从AIGC看到新世界正在到来



你知道 《太空歌剧院》 吗?
它是一幅 AI 作的画,并拿到了艺术比赛的一等奖。在 2022 年,AI 作画已经变得如此简单,你只要会打字就行。在一片高斯噪声中逐渐显露出精彩绝伦的颜色和图案,AI 是怎么画画的?为什么能画得这么好?会不会取代人类设计师?
更令人费解的在于,AI 有没有自己的逻辑思辨能力?
其实,我们还处在人工智能的早期,AI 对真正的逻辑和某个垂直领域的理解还不深,但不断强化它的逻辑思维能力一定会是接下来研发的重点。
书接上回,这次真格投资副总裁林惠文将带领我们,从上次 ChatGPT 的 AI 文字跳到 AI 图片(ChatGPT:又一个AI突破的时刻|真格投资人专栏),继续探索 AI 世界。从 AIGC 图片背后的模型,到模型之间的关系以及发展历程。 除此之外,我们还准备了对 AI 领域相关问题的解惑和一些好用的工具推荐,请一定不要错过~
非常荣幸今天能跟大家分享一些 AIGC 图片相关的梳理,在漫漫的熊市之中,近期我们看到了很多惊人的生成效果。
首先我们来看一下 AI 生成的图片。

这是最近非常火的 AI 生成图片平台 Midjourney (强烈推荐大家试试看)产生的一些图片效果,可以看到非常真实,也有很强的创意效果。它是如何做到的?
通俗易懂地来讲有三个步骤。首先,把人类的文字转换成计算机能够理解的表达,然后把计算机能理解的文本表达转换成计算机能理解的视觉描述,再接下来,把计算机能理解的视觉描述生成人类能够看懂的图片。
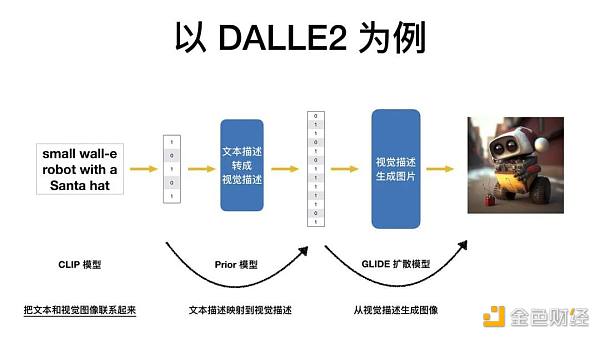
以 DALLE2 为例,它训练了 3 个模型来做这件事情。接下来,我会分别讲述。
CLIP 模型
第一个模型是 CLIP 模型,负责将文本和视觉图像联系起来。
过去的很多算法就像是拿 1 万张人类已经标注了类别的照片,让计算机去寻找不同类别照片的差异化特征。最大的缺点是,它无法标注世间万物,只能分类有限的集合,同时人力标注会成为学习的上限。
CLIP 模型带来的新思路是什么?它很像是真实生活中教小朋友认识物体。看到一个东西就直接告诉小朋友,这是一只游泳的鸭子,而不是一次性拿 20 张鸭子的图片告诉他,这是鸭子,你记住它的所有特征。CLIP 模型的算法实现了这样一个特点,只要我们有充足的算力,就能学会世间的万物。

CLIP 模型的数据集从哪来?它来自于互联网上图文的匹配对,总共收集了 4 亿张的图文匹配对,再经过一个图文编码器,把人类能看懂的文字和图片转换成计算机能懂的数据结构。
CLIP 模型用到了两个编码器,视觉编码器叫 Vision Transformer,文字编码器叫 Transformer。下图是 Vision Transformer 编码器产生的效果图,可以看到两张图片里背景部分的颜色被大幅弱化,强调了网球和黑狗的轮廓。这就是优秀的编码器能实现的效果:用人类的视角找重点,进行数据降维。

