Web3要具有竞争力 必须实现数据的价值



作者:Abel Chan
随着最近Ceramic、IPFS和Arweave等工具的发展,一个更加去中心化的互联网架构正在慢慢出现,数据被存储在个人数据商店而不是企业服务器或中心化云服务中。 个人数据存储意味着用户将首次能够完全拥有他们的数据,控制他们的数据如何被使用,并在他们的数据价值中获得更大份额。 随着来自不同应用程序的数据在用户的控制下存储在一起,应用程序之间的低摩擦数据共享也应导致更大的可组合性和比目前更丰富的应用程序生态系统。
尽管这个愿景很有希望,但转向以用户为中心的数据所有权模式是一个重大变化,不会在一夜之间发生。值得探讨的是,从现在的情况开始,事情会如何发展。
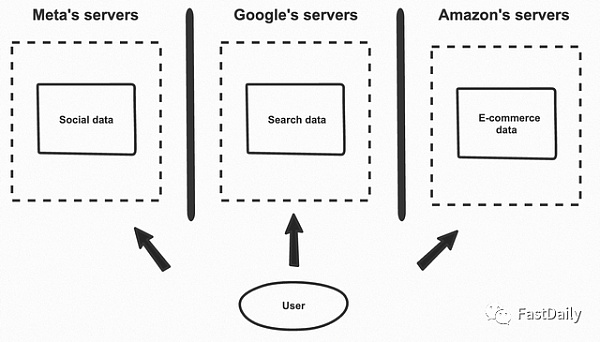
今天的数据存储在公司服务器上的孤岛中
今天,如果一个用户正在浏览一个网站,他们产生的数据会被储存在两个主要位置——浏览器和公司拥有的数据库。如果你在Facebook注册并创建一个账户,那么关于你的账户和第一篇文章的数据将直接进入Meta的服务器。如果你再去创建一个Gmail的账户,那么就会被单独存储在谷歌的服务器上。这种方法被称为以应用为中心的数据存储模式。
由于数据被公司存储在不同的数据库中,所以对数据的使用方式几乎没有直接控制。它可以被复制,用于未经授权的目的,或在你不知情或不同意的情况下转售,尽管像GDPR和CCPA这样的法规在一定程度上有所帮助。用户也很难在应用程序之间共享数据。如果你是一个开发者,你可以得到用户的凭证,然后在幕后做一个API集成来获取数据(例如,集成Plaid来连接Chase),但这不是一个小的工作量。
“数据舱 “为使用链外数据的dapp提供可组合性
至少从2017年开始,互联网的发明者Tim Berners Lee一直在开发以用户为中心的数据存储模型。根据这一设想,个人应该能够选择他们的数据所处的位置以及谁可以访问这些数据。在Web3中,这意味着将数据存储在与创建它的用户相关的IPFS等服务上,而不是基于创建它的应用程序的企业服务器上1。请注意,像AWS或谷歌云这样的中心化云服务并不符合 “个人数据存储 “的要求,因为亚马逊和谷歌仍然可以不受限制地访问用户数据。相比之下,通过使用像Ceramic这样的服务与去中心化的存储相结合,数据可以被加密,其访问由用户使用加密密钥管理,因此除了用户之外,没有人可以未经许可进行互动。
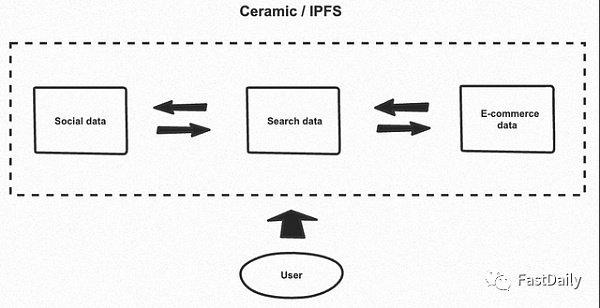
个人数据存储通过将数据存储在一个地方来提高可组合性
对于使用个人数据存储的可能性的例子,假设你使用Sign In With Ethereum (SIWE)来登录一个去中心化的社交媒体应用程序。你与该应用的互动然后进入你的个人数据存储。后来当你登录到一个去中心化的市场时,你分享了对存储在你的 “数据舱 “中的社交媒体的访问,并收到基于这些的定制推荐。使用包含在你的 “pod”中的所有网站的可访问索引,市场应用甚至可能发现你在Adidas.com上的账户,并为你提供折扣的运动鞋。
通过这种设置,用户可以轻松地管理哪些数据将与谁共享。用户今天用来授权访问他们的谷歌数据的相同流程,可以被用户重新利用来授权访问他们的任何或所有的DApp数据。如果用户不想分享,而只是想删除他们的所有数据,这种模式也可以让他们完全控制,做出这个决定。
