT 是基于 GPT-3 的微调版本,即 GPT-3.5。它使用了一种新技术 RLHF(“人类反馈强化学习”)。相比 GPT-3,ChatGPT 的主要提升点在于记忆能力,可实现高度拟人化的连续对话和问答,也可以按输入的具体指令产出特定的文本格式。
图源 | Twitter
在各种社区的讨论中被总结出几十种 ChatGPT 内容产出的的场景与用例,比如:投资研究报告、工作周报、论文摘要、合同文本、招聘说明书、指定计算机语言的代码等等。ChatGPT 这个超大的话题,我们在后续微信公众号的选题规划中,会单独整理出一篇文章来总结出几十种 ChatGPT 的使用方式。
当然,ChatGPT 也有人工智障的时候,比如:对人类的知识只截止到2021年底,所以实时信息的搜索还是得借助搜索引擎;ChatGPT 数学不好;如果问它不合逻辑的问题,它会被绕晕。
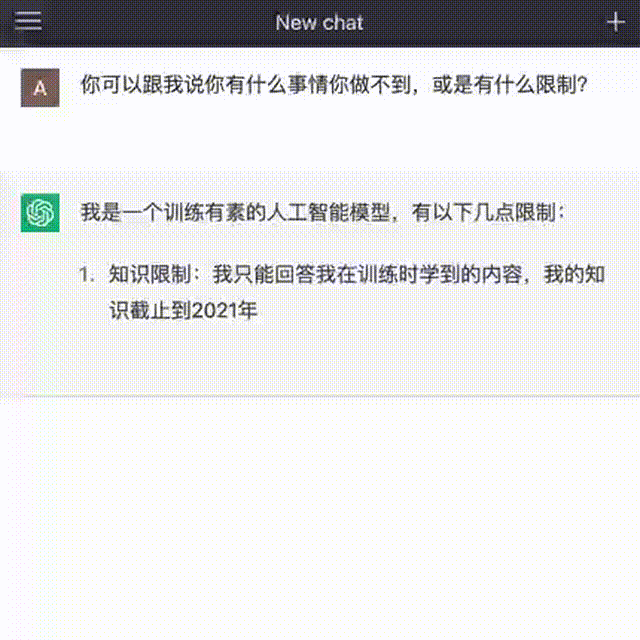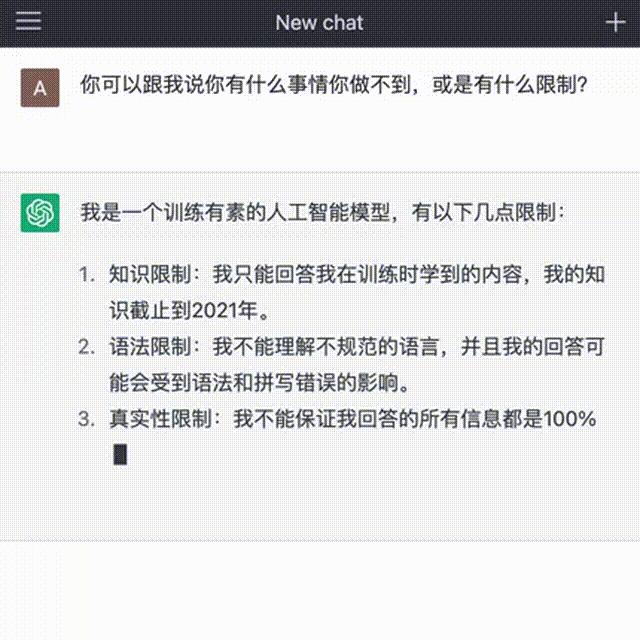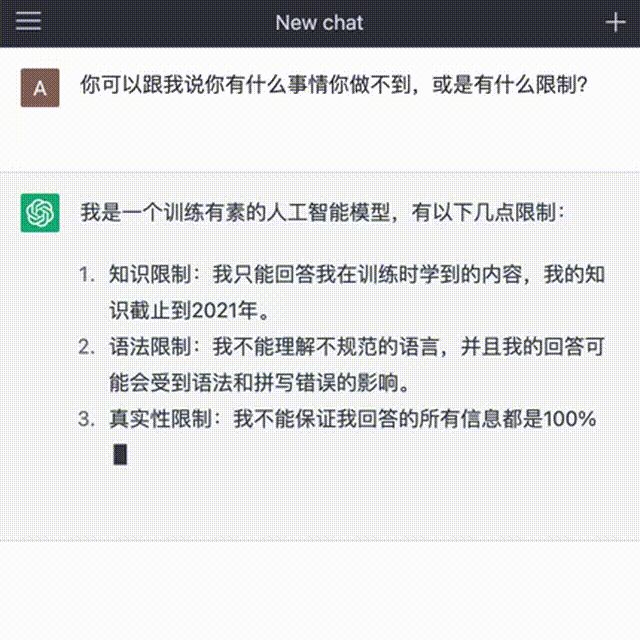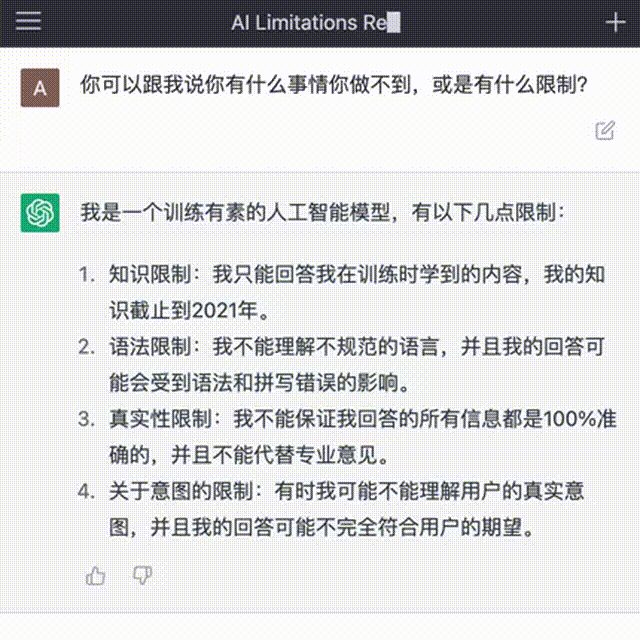
图源 | chat.openai.com/chat
目前 ChatGPT 的极致能力展现在:通过美国医疗专业执照的考试,通过美国知名商学院沃顿的 MBA 考试等,接近人的水平。某种意义上,ChatGPT 越来越像一个“真实的人”,只要算力足够强大,它与人类的互动越多,就将“成长”越快,也能具备更好的逻辑“思考”结果。只要时间足够长,人工智能的能力将持续提升和扩展。因此,也引发了学术界的抗争、与法律与伦理相关问题的诸多讨论和隐忧。
学术界反抗 ChatGPT 的力量,包括美国斯坦福团队推出 DetectGPT,阻止学生用 AI 写作业。另一个由一位华裔学生 Edward 创建的 GPTZero,用于检测文本是否由人工智能写作出来的。它使用两个指标"困惑度"和"突发性"来衡量文本的复杂度,如果 GPTZero 对文本感到困惑,则其复杂度较高,更判定可能是人工所编写的。
ChatGPT 是个超级重磅的话题,2023年对 ChatGPT 未来的揣想,我们在后续的公众号文章中来继续探讨吧~
05 用文本来驱动机器人
Text-to-robot !