CLIP 模型做的事是什么?把来自互联网的 4 亿张图片和 4 亿条文本进行编码,并两两配对,形成一个 4 亿 * 4 亿的矩阵。
CLIP 模型的训练目标是什么?通过各种各样的复杂计算,让原本匹配的图片和文本产生正相关。将苹果的照片和苹果的文字进行匹配,而不是摩托车或其他。
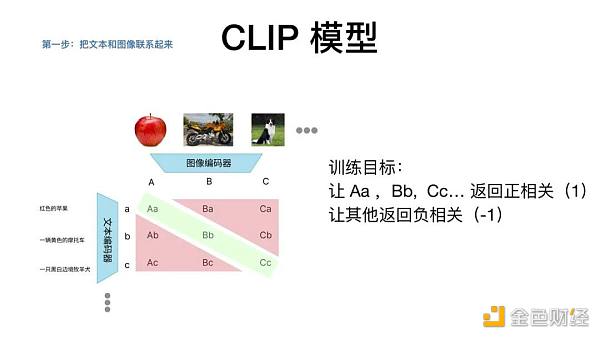
CLIP 模型实现的功能是什么?给定任何一个文本,能返回相关性最高的图片;给定任何一张图片,能返回相关性最高的文本描述。实现海量的图像和文字特征的 mapping。
GLIDE 模型
有了 mapping 以后,接下来重要的是如何从视觉的描述中产生图像,这是 GLIDE 扩散模型。
它就像是教小朋友学画画,先给小朋友看一张简笔画,逐渐把它擦掉,让小朋友在大人的引导之下,试着从白纸开始恢复这张简笔画。
从计算机的视角来看,擦除的过程就是给图片不断增加噪声的过程,这种噪声是一种正态分布的噪声,叫高斯噪声,直到最后变成一张纯噪声的图片。恢复的过程就是通过概率除去噪声的过程,这中间往往会加一些指引,叫 Guidance,以确保恢复的过程朝着对的方向。
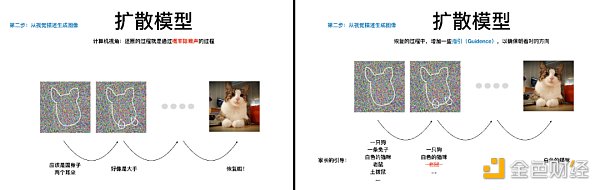
左图为增加噪声的过程,右图为除去噪声的过程
GLIDE 扩散模型带来最大的创新就是在训练的过程中融入了文本的信息。在 CLIP 模型的基础上,在恢复的过程中嵌入文本的信息,这就导致了难度的快速叠加,因为它既要学会恢复的算法,又需要学会识别的算法。然而,在恢复的过程中,它并没有把知识完全融入其中,如何才能把知识彻底地融入到图像生成里?
GLIDE 模型的抽象理解,就像是爸爸教小朋友骑车,目标是希望在有爸爸扶和没有爸爸扶的时候,小朋友都能骑出同样的曲线。这往往通过一种中间形态来实现,从一直扶到偶尔扶,偶尔撒手,最终的训练目标就是不断在这种状态里达成。
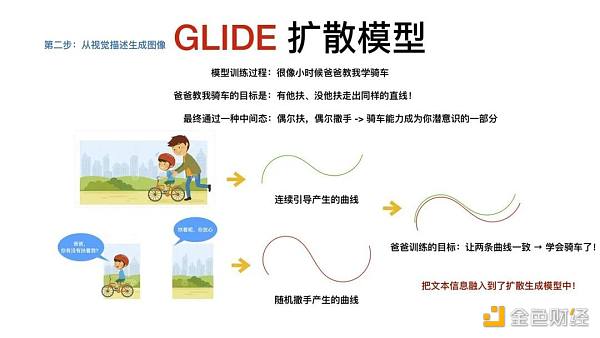
GLIDE 扩散模型的目标也是如此,在它的原理中,爸爸扶着小朋友就是分类器,能帮助分类或目标识别,撒手就意味着无分类器指引,有时会将一些文本的信息替换成空的字符串,随机替换掉一些信息。当有分类器产生的曲线和没有分类器指引产生的曲线一致时,整个文本的信息就融入到了生成过程中。
有了 GLIDE 扩散模型以后,还可以制定不同的引导目标,因此会产生不同的效果,如果你想生成与某张图片一样效果的图片,你可以输入这张图片,接着就会得到一张类似风格的图片。这就像是一个小朋友的爸爸告诉他,自行车的前轮其实是个装饰品,他最终在不断的强调之下,就会学会这样骑车的方式。
PRIOR 模型
当 CLIP 模型将文本和视觉相连,GLIDE 模型通过概率恢复一张随机的模糊照片,并把文本信息融入其中,我们还缺少了这两者之间的联结,如何把文本描述映射到视觉描述中,这就是 PRIOR 模型的核心。
有了 CLIP 模型,虽然能够实现文本和视觉之间相关性的描述,但还缺少一个转换器,那就是面对一个新的描述,如何产生一张新的图片。就像你教会了小朋友画帽子,也教会了画兔子,现在如何让他画一张戴帽子的兔子。PRIOR 模型其实是在 CLIP 模型之后产生一个新的效果,在 CLIP 模型中用到的文本和图片编码器,给编码后的东西再增加一个特征,这就使得文本和图片的信息都融合在同个维度,便于我们去操作。
三个模型的关系
CLIP 模型理解了图片与文字的关系,PRIOR 模型就是在理解图片与文字的关系之上,从文字中产生一个脑海中的构图,GLIDE 扩散模型就是要把脑海中的构图画出来,画出人类能懂的视觉图片。

