
StarkNet性能路线图:如何攻克排序器难题?



原文:《 StarkNet Performance Roadmap 》
编译:wesely
路线图中的并行化、Rust 等改进,都是为接下来 StarkNet 提升 TPS 所做的准备。
-
rollups 的有效性不受限于L1的吞吐量,使得 L2 的 TPS 可以很高。
-
在 StarkNet 的性能路线图中,解决了系统中的一个关键因素——排序器。
-
性能的改进主要有以下几点:
-
排序器(Sequencer)的并行化
-
为 Cairo 虚拟机(Cairo-VM)提供 Rust 语境下的实现
-
在 Rust 语境下的排序器
-
证明者(Provers)并不是瓶颈,他们可以处理比现在更多的东西。
简介
大约一年前,StarkNet Alpha 正式上线了以太坊主网,这时,我们将重心放在了功能的构建上,现在,我们决定将重点转移到提高性能之上,并计划通过一系列的步骤来提高 StarkNet 上的用户体验。
在这篇文章中,我将解释为什么有很多优化措施只适用于有效性汇总(Validity Rollups),并分享 StarkNet 实施这些措施的计划和步骤,其中一些计划已经在 StarkNet Alpha 0.10.2 中实现,在讨论具体的细节之前,让我们先来回顾一下限制链上性能的原因。
区块限制:Validity Rollups 与 L1
提高区块链可扩展性和 TPS 的方法之一是:在解除区块的限制(比如GAS和区块大小的限制)同时,保持区块生成时间的不变。这需要区块生产者(L1 上的验证器,L2 上的排序器)提供更高效的服务,因此就需要更有效地执行这些组件,因此,我们将重点转移到 StarkNet 排序器的优化之上,在下文会详述具体内容。
这里会有一个问题,为什么对排序器的优化仅仅对 Validity Rollups 有效,换句话说,为什么我们不能在 L1 上以相同的方法改进,避免有效性汇总(Validity Rollups) 有复杂性?在下一节内容中,对这一问题将进行回答。
为什么L1吞吐量有限
如果 L1 的区块限制被解除,会遇到一个很大的问题,因为链的高吞吐带来了链上区块的高增长率,为了确保不同的节点跟上最新的全链状态,就需要增加了更多的全节点。又由于 L1 全节点必须记录所有历史记录,区块大小的大幅增加会给全节点运营者带来巨大压力,并导致部分全节点因为机器性能落后而退出系统,结果,能够运营全节点的都是一些比较大的实体,最终就是用户无法以无信任的姿态验证状态并参与网络。
这也让我们明白,从某种意义上来说正是 L1 吞吐量的限制,成就了一个真正去中心化的和相对安全的网络系统。
上述问题为什么不会出现在 Validity Rollups 之上?
只有在考虑全节点的问题时,我们才能看到有效性汇总(Validity Rollups)的优势。正常情况下,一个L1全节点需要重新执行整个链的历史以确保当前状态的正确性,而 StarkNet 节点只需要验证 STARK 证明,而且这种验证需要的计算资源呈指数级下降。重点是,链上全节点状态的验证同步没有涉及到执行;一个节点可以从另一个全节点那里接受当前状态的转储,只需通过 STARK 证明来验证这个状态是否有效即可。这让我们在增加网络的吞吐量的同时,不用增加全节点的数量。
因此,在 L2 上,通过对排序器的优化可以对整个系统的性能进行提升,但这在L1上不能实现的。
StarkNet 的未来性能路线图
这一部分,我们将讨论目前有哪些计划用于对 StarkNet 排序器的优化。
排序器并行化
性能路线图的第一步是为交易执行引入并行化。这个提议是在 StarkNet alpha 0.10.2 中正式引入的,该版本于11月29日在以太坊主网上发布,我们现在来深入探讨下什么是并行化。
一般来说,并行执行多个交易区块是不可以的,因为不同的交易可能是相互依赖的。以下方示例中进行说明,我们假设有一个包含来自同一用户的三笔交易的区块:
-
Tx A(交易A,下同):将USDC兑换ETH
-
Tx B:为某款NFT支付ETH费用
-
Tx C:将USDT兑换BTC