如何给 GPT 手臂和腿,让它们能够清理你整洁的厨房?不像 NLP 自然语言处理的人工智能技术,机器人模型需要与物理世界互动。今年,大型的预训练模型终于开始解决机器人技术中困难的多模态问题。机器人技术中的任务规范有多种形式,如模仿一次性演示、遵循语言指示和达到视觉目标。它们通常被认为是不同的任务,由专门的模块来处理。
由英伟达等机构研发的 VIMA 用多模态的提示来表达广泛的机器人操纵任务。如此一来,它就可以用单一的模块来处理文本和视觉标记的提示,并自动输出运动动作。为了训练和评估 VIMA,他们开发了新的模拟基准,其中有数千个程序化生成的任务和60万以上专家轨迹用于模仿学习。VIMA 在模型容量和数据大小方面都实现了强大的可扩展性。在相同的训练数据下,它在最难的 zero-shot 泛化设置中优于先前的 SOTA 方法,任务成功率高达2.9倍。在训练数据减少10倍的情况下,VIMA 的表现仍然比竞争方法好2.7倍。
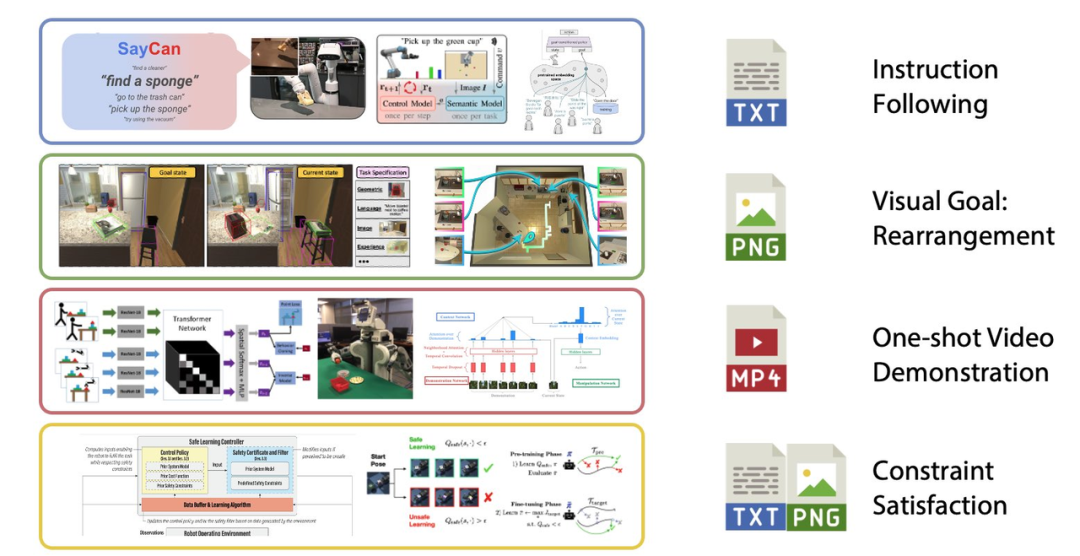
与 VIMA 类似,GoogleAI 的研究人员发布了 RT-1,一种多模态机器人变换器。它将机器人的输入和输出动作(如相机图像、任务指令和电机命令)标记化,以便在运行时进行有效的推理。RT-1 使用13个 Everyday Robots(EDR)机器人收集的数据进行训练,包括了700多项任务、13万时间片段。与之前的技术相比,RT-1 可以对新的任务、环境和物体表现出明显改善的 zero-shot 泛化能力。

06 万众期待的 Text-to-Video
在文本生成视频领域,我们想向大家介绍三款头部的研究,他们分别来自于 Meta,Google 和 Phenaki。
如果你是一名创作者,当你将文本转化成图片后,一个很自然的想法是:希望能让图片动起来,形成一个视频,从而展示更丰富的细节。Meta 公司研究的 “Make-A-Video” 中的 Text-to-Video 模型就完成了这样一件事:当输入小马在喝水时,模型就会根据文字生成一个小马喝水的视频。

使用 Text-to-Video 生成的超级英雄小狗视频截图
原视频参考:https://make-a-video.github.io/

Text-to-Video 模型采用无监督学习的方法生成视频数据集,并且通过插值网络进行调整,他的模型结构可以概括如下:
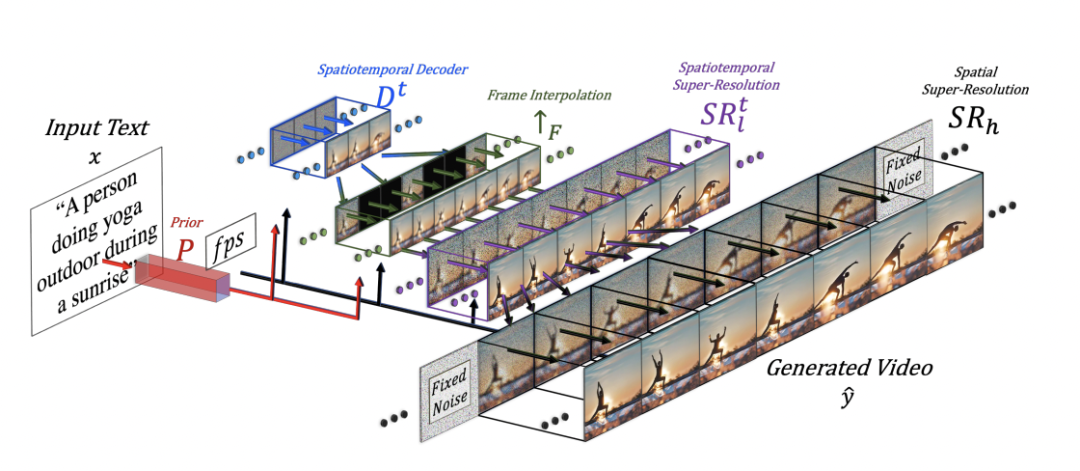