我们再从下图论文的原理来理解一下。图中有一条虚线,虚线的上方是预训练的过程。左边的 Text Encoder,就是之前提到的文字转换器 Transformer,它把一段文字转换成计算机能理解的表达。右边的 Image Encoder,也就是视觉转换器 Vision Transformer,把人类理解的视觉图片转换成计算机的数据结构。
在经过大量的训练之后,这两者之间产生了具有相关性的连接,也就是文字和图片之间的关系产生了非常强的理解。
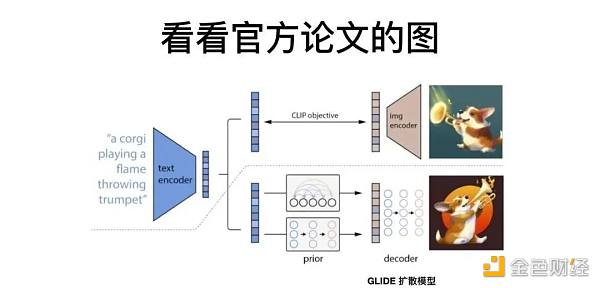
虚线之下是生成的过程,把文本放进 PRIOR 模型里面,从这段文本中生成计算机能理解的视觉表达结构,再用 GLIDE 模型生成人类能看懂的图片。虽然上下两只小狗的图片看起来不一样,但它们本质上包含了同样的文本语义,这样就实现了任何一段文本都能生成出一张人类能看懂的图片。
发展历程
整个梦开始的地方,始于 2017 年 Google 发布的一篇论文《Attention is all you need》。它让算法学会了人类的注意力机制,就是当我们去看一张图片时,会看到重点,同时忽略背景的信息。
这篇论文发表之后,带来一个 NLP 的模型,叫 Transformer,一经发布便快速屠榜,接着很快有了 BERT 模型,有了 OpenAI 的 GPT-3 模型。在视觉领域,有 DERT 模型,iGPT 模型,以及上面提到的 Vision Transformer。
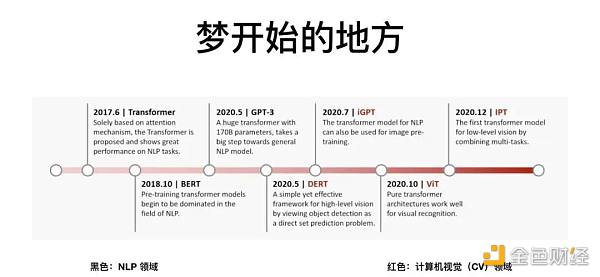
Transformer 模型的重要性在于,它是我们刚才提到的三个模型的底座,学会找出图片和文字的重点,才能够搭建CLIP 模型,才可能有之上的 PRIOR 和 GLIDE 扩散模型。
梦想的实现还有另一半,图像生成。
从 2005 年开始的求解特定概率密度函数,通俗理解就是通过最快的方法去估算正态分布,再到 2008 年的去噪自编码器的研发,加入高斯噪声,一种正态分布的噪声,再将它去除,我们用到的很多拍照中的去噪、降噪功能就是从这里来的。到了 2011 年,有人尝试将这两种算法结合在一起,2015 年,开始尝试用这种思想还原照片。但这时候还原照片的质量还不是很高。
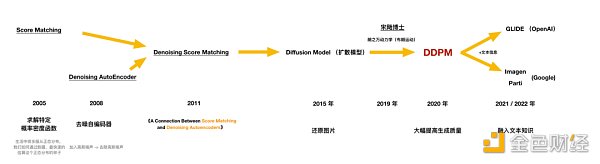
时间拨转到 2019 年,中国的宋飏博士把朗之万动力学引入到数据分布的估算中,产生了非常好的效果。2020 年,Google 发布名叫 DDPM 的论文,这篇论文核心就是结合朗之万动力学和扩散模型,产生了非常高的图片生成质量。
2014 年引起轩然大波的 GAN network 对抗生成网络,已经能生成出效果不错的图片,但它的训练难度很高,扩散模型降低了图像生成模型的训练难度,还能生成比 GAN 更多元的图像。
在梦想实现的 2021 和 2022 年,OpenAI 和 Google 都开始尝试把文本信息加入到扩散生成的过程中,产生了今天的 GLIDE 模型。OpenAI 在思想上的突破,用 Transformer 去海量地理解图片和文本,产生了 CLIP 模型,再用扩散模型在图像生成中融入海量的图文信息,优质的 AIGC 图片终于诞生。
接下来,我们将围绕一些问题进行讨论。
1、从产品化、商业化的角度出发思考,目前 AIGC 的技术层面的发展会产生影响?
有两个维度。第一个维度是在海量数据中寻找我们最想要的内容,第二个维度是在海量数据中得出新的内容,反向给予我们创造的灵感。