使用 Google 登录请求用户权限
在另一边,想让用户分享数据或访问dapp数据的开发者可以不用处理自定义API集成。 相反,一个通用的登录服务(如SIWE)和 “数据舱 “可以结合起来,形成一个可重复使用的模式来授予数据访问权。 这就好比即使是世界上最小的创业公司也可以实现自己的谷歌登录来对外分享数据,或者使用谷歌登录来访问任何其他公司的数据。
这样做的最终结果应该是更大的可组合性。虽然数据的可访问性很少影响使用链上数据的应用程序的可组合性,但由于区块链数据是透明的,对于利用敏感的链下数据的应用程序来说,这可能是一个问题,必须仔细许可以保护用户隐私。 使用通用登录解决方案(例如 SIWE)来授予对这个个人“数据 pod”中的隔间的访问权限解决了这个问题,并允许使用链下数据的 dapp 更轻松地进行交互。
除了可组合性,还有数据所有权
一个典型的美国谷歌用户每年的数据被货币化为256美元,而一个典型的美国Meta用户的数据是1122美元。尽管科技公司目前通过收集用户产生的大量数据然后将其货币化来创造收入,但如果我们采用以用户为中心而不是以应用为中心的数据存储模式,这种方法就会发生变化。
今天,有两种主要的数据用于广告: 第一方数据, 由用户正在访问的网站收集, 以及第三方数据, 由用户当前网站以外的其他方收集。第一方数据可能是非常详细和有价值的,但很难获得,因为它必须由用户直接提供3。第一方数据的一个例子是在注册时提交的账户信息,或者你在电子商务网站上填写的调查。另一方面,第三方数据更为广泛,但也更为浅显。谷歌的第三方cookie可以在你浏览各个网站时跟踪你的URL,甚至当你在非谷歌网站时,也可以与谷歌分享数据。这种数据有广度,但没有深度,因为URL并不包含关于用户的更多细节。
广告技术行业的一个核心问题是与跨浏览器和设备追踪人有关。由于大量用于追踪的cookies不能在不同的浏览器上跟踪人们,即使是在同一设备上,如果用户不登录或提交他们的电子邮件,就很难知道他们是谁。零散的数据价值较低。假设你在耐克公司工作——如果你知道John早些时候在火狐桌面上访问了adidas.com,但你不知道目前在iPhone上访问合作伙伴网站的人也是John,那么你刚刚错过了展示运动鞋广告的机会。由于第三方cookies已经在Firefox以及Opera上被禁止,并将在2024年之前从Chrome中移除,因此跨设备追踪用户只会变得更加困难。
如果第三方数据越来越不可靠,那么第一方数据自然是一个可以考虑的替代方案。即使假设像《纽约时报》这样的网站愿意出售其登录用户阅读和评论的故事的数据,也没有简单的方法来做到这一点。因为没有技术框架,所以需要手工操作,以使数据能够被外部各方访问,并接受数据的付款。
Web3的数据将更容易获取和标准化
正如存储在个人数据商店的数据的开放性、可访问性和可发现性增加了可组合性一样,它也为数据的货币化带来了巨大的潜在改进。同样的 “用X登录 “模式可以被开发者用来获取数据用于开发目的,也可以被广告商和用户用来交换数据并实现货币化。
解决当今明显的行业问题,以用户为中心的数据存储将使跨设备追踪用户变得相当容易,只要他们使用像Sign in With Ethereum这样的去中心化身份解决方案进行登录。 从中期来看,个人数据存储所提供的改进的技术框架和货币化潜力也将使大量高质量的第一方数据变得可用。 像Meta或谷歌这样的公司存储在其服务器上的所有数据,理论上都有可能在个人数据存储中提供,但要考虑隐私问题、存储限制和其他技术因素。
