a16z:以三要素衡量SNARK性能



本文来自 a16z ,原文作者:Justin Thaler,由 Odaily 星球日报译者 Katie 辜编译。

SNARK(简洁的非交互式知识参数)是一种重要的密码原语,用于发现区块链可扩展性(例如 L2 Rollup)和隐私的应用。 SNARK 允许某人向不可信验证器 V(例如 以太坊 区块链)证明他们知道一些数据(例如一批有效交易)。证明这一点的简单方法是将数据发送给 V,然后 V 可以直接检查其有效性。SNARK 实现了同样的效果,但对 V 来说成本更高。特别是SNARK 证明应该比包含数据本身的原始证明更短。
SNARK 的验证成本可能会有所不同,但成果通常都很好。例如,PlonK 的证明在以太坊上的验证成本约为 29 万 gas,而 StarkWare 的证明成本约为 500 万 gas。SNARK 可能适用于区块链之外的各种不同的设置,例如,允许使用快速但不可信的服务器和硬件。
但由于 SNARK 验证通常很便宜,适用性的主要决定因素是 SNARK 证明者 P 的成本。本文中将解释如何估算这些成本,以确定何时合理使用 SNARK,以及未来如何改进 SNARK。值得注意的是,这是一个快速发展的领域,本文中讨论的几个项目正在积极提高其性能。
SNARK 是如何部署的?
在 SNARK 部署中,开发人员通常编写一个计算机程序 ψ,将证明人声称知道的数据 w 作为输入(w 代表验证者),并检查 w 是否有效。例如,在 Rollup 中,程序将检查 w 中的所有交易是否都经过数字签名,是否导致任何帐户余额低于零等。然后通过 SNARK 前端输入程序 ψ,该前端将程序编译成更适合 SNARK 技术应用的格式。这种 SNARK 友好格式称为中间代码(IR)。
通常,IR 是某种等效于 ψ 的电路可满足性实例。这意味着电路 C 以数据 w 作为输入,以及一些通常被称为“非确定性建议”的额外输入,并在 w 上运行 ψ。这些建议输入用于帮助 C 运行 ψ,同时保持 C 较小。例如,每当 ψ 除以两个数 x 和 y 时,商数 q 和余数 r 就可以作为建议提供给 C, C 可以简单地检查 x = qy + r。这种检查比让 C 运行除法算法从头计算 q 和 r 更便宜。
最后,将可满足性电路 SNARK 应用于 C。这称为 SNARK 后端。对于一些高度结构化的问题,如矩阵乘法、卷积和一些图问题,已知的 SNARK 可以避免这种前端/后端范式,从而实现更快的证明。但本文的重点是通用的 SNARK。
正如我们将看到的,SNARK 后端验证成本随着 C 的规模而增长。保持 C 尽可能小是一项挑战,因为电路是一种极为有限的计算格式。它们由门组成,由电线连接。给每个门 g 输入一些值,并对这些值应用一个非常简单的函数。然后,通过 g 发出的导线将结果送入“下游”门。
SNARK 的可扩展性需要多长时间?
关键问题是,相对于简单地对数据重新执行 ψ,SNARK 证明器需要多长时间?答案是 SNARK 的验证程序,是相对于直接的验证者核查。后一个表达式指的是在 P 将 w 发送给 V 的原始证明中,V 通过对 w 执行 ψ 来检查 w 的有效性。
将证明器开销分为“前端开销”和“后端开销”是有利的。如果逐门计算电路 C 的成本是运行 ψ 的 F 倍,那么我们称前端开销为 F。如果将后端验证程序应用于 C 的成本是逐门评估 C 的 B 倍,那么我们称后端开销为 B。总验证程序开销是 F 乘以 B。即使 F 和 B 各自都不大,这个乘法开销也可能很大。
实际上,F 和 B 都可以是 1000 或更大。这意味着相对于直接验证者核查,证明程序的总开销可能是 100 万到 1000 万或更多。在笔记本电脑上运行一秒钟的程序很容易导致 SNARK 验证程序需要数十天或数百天的计算时间(单线程)。幸运的是,这项工作通常在不同程度上是并行的(取决于 SNARK)。
总之,如果你想在今天的应用程序中使用 SNARK,必须满足以下三个条件中的一个:
1.在笔记本电脑上直接核查验证者只需要不到一秒钟的时间。