无独有偶,谷歌也发布了自己的文字生成视频的产品 Imagen Video: 基于 Video Diffusion Models(扩散模型)的视频生成模型。该模型最终生成128张图片,并在每秒内播放24张,最终形成5.8s的高清视频。

视频源 | https://imagen.research.google/video/
相关的头部模型还有 Phenaki: 使用 Causal Model(因果模型)来通过文字生成视频,他们的模型考虑了时间变量,因此可以生成任意时长的视频。
短视频是互联网巨头的必争之地,所以 Text-to-Video 的发展也备受瞩目,不过 Vitally AI 的观点是,这些巨头的技术研究不见得愿意开源出来,因为牵涉到巨大的商业利益。另外,这个领域可能也不是小创业团队的事,因为即便你有好的视频预训练大模型,视频素材的数据取得与训练,是一个成本高昂的问题。
07 Tune-A-Video 调整视频生成
Tune-A-Video 最初是由 Google 在2023年1月发表的一篇论文中提出的,展示了仅使用文本提示即可生成简单的 YouTube 视频。这是一种使用单个文本-视频对进行模型微调的文本生成视频生成方法,它是从预训练 Text-to-imae 的扩散式模型进行扩展而来的。训练过程中仅更新了注意力块中的投影矩阵。Tune-A-Video 支持在个性化的 DreamBooth 训练与模型微调,以及在 Modern Disney and Redshift 数据集上进行视频调整。
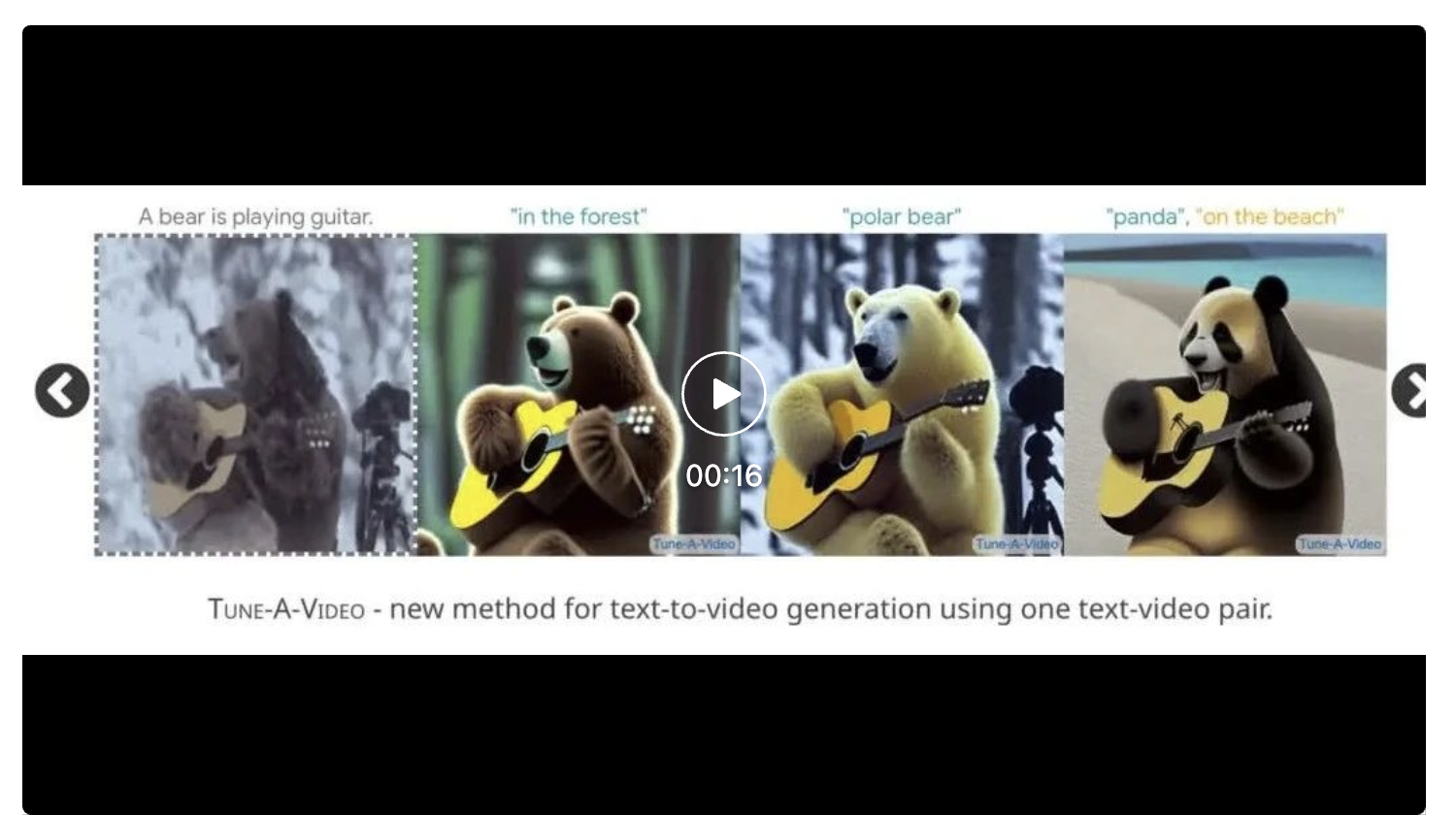
视频源 | https://tuneavideo.github.io/
这种文本到视频的生成方法最近被新加坡国立大学的 Show Lab 的研究人员进一步改进,解决了单个文本-视频对训练的问题。通过使用自定义的稀疏因果关注机制(customised Sparse-Causal Attention),Tune-A-Video 将空间自注意力(spatial self-attention)扩展到时空域(spatiotemporal domain),使用预训练的文本到图像扩散模型。

视频源 | https://tuneavideo.github.io/
08 Text-to-3D 恐怕还要再等等