显然,交易A必须发生在交易B之前,但交易C完全独立于两者,是可以并行执行的。如果每个交易需要1秒执行,那么通过引入并行化处理之后,区块生产时间可以从3秒减少到2秒。
问题的关键在于,我们事先并不知道不同交易之间的依赖性。在实践中,只有当我们执行到示例中的 Tx B 时,我们才会发现它是依赖于 Tx A所做的改变。更准确地说,这种依赖性源于Tx B 从Tx A 写入的存储单元中读取这一动作。我们可以把不同的 Tx 看成是一个依赖图,其中存在从交易 A 到交易 B 的一条边,当且仅当 A 写入一个由 B 读取的存储单元时,B 才可能执行。下图显示了这种依赖之间的关系:
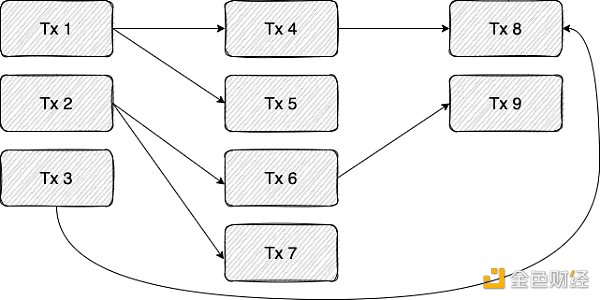
在上面的示例中,每一列都可以并行执行。
为了克服事先无法确定不同交易事件之间的依赖关系,我们根据 Aptos Labs 推出的 BLOCK-STM ,将 OP 并行化(optimistic parallelization)引入到 StarkNet 排序器中。在这种模式下,会以乐观地方式并行地处理事务,并在发现碰撞时重新执行。比如在上述示例图中,我们可以并行执行 TX1-4,但事后发现 Tx 4 依赖于 Tx1,因此这次执行是无效的(应该在 Tx1 执行后运行 Tx 4 ),在这种情况下,将重新执行Tx4。
请注意,在上述这种乐观并行化的基础上我们也增加一些优化措施。例如,与其等待每个执行的结束,可以在发现一个使之运行结果无效的依赖关系时就中止执行。
另一个优化的例子是选择哪些事务来重新执行。假设由上述示例图的所有事务组成的区块被送入一个拥有五核CPU的排序器。首先,我们尝试并行执行 tx 1-5,如果完成的顺序是Tx2、Tx3、Tx4、Tx1,最后是Tx5,那么我们将在 Tx4 已经执行后才发现依赖关系Tx1→Tx4,这表明它应该被重新执行。直观地说,考虑到Tx4的重新执行,Tx5也需要重新执行,然而,我们可以遍历由执行已经结束的事务构建的依赖图,只重新执行依赖于Tx4的事务,而不是将失效Tx4之后的事务都重新执。
Rust 语境下的 Cairo-VM 实现
StarkNet 中的智能合约是通过 Cairo 语言编写的,并在 Cairo-VM 虚拟机中执行。目前,排序器正在使用 python 语言在 Cairo-VM 上运行 。为了优化虚拟机的实现性能,我们之前发起了用 Rust 重写 Cairo-VM 虚拟机的工作。
目前, cairo-rs 可以执行原生 Cairo 代码,下一步是处理智能合约的执行和与 pythonic 排序器的集成,一旦与 cairo-rs 集成,排序器的性能有望进一步提高。
Rust 语境下的排序器
通过 python 到 rust 的转变以提高网络性能,不仅限于 Cairo-VM,StarkNet 用 Rust 重写了排序器相关的代码。除了 Rust 的内部优势之外,这还为排序器的其他优化提供了可能,比如,可以集合 cairo-rs 的优势,而无需 python-rust 通信的开销,也可以完全重新设计状态的存储和访问方式。
证明者(Provers)
在整篇文章中,没有提到有效性汇总(Validity Rollups)中核心元素之一——证明者(Provers)。作为可以说是架构中最复杂的组件,证明者(Provers)算是瓶颈,也是优化的重点。但现在,StarkNet 的瓶颈是更加“标准”的组件,特别是对于 递归证明 ,可以将当前测试网/主网上的更多交易放入证明中。事实上,StarkNet 区块与 StarkEx 交易一起得到有效的市场证明,后者有时会有数十万 NFT 的铸造事件。
总之,并行化、Rust 等改进,都是为接下来 StarkNet 提升 TPS 所做的准备。

Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
Justin Sun suspected to have purchased $160m in Ethereum
Justin Sun suspected to have purchased $160m in Ethereum