2.直接验证者核查特别适合在电路中进行,因此前端的开销很小。
3.你愿意等待数天等待 SNARK 验证程序完成,并/或支付巨大的并行计算资源。
本文的其余部分解释了前端和后端开销从何而来,以及我如何对不同的SNARK进行估算。以及未来改善的前景。
区分前端和后端
因为不同的后端支持不同类型的电路,所以完全区分前端和后端是一个挑战。因此,前端可以根据它们期望与之交互的后端而有所不同。
SNARK 后端通常支持所谓的算术电路,这意味着电路的输入是某个有限域的元素,电路的门执行两个域元素的加法和乘法。这些电路大致相当于直线计算机程序(没有分支、条件语句等),这些程序在本质上是代数的,也就是说,它们的原始数据类型是字段元素。
大多数后端实际上支持大部分算术电路,通常称为 Rank-1 约束满足(R1CS)实例。除了 Groth16 和它的前身,这些 SNARK 也可以用来支持其他的 IR。例如,StarkWare 使用了一种叫做代数中间表示(AIR)的方法,这与 PlonK 和其他后端支持的 PlonKish 算术运算类似。一些后端支持更通用的 IR 的能力可以减少产生这些 IR 的前端的开销。
后端也因其本机支持的有限字段而有所不同。我将在下一节进一步讨论这个问题。
前端的多种方法
一些(非常特殊的)计算机程序自然对应于算术电路。一个例子是在某个域上执行矩阵简单乘法的计算机程序。但大多数计算机程序既不是直线也不是代数。它们通常涉及条件语句、整数除法或浮点运算等与有限域运算不自然对应的运算等。在这些情况下,前端开销将相当大。
一种热门的前端方法是生成基本的电路,逐步执行一些简单的 CPU,也称为虚拟机(VM)。前端设计人员指定一组基本操作,类似于实际计算机处理器的汇编指令。想要使用前端的开发人员要么直接用汇编语言编写“验证者检查程序”,要么用诸如 Solidity 这样的高级语言编写“验证者检查程序”,然后让他们的程序自动编译成汇编代码。
例如,StarkWare 的 Cairo 是一种非常有限的汇编语言,其中的汇编指令大致允许在有限域上进行加法和乘法运算、函数调用以及对不可变(即只写一次)内存的读写。Cairo VM 是一种冯·诺伊曼架构,这意味着前端产生的电路本质上将 Cairo 程序作为公共输入,并在见证器面前运行该程序。Cairo 语言是图灵完备的——尽管它的指令集有限,但它可以模拟更多的标准架构,尽管这样做可能会很昂贵。Cairo 前端将执行 T 个原语指令的 Cairo 程序转换为所谓的“2 级 AIR, T 行,大约 50 列”。这到底意味着什么并不重要,但就 SNARK 证明而言,这相当于 Cairo CPU 的每个 T 步骤都有 50 到 100 个门的电路。
RISC Zero 采用了与 Cairo 类似的方法,但它的虚拟机是所谓的 RISC-V 架构,这是一种开源架构,具有丰富的软件生态系统,越来越受欢迎。作为一个非常简单的指令集,设计一个高效的支持它的 SNARK 前端可能是相对容易处理的(至少相对于复杂的体系结构,如 x86 或 ARM)。截至5月,RISC Zero 正在将执行原始 RISC-V 指令的程序转换为具有 3 排和 160 列的 5 级 AIR。这对应于每步 RISC-V CPU 至少有 500 个门的电路。预计在不久的将来会有进一步的改进。
各种 zkEVM 项目(例如,zkSync 2.0、Scroll、Polygo 的 zkEVM)将虚拟机作为以太坊虚拟机。将每条 EVM 指令转换为等效的“小工具”(即实现指令的优化电路)的过程要比简单的 Cairo 和 RISC-V 架构复杂得多。由于各种原因,一些zkEVM 项目并没有直接实现 EVM 指令集,而是在将高级 Solidity 程序转化为电路之前将其编译成其他汇编语言。这些项目的性能结果尚未确定。
如 RISC-V 和 Cairo 的“CPU 模拟器”项目,产生的单个电路可以处理相关汇编语言中的所有程序。另一种方法是类似 ASIC 芯片的,为不同的程序产生不同的电路。这种类似 ASIC 的方法可以为一些程序产生更小的电路,特别是当程序在每个时间步执行的汇编指令不依赖于程序的输入时。例如,它可以潜在地完全避免直线程序(如初始矩阵乘法)的前端开销。但 ASIC 的方法似乎也非常有限/据我所知,还不知道如何使用它来支持没有预先确定迭代边界的循环。