从设计创新产品到电影和游戏中令人惊叹的视觉效果,3D 建模将是创意 AI 领域实现从文本到想法的下一步。2022年已经出现了几个原始但极具潜力的 3D 生成模型!
DreamFusion:Google AI 的 DreamFusion,可将文本转换为 3D 生成的图像。它将文中上述提过的文本出图 Imagen 大模型与 NeRF 的 3D 功能结合在一起,生成适用于 AR 项目或作为雕塑基础网格的质量较高的纹理 3D 模型,可以从任意角度查看,并可根据不同的照明条件重新照明。Dream Fusion AI 还可以根据生成图像模型的 2D 图像生成 3D 模型。

图源 | https://dreamfusion3d.github.io
Nvidia 英伟达公司则有两项重要的研究成果:Magic3D 和 Get3D,目标是通过允许用户从文本生成 3D 模型,使 3D 内容创建更加容易。Magic3D 是一种高分辨率的文本到 3D 内容创建方法,它采用内容从粗略到精细的渐进过程,利用低分辨率和高分辨率的扩散先验来学习目标内容的 3D 表现。据媒体报道,它比 Google 的 DreamFusion 快2倍,仅需40分钟即可创建高质量的 3D 网格模型。Get3D 是一个 AI 模型,结合了自然语言(NLP)和计算机视觉技术,用文本描述生成逼真的 3D 对象。这使用户可以快速创建逼真的 3D 模型,无需任何先前的建模技能。

上图为 Get3D 的模型演示
(来源于英伟达官网)
上图为 Magic 3D 的模型演示
(来源于英伟达官网)
Vitally AI 认为 Text-to-3D 全球都在比较早期的阶段, 因为也没有开源,所以业界无法研究和参与。我们曾经跟其他 AI 创业者交流,他们用 Diffusion Model 和 Nerf 放在一起做实验,有点样子,但是最大的障碍还是全球领域能做训练的 3D 图像数据少之又少,而用技术的方法制造 AI 训练用的数据成本也很高,我们仍需耐心等候。
09 AI 自己玩 Minecraft !?
Minecraft “我的世界”这个游戏绝对是一个完 美的通用 智能测试平台,因为:
(1)它是无限开放的,可以提供各种各样的行为动作。
(2)它具有多种类型的物理和逻辑约束。
(3)它具有许多不同的任务和目标。
2022年我们看到一些实验室和公司使用 Transformer 大模型来训练 AI 在 Minecraft 中执行各种任务的成功案例。这些大模型可以建造城堡,挖掘矿物,甚至与其他玩家交互。

图源 | Minecraft