从 AI 本身的能力再进行泛化的话,一方面很多现有产品的使用体验能得到巨大的提升,例如在笔记类的软件中加入 AI 后,在写作过程中能得到更好的体验;另一方面,未来创意不强,生成能力较弱的人可能会被 AI 替代。
2、回到基本逻辑,我想确认下自己的理解是否正确:相较于 Transformer,ChatGPT 并不是在 AI 领域出现了一个颠覆性的技术创新,而只是在一个模式上加了人类的 feedback,设置了不断迭代的参数,它自己越搞越聪明了。
过去的所有模型的进化,其实围绕两个方向在进化。第一个是 DNA,第二个是方法论。DNA 很像真实世界中材料的研发,方法论更像是真实世界中材料的使用。
Transformer 是 DNA 的进化,是更核心的突破。ChatGPT 是方法论,但它就更简单了吗?并不是的,它在探索的过程中经历了很长的时间,同时要满足很多先决条件,这个方法论才能得以运用。不论方法论突破还是 DNA 突破,都很有意义。
3、未来的生意模式会怎么样?会不会更集中?围绕这样 ChatGPT 的模型,它会产生哪些创业方向?
可能有两种商业模式,一种是 To B 的,就跟阿里云一样,另外一种就是让开发者在这种大模型上去 To C。不论是 DNA 还是在方法论上的突破,它都可能让一个企业产生垄断,产生巨头效应。
ChatGPT 和用户不断互动,会得到源源不断的反馈数据,数据也是一种资产,一种生产要素。这种生产要素产生的产品会是人类更高频使用的东西,它的频率越高,这种生产要素就越来越重要,反馈能够创造的要素提升就越来越重要,同时带来的经济价值就越来越大。
4、会不会有规模效应或双边网络效应?
我觉得背后既有这种网络效应,又有一些规模效应。如果设想一下,第一个研发出来的这种中文大模型,它会快速地获取市场上有限量的开发者,开发者在用它的产品去面向 To C 去获取 C 端用户,它的数据会源源不断反馈回来,去优化它的效果,其实就会产生更强的垄断效应。
5、从投资的角度,在 AIGC,我们应该投什么样的团队?
我觉得传奇的团队是有创造 DNA 能力的团队,黄金的团队是有能力把应用层和 AI 完美结合的能力,白银的团队就是打造 AI 领域的基础设施的团队。
最后分享一些我常用的工具,它们对于做投资判断来说很有重要性,希望可以对你有所帮助 。

Bitcoin Won’t Save You—Peter Schiff Says Gold Will Win As Trump Wrecks The Dollar
Gold proponent Peter Schiff hit out at US President Donald Trump’s support for cryptocurrency, calli...

Coinbase Exploiter Acquires 649 ETH, Continues Laundering Spree
The Coinbase hacker has bought 649.62 more Ethereum $ETH, highlighting the attacker’s ongoing endeav...

Looking for the Best 100x Crypto? Troller Cat’s 1833% ROI Powers Stage 14 Momentum as Shiba Inu and Bone ShibaSwap Hold Steady
Troller Cat achieves a 449% ROI as it leads the top 100x crypto race, surpassing Shiba Inu and Bone ...