前端开销的最后一个组成部分来自于所有 SNARK 都使用在有限域上运行的电路。你的笔记本电脑上的 CPU 可以用一条机器指令将两个整数相乘或相加。如果前端输出电路的场特性足够大,它本质上可以通过相应的场操作来模拟乘法或加法。但是,在真正的 CPU 上实现字段操作通常需要许多机器指令(尽管一些现代处理器确实对某些字段有本机支持)。
一些 SNARK 后端支持比其他更灵活的字段选择。例如,如果后端使用加密组 G,则电路的字段必须与 G 中的元素数量匹配,这可能是有限的。此外,并非所有领域都支持实用的 FFT 算法。
只有一个实现的 SNARK——Brakedown,在本地支持任意(足够大)字段的计算。除了它的下一代,它在其他 SNARK 支持的字段上具有最快的已知具体验证性能,但目前它的证明对于许多区块链应用来说太大了。最近的工作试图改进证明的大小,但证明器的速度较慢,并且在实用性方面似乎存在障碍。
有些项目选择在运算速度特别快的领域工作。例如,Plonky2 和其他算法使用 264 - 232 + 1 的特征域,因为该域的算法实现速度比非结构化域快好几倍。然而,使用如此小的特征可能会导致通过字段操作有效地表示整数算术的挑战。(例如,将一个32位无符号整数乘以任何大于 232 的数字可能会产生大于字段特征的结果。因此,字段选择自然只支持 32 位数字的算术。)
但是无论如何,对于今天所有热门的 SNARK 来说,要实现 128 位的安全性(不需要明显增加验证成本),它们必须在大于 2128 的域上工作。据我所知,这意味着每个字段操作将需要至少 10 次 64 位机器乘法,以及相当多的加法和位运算。因此,由于需要在有限域上运行的电路,应该考虑至少一个数量级的前端开销。
总而言之,使用虚拟机抽象的现有前端在虚拟机的每个步骤中产生 100 到 1000 个门的电路,对于更复杂的虚拟机可能会产生更多。最重要的是,有限字段算法比现代处理器上的类似指令至少慢 10 倍(如果处理器内置了对某些字段的支持,也可能有例外)。一种“ ASIC 芯片前端方法”可能会减少其中一些开销,但目前仅限于它能支持的程序类型。
后端瓶颈是什么?
可满足性电路的 SNARK 通常是通过结合一个称为“多项式 IOP ”的信息理论上安全协议和一个称为“多项式承诺方案”的密码协议来设计的。在大多数情况下,证明器的具体瓶颈是多项式承诺方案。特别是这些 SNARK 使证明器以加密方式提交一个或多个多项式,其次数为(至少)|C|,即电路 C 中的门数。
相应地,多项式承诺方案中的具体瓶颈将取决于所使用的方案和电路大小。但总是以下三种操作中的一种:计算 FFT、加密组中的幂运算或 Merkle 哈希。Merkle 哈希通常只有在电路很小的情况下才是瓶颈,因此我们将不再进一步讨论它。
基于离散对数的多项式承诺
在基于密码组 G(KZG、BulletProof、Dory 和 Hyrax commit)中离散对数问题的硬度的多项式承诺中,证明者必须计算多项式系数的 Pedersen 向量承诺。这涉及到多重幂运算,其大小等于多项式的次数。在 SNARK 中,这种程度通常是电路C的大小|C|。
简单地说,对大小|C|进行多次幂运算需要大约 1.5·124≈400·|C|群运算,其中 124G|-表示群G中的元素数。然而,有一种称为 Pippenger 算法的方法,可以将其减少大约 log|C|。对于大型电路(例如|C|≥225),该对数|C|因子可以具体为 25 或更大,也就是说,对于大型电路,我们预计 Pedersen 向量组合可以通过略多于 10·124C124 的群运算来计算。反过来,每组操作往往比有限场操作慢 10 倍左右(作为一个非常粗略的球场)。使用这些多项式承诺的 SNARK 对于 P 来说与大约 100·|C|现场操作一样昂贵。
但是现有的 SNARK 除了 100 倍的倍数之外还有额外的开销。例如:
-
Spartan 的证明使用 Hyrax 多项式承诺,必须做|C|½多次幂,每个大小为|C|½,削弱了 Pippenger 的算法的加速约为2倍。
-
在 Groth16 中,P 必须在对结对友好的组上工作,其操作通常比不对结对友好的组慢至少两倍。P 也必须执行 3 次多次幂而不是 1 次。综合起来,这导致了相对于上面估计的100·|C|的至少额外 6 倍的减速。
-
Marlin 和 PlonK 也要求配对,他们的证明者承诺的多项式远多于 3 个。
-
对于任何使用了子弹证明的 SNARK(例如 Halo2,它大致是 PlonK,但使用了子弹证明而不是 KZG 多项式承诺),证明者必须在承诺方案的“开始”阶段计算对数级的多次幂,这在很大程度上消除了任何 Pippenger 加速。
总之,已知的 SNARK 使用 Pedersen 矢量承诺的后端开销至少为 200 倍,最高可达 1000 倍或更多。
其他多项式的承诺
对于使用其他多项式承诺(如 FRI 和 liigero -commit)的 SNARK,瓶颈处在于证明程序需要执行大型 FFT。例如,在Cairo 生产的 2 级 AIR(有 51 列和 T 行,Cairo CPU 每步有 1 行)中,StarkWare 部署的验证程序每列至少执行 2 个 FFT,长度在 16·T 到 32·T 之间。常量 16 和 32 依赖于 StarkWare 设置的 FRI 内部参数,可以减少,但以增加验证成本为代价。
乐观地说,一个长度为 32 的 FFT 大约需要 64·T·log(32T)场乘法。这意味着即使T的值相对较小(例如 T≥220),每个列的字段操作数至少是 64·25·T=1600·T。因此,后端开销似乎至少有数千。此外,大型 FFT 的瓶颈可能是内存带宽,而不是字段操作。
在某些上下文中,执行大型 FFT 的 SNARK 的后端开销可以通过一种称为证明聚合的技术来减轻。对于 Rollup,这意味着P (Rollup 服务)将一大批交易分解为 10 个较小的批。对于每一个小批量 i, P 产生一个 SNARK 证明 πi 的批次有效性。但是 P 没有将这些证明发布到以太坊,因为这将导致gas成本增加近 10 倍。相反,再次应用了 SNARK,这一次产生了 π 的证明,证明 P 知道 π1,π10。也就是说,P 声称知道的证人是 π1,…,π10 这十个证明,直接证人核查将 SNARK 验证程序应用到每一个证明上。这个简单的 π 证明被发布到以太坊。
在多项式承诺(如 FRI 和 liigero -commit)中,P 时间和 V 花费之间存在很强的张力,内部参数充当一个旋钮,可以在两者之间进行权衡。由于 π1,…,π10 没有发布到以太坊,旋钮可以调整,所以这些证明是大的,生产它们的速度更快。只有在 SNARK 的最终应用中,才能将 π1、π10 聚合成单个证明 π,才需要配置承诺方案来保证小证明。
StarkWare 计划立即部署证据聚合。这也是 Plonky2 等项目的重点。
SNARK 可扩展性的其他瓶颈是什么?
本文关注的是验证时间,但其他验证成本也可能是可扩展性的瓶颈。例如,对于许多 SNARK 后端,证明程序需要为 C 中的每个门存储多个字段元素,这种空间开销可能非常大。在笔记本电脑上运行一秒钟的程序 ψ 可以在现代处理器上执行10亿次原始操作。一般来说,C 需要超过 100 个门来完成这样的操作。这意味着 1000 亿个门,这取决于 SNARK,可能意味着 P 有几十或几百 TB 的空间。
另一个例子是许多热门的 SNARK(例如,PlonK、Marlin、Groth16)需要一个复杂的“可信设置仪式”来生成一个结构化的“证明密钥”,它必须由证明者存储。据我所知,最大的一次这样的仪式产生了一个能够支持电路的证明密钥,大约有228≈2.5 亿个门。证明的关键是几十 GB 大小。
在证明聚合可能性较高的环境中,这些瓶颈可以适当突破。
展望未来:可扩展性更强的 SNARK 前景
前端和后端开销都可能是三个数量级或更多。我们能否期待在不久的将来这些数字会大幅下降?