为了利用互联网上大量可用的未标记视频数据,OpenAI 开发了一种视频预训练 (VPT) 算法。首先向游戏商家收集2,000小时的少量数据集,其数据集记录游戏视频,也记录了玩家采取的行动(按键操作和鼠标移动)。利用这些数据,训练出一个逆动力学模型(IDM)以 “预测” 视频中每个步骤所采取得动作。通过使用经过训练的 IDM 模型来标记更多的在线视频数据,并通过行为克隆来建立学习的行为。AI 通过观看 70,000 小时 YouTube 视频的大数据量就可以被训练自己玩 Minecraft。
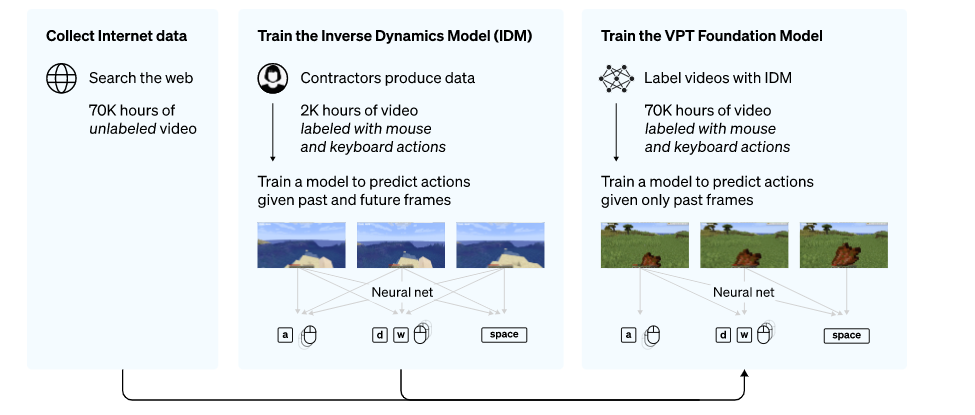
Nvidia 还开发了一个名为 MineDojo 的 AI 代理,可以根据 Minecraft 中的文字提示执行操作,并获得了国际机器学习会议的杰出论文奖。微软也有一个新的 AI Minecraft “代理”,它在游戏内运行 。
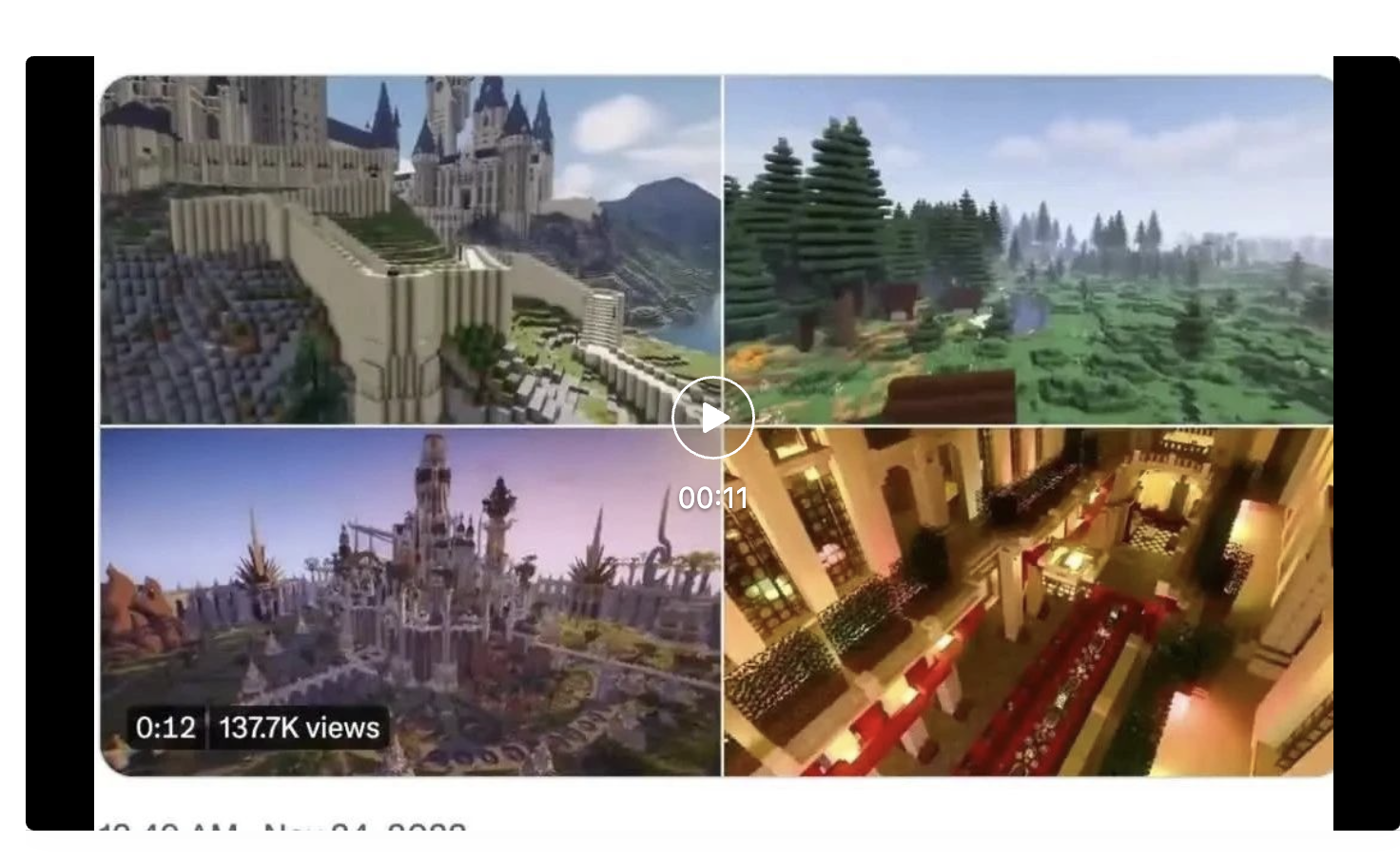
视频源 | 英伟达发表于 YouTube 视频
10 AI 发现新材料
AI 在材料科学领域的应用正在快速发展,其中 AI 发现新材料是一项重要的技术。这项技术包含了数据挖掘和机器学习两个步骤。数据挖掘通过从大量数据中提取有用信息来实现。AI 通过对数据的分析,提取有关材料性能的信息。机器学习是通过利用算法从数据中学习来实现的。在这个步骤中,AI 利用算法预测新材料的性能。这个可能更偏向 Analytical AI。
今年,GoogleAI 发布了一种名为"Material Discovery"的模型,该模型可以根据给定的物理和化学性质生成新的材料结构。这项技术有望在未来帮助材料科学家发现更高性能的材料。然而,也存在一些挑战,其中一个是数据缺乏。这项技术需要大量数据来做出准确的预测,如果数据不足,AI 可能会做出不准确的预测。另一个挑战是材料的复杂性。由于材料是复杂的系统,AI 可能无法准确预测材料在不同环境中的性能。
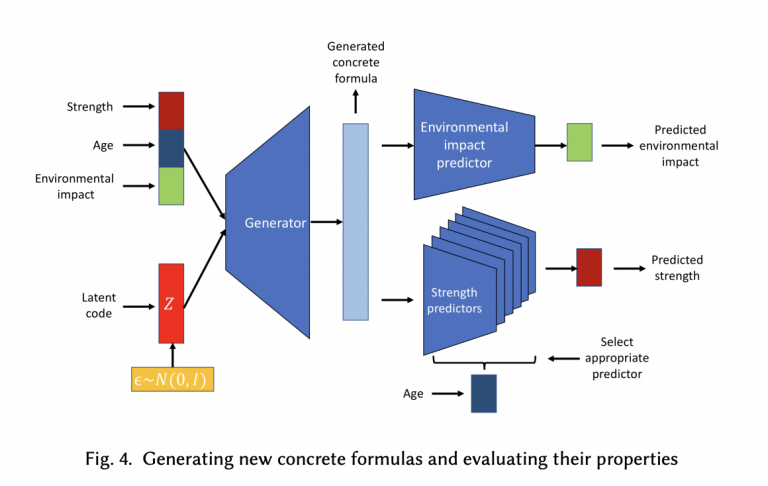
图源 | https://arxiv.org/pdf/2204.05397.pdf
11 AI 助力医学研究
Google 旗下公司 Deep Mind 的 AlphaFold (2021) ,是全球第一个能够准确预测蛋白质3D结构的模型。同年7月,Deep Mind 宣布了“蛋白质宇宙”—— 扩大 AlphaFold 的蛋白质数据库至200M种结构,这简直是非常珍贵的科学瑰宝!AI 在医学研究领域的应用(AI for Science)也在迅速发展,特别是 OpenAI 公司的 CEO —— Sam Altman 接下来也非常看好的领域。

图源 | 网络
2022年 GoogleAI 发布了一种名为 "MedGPT" 的模型,该模型可以根据病人的病史和影像学数据生成诊断和治疗建议。这项技术有望帮助医生更快更准确地诊断疾病,并且还可以帮助研究人员发现新的治疗方法。同年,费城生物医学工程卓克索大学的一项研究发现,ChatGPT 可以通过和人类的对话,帮助发现是否有阿尔茨海默氏病的早期症状,准确率达80%,高于使用传统方法的74.6%的正确率,从而及时提示患病风险。文章前面提到过,ChatGPT 的极致能力已经展现在可以通过美国医疗专业执照的考试。
12 AI 可以通过网络视频学习吗?
—VPT(“视频预训练”)模型
AI 可以学习人类复杂的动作吗?可以!Jeff clune 的团队发布了 VPT(“视频预训练”)模型,它甚至可以通过学习自己玩“我的世界”(Minecraft)!在“我的世界”中,一个人制作钻石工具需要完成2万多个动作,花费20分钟,VPT 通过学习记录了人们点击键盘鼠标的操作,居然学会了自己在我的世界中完成这些动作。
换句话说,只要知道了鼠标和键盘的点击移动顺序,VPT 可以通过 Inverse Dynamic Model(逆向动力模型)学习一切我们认为只有人类才能做到的复杂动作,比如如果我们可以准确记录 数字绘画 家在电子屏幕上的操作顺序,那么模型也可以模仿数字绘画家绘制一幅美丽的日落,VPT 为 AI 通过互联网上的视频来学习铺平了道路!
13 AI 代理在谈判上的突破
多年来,人们提出了许多用于外交的人工智能方法,主要依赖手工制定的协议和基于规则的系统,但远远落后于人的表现(无论有无沟通)。
Meta 公司的人工智能 CICERO 是第一个在外交游戏中达到人类水平表现的 AI 代理,在游戏《外交》中,CICERO 具有对他人的信仰、目标和意图进行推理的能力,可以通过表现同理心、使用人类语言交流并建立人际关系,同时能够有效地说服甚至欺骗,来达到在游戏中获胜的目的。
与此同时,DeepMind 公司也宣布了他们的外交游戏 AI 代理。试想,如果 CICERO 与 DeepMind 的 AI 对战会发生什么?
Diplomacy contracts