在某种程度上,我认为我们会的。首先,今天最快的后端(例如 Spartanand Brakedown 以及其他结合了求和校验协议和多项式承诺的 SNARK)有很大的证明量——通常是电路大小的平方根,所以人们并没有真正使用它们。我预计在不久的将来,通过深度一合成和小的验证障碍,验证规模和验证时间将显著减少。与证明聚合类似,这意味着证明者将首先使用快速证明者,大证明者 SNARK 生成 SNARK 证明 π,但不会将 π 发送给 V。相反,P 将使用一个小的证明 SNARK 产生一个证明 π′,证明它知道 π,并将 π′ 发送给 V。这可以在很大程度上减少目前流行的 SNARK 后端开销。
其次,硬件加速会有所帮助。一个非常简单的规则是 GPU 可以买到比 CPU 快 10 倍的速度,而 ASIC 可以买到比 GPU 快 10 倍的速度。然而,我有三个担忧。首先,大型 FFT 的瓶颈可能是内存带宽,而不是字段操作,所以执行此类 FFT 的SNARK 在专用硬件上的加速可能有限。第二,虽然本文关注的是多项式承诺瓶颈,但许多SNARK要求证明者做其他的操作,这些操作的成本只比多项式承诺瓶颈低一点点。因此,打破多项式承诺瓶颈(例如,在基于离散日志的 SNARK 中加速多次幂)可能会留下一个新的瓶颈操作,它并不比旧的好多少。(例如,SNARK 包括 Groth16、Marlin 和 PlonK,除了多次幂之外,也有 FFT 的验证程序。)最后,导致最有效的 SNARK 的场和椭圆曲线可能会持续发展一段时间,这可能会给基于 ASIC 的验证加速带来挑战。
在前端,我们可能会越来越多地发现,Cairo、RISC Zero、zkEVM 等项目的“CPU 模拟器”方法实际上可以很好地扩展(就性能而言)CPU 指令集的复杂性。事实上,这正是各种 zkEVM 项目的希望所在。这可能意味着,虽然前端开销仍然是三个数量级或更多,但前端可以支持越来越匹配真实 CPU 架构的虚拟机。与之相反的一个担忧是,随着手工编码的小工具实现越来越复杂的指令激增,前端可能会变得复杂,难以审核。正式的核查方法很可能在解决这一问题方面发挥重要作用。
最后,至少在区块链应用程序中,我们可能会发现大多数出现在非主流的智能合约主要使用简单的、SNARK 友好的指令。这在实践中可能会降低前端开销,同时保留支持 Solidity 等高级编程语言和包括 EVM 在内的丰富指令集所带来的通用性和改进的开发人员体验。
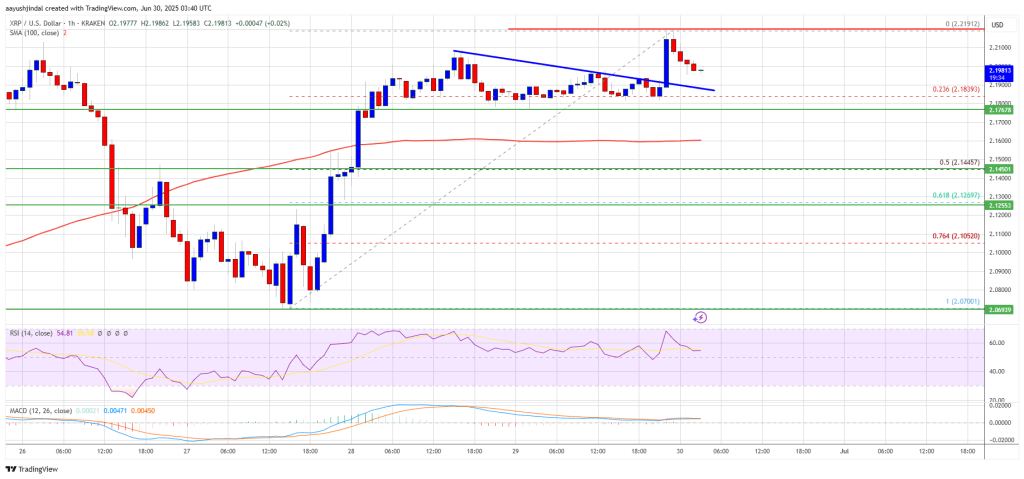
XRP Price Springs Higher — Rally Reignited with Bullish Momentum
XRP price started a steady increase above the $2.120 zone. The price is consolidating and might aim ...

Why Are MicroStrategy Insiders Selling Millions in Stock While Bitcoin Booms?
The post Why Are MicroStrategy Insiders Selling Millions in Stock While Bitcoin Booms? appeared firs...

Bitcoin Price Surges Above $108,000: Analyst Predicts Potential Breakout To $150,000
The Bitcoin price has recently climbed back above the $108,000 mark, yet it struggles to surpass its...