图源 | Freepik 上 kjargeter 的背景图像
14 Music-to-text 音频生成文本
Whisper 是由 OpenAI 开发的一个大型开源音频识别模型。它在英语的语音识别方面达到了接近人类水平的准确性和鲁棒性(在语音识别中,“鲁棒性”通常指一个模型的能力,即在嘈杂或有干扰的环境下识别语音的准确性和可靠性)。与其他模型不同的是,Whisper 使用了更大以及更多样的训练数据集。它使用网络上的共680,000小时的音频数据进行训练,这些数据是多语言和多任务的,使得 Whisper 除了能将英语转成英文,还能将几乎所有语种声音转成对应文字以及翻译成英语。
Whisper 提供了多种大小的英语/多语言模型,使得开发者能够在识别速度和识别质量中权衡。对于英语任务,开发者使用较小的模型便可达到良好的效果,识别速度甚至可以达到实时处理的效果。如果使用大模型,识别准确性则可以说超越所有现有商业公司的产品。对于汉语任务,开发者必须使用大模型才能达到较准确的识别,识别速度与中国商业公司的产品相比有一定差距。
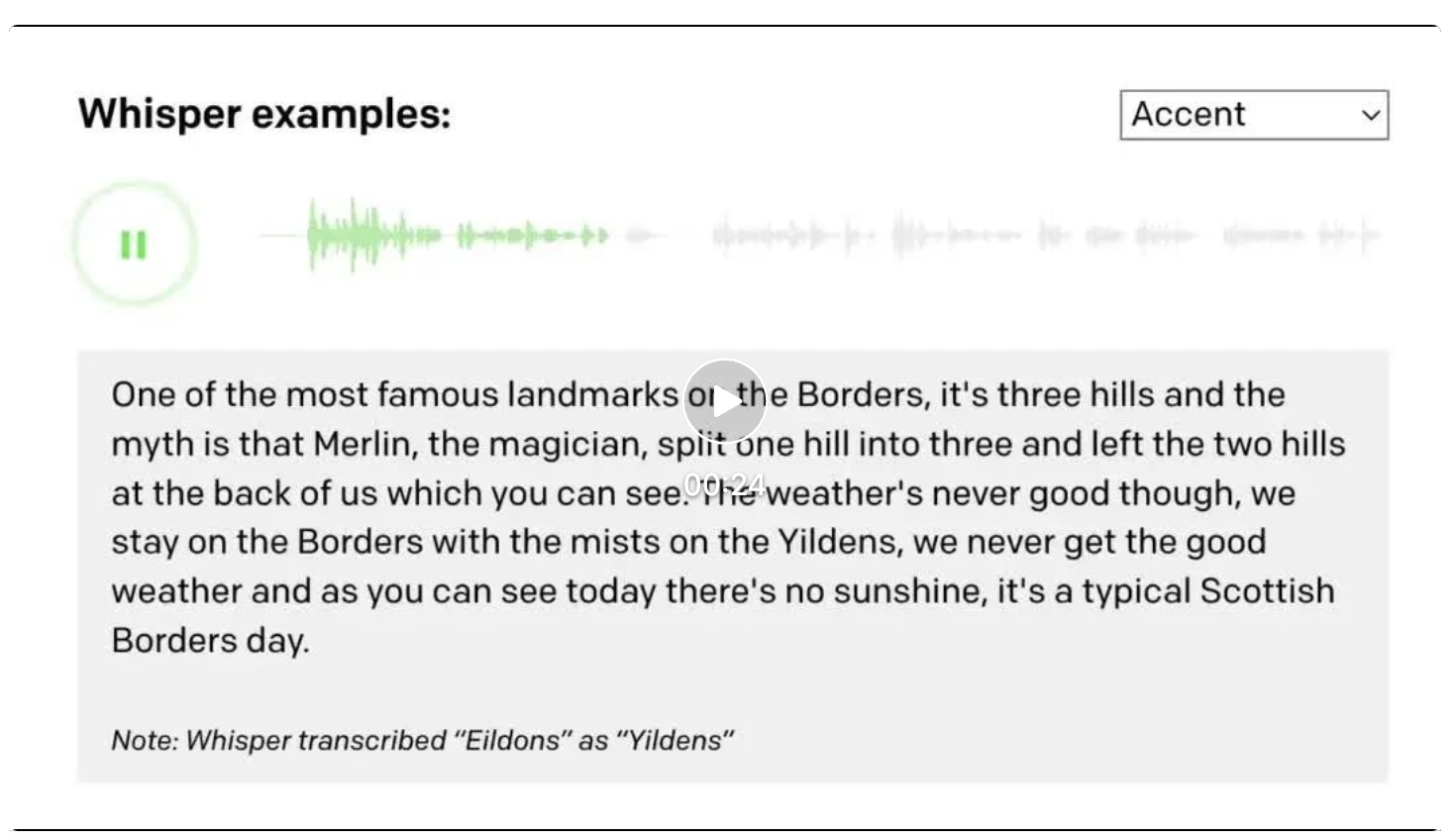
能识别口音很重的英文、再转译成文本
(源于论文发布网站)
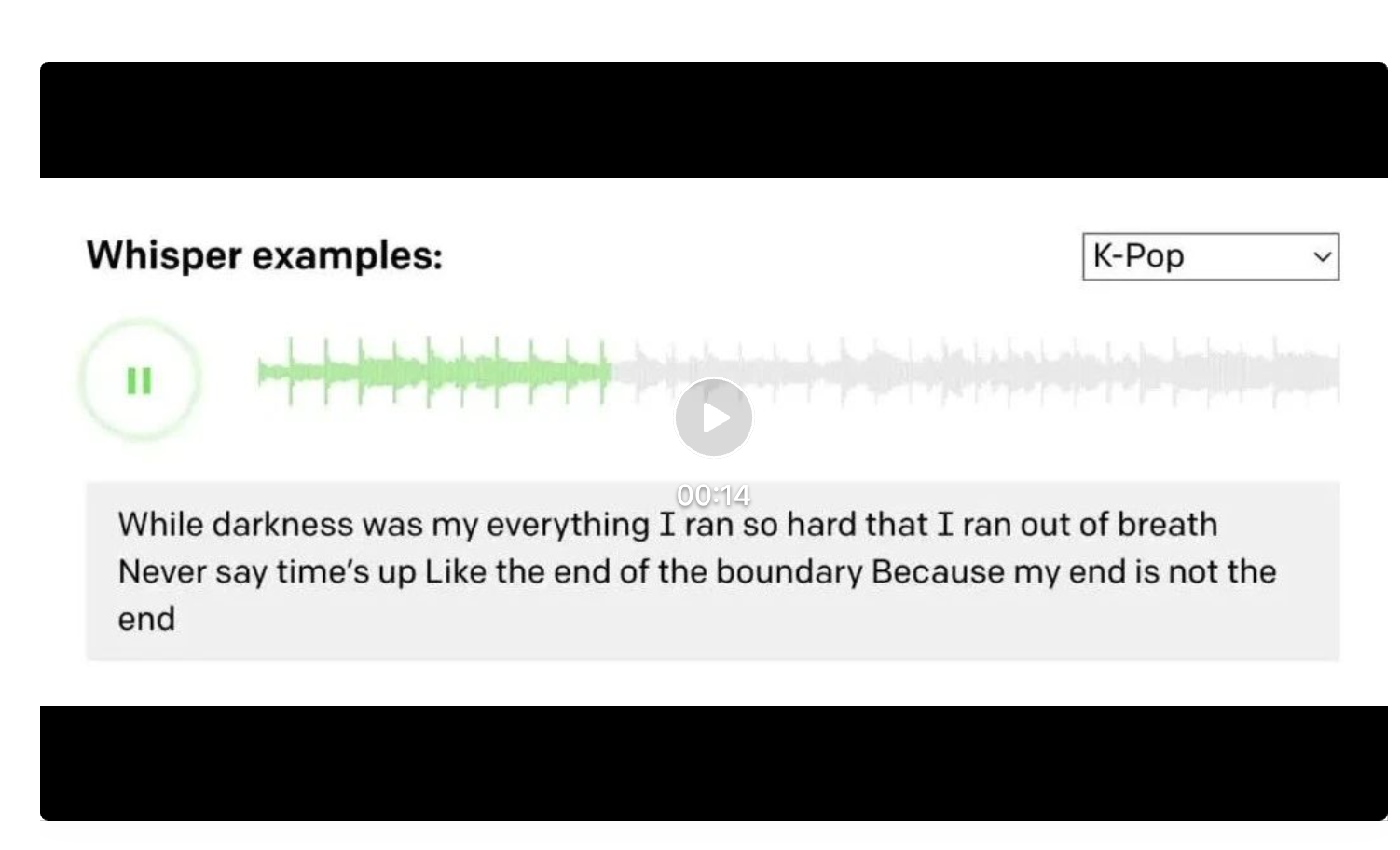
识别有背景音乐参杂的歌唱、再转译成文本
(源于论文发布网站)

上图为 Whisper 模型可以实现的任务
(源于论文发布网站)
15 Text-to-music 文本指令
生成音乐
MusicLM 是由谷歌研究院在近日发布的文本生成音乐模型,只发布了论文与数据集,没有开源。模型可以从文本描述例如 "平静的小提琴旋律伴着扭曲的吉他旋律"生成高保真的音乐。MusicLM 将文本指示的音乐生成过程描述为一个层次化的序列到序列的建模任务。它生成的音乐频率为24kHz,在几分钟内保持一致。
与之前的模型相比,MusicLM 在音频质量和对文本描述的遵守方面都更优。此外,MusicLM 可以以文本描述的旋律为条件,它可以根据文本说明中描述的风格来转换口哨和哼唱的旋律。为了支持未来的研究,谷歌研究院一并公开发布了 MusicCaps。这是一个由5.5K音乐-文本对组成的数据集,有人类专家提供的丰富文本描述。
(上述两个视频均来源于论文发布网站)
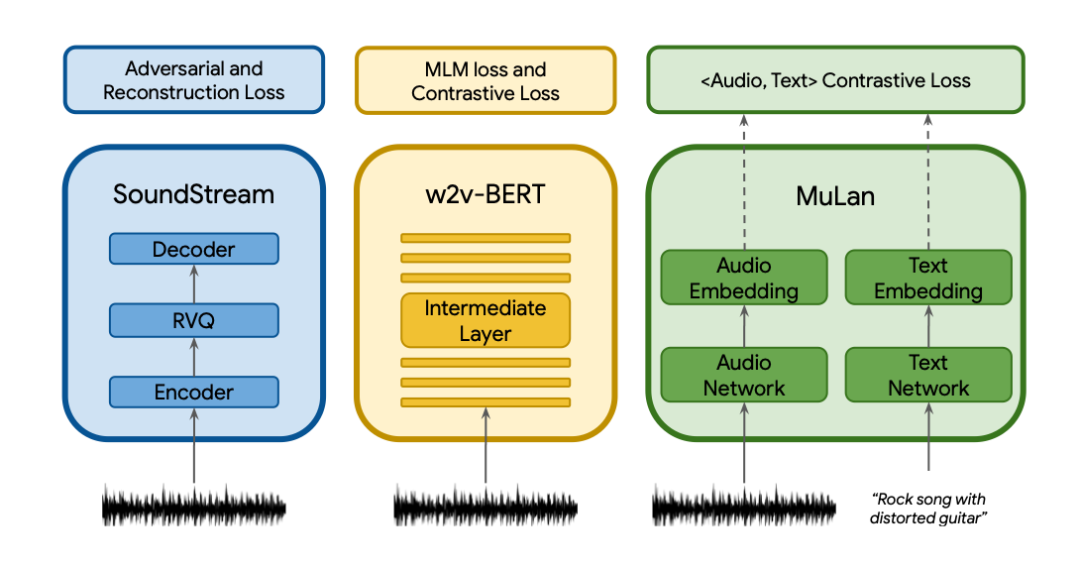
《MusicLM 使用独立的预训练来分别获得文本与音乐的表征》
16 别忘记了亚马逊云的存在
Amazon SageMaker 是在亚马逊云上的一站式大模型开发平台,可以提高大模型的开发效率。在 IDC 发布的报告中,Amazon SageMaker 被列入“领导者”阵营。
亚马逊云科技自研 AI 芯片可以提供更具性价比的方案,例如 Amazon Traini um 自研芯片的 Amazon EC2 Trn1 实例可节省高达50%的训练成本,而 Inf2 实例可支持横向扩展分布式推理,方便部署并提升高速推理。
Stability AI 选择 AWS 作为唯一云服务提供商,在 AWS 平台上搭建了大规模训练集群。使用 SageMaker Jumpstart 预集成的 SD2.0 预训练模型和优化库,Stability AI 能够使其模型训练具有更高韧性和性能,训练时间和成本可减少58%(这是很多钱)。

Stability AI 创始人 Emad Mostaque 出席亚马逊 2022 AWS Re:Invent 大会

Coinbase Moves Nearly 27 Million XRP Internally as Trading Volume Declines
Coinbase shifts 26.89M XRP internally as trading volume drops 34.72% and XRP hovers near $2.15 amid ...

Multichain Revolution Ignites—Qubetics, AAVE, and Cosmos Ranked Among Best Crypto to Get Rich List in 2025
Discover the best crypto to get rich in 2025 with expert insights on Qubetics, AAVE, and Cosmos. Lea...

Altcoins Soar: AERO, AB, KAIA, SPX Leads Top Crypto Gainers of the Week amidst Market Volatility
The data identified top crypto performers, highlighting an altcoin season as investors pump funds in...