然而,从长远来看,改善开放数据标准的潜力可以使今天在混乱的数据中挣扎的工程师、数据科学家和数据工程师的生活变得容易得多。如果大量今天不透明的 “专有 “数据集能够被公开访问(尽管可能需要付费),那么无论是通过直接协调还是人们复制他人正在做的事情,都会更容易汇聚到数据标准上。想象一下用于存储电子商务数据、金融交易数据、证书等的标准化格式并不难。拥有一个以用户为中心的数据存储模型,不仅会让用户的生活变得更好,也会让开发者和广告商的生活变得更加轻松。
然而,最重要的是,假设有更多的第一方数据可用,并使广告商得到更好的服务,用户最终会要求获得更大但仍可持续的数据价值份额。像Brave这样的公司已经开始给用户提供他们所看到的广告的收入份额,但这还可以更进一步。如果用户愿意选择分享更高质量的数据,就会有更多有价值的数据,然后用户就可以从中抽成(如Brave Rewards),而每个人都会得到更好的回报。然而,关键是用户的选择。许多用户无疑重视他们的隐私,但对于那些喜欢其他方式的用户可以选择捕捉他们自己的数据价值而不是隐私。
如果Web3基本上只是更多的广告,但用户获得更大的价值份额,这当然不是一个坏的起点。然而,我们仍然可以做得更好,考虑用更聪明的方式来获取数据的价值。
建立一个全球数据市场
与其让用户受制于今天的广告,我们可以选择让用户直接出售他们的数据。这些数据市场今天已经存在,但大多涉及第三方和数据经纪人在灰色市场上出售数据,而没有用户的可见性或授权。
未来的数据市场可以在开放源码中实现,并内置隐私控制。如果来自用户的数据主要托管在个人数据商店,你可以设想一个统一的市场,它包含对互联网上大多数用户数据的访问。用户可以选择他们可以出售的数据,以及他们接受的数据的最低金额。营销人员可以搜索符合特定属性的用户,或特定应用程序的用户。学术研究人员可以带着预算来,在几分钟内从他们的具体研究项目中获得有针对性的数据集。
在线市场理论上并不难建立,它们已经存在了很久(想想Craigslist)。然而,对于个人数据市场来说,有几个独特的问题需要解决。第一个问题相当简单:一旦数据被出售,它就脱离了用户的控制,可以被无限地复制。你可以在一定程度上避免这个问题,对于经常性非常重要的数据(例如,你最近访问过哪些网站),但其他类型的数据几乎肯定会被转卖。保护隐私的技术在这方面提供了一些解决方案,我们将在后面讨论。
拥有可用数据的公司或应用程序也需要一些激励措施来放弃对用户数据的控制,并有可能要求获得数据销售的百分比。这对于用户拥有的数据来说似乎不合适,但请记住,A)他们目前在数据货币化收入中的份额是100%,这比说5%要大;B)如果没有数据源的参与,用户就没有什么可供货币化的。如果你是一个市场,你需要供应需求。公司也会要求在一定程度上控制数据被卖给谁。耐克不希望他们最有价值的用户数据被阿迪达斯廉价购买。有些公司根本不买账,有些公司会提供一些数据,而有些公司会完全接受开放数据交换。
最后,要弄清楚如何为数据定价可能会很棘手。数据的价值不仅取决于你所购买的数据,还取决于你已经有多少数据与之结合以训练一个模型,以及你使用这些数据的目的。大多数人都不知道如何给他们的数据定价,所以我们需要好的建议,以多少钱来出售数据。关于数据定价的更多信息,请参见Ocean Protocol45的脚注中的优秀资源。
每个人都讨厌广告,但没有人愿意真正付费
完全摆脱广告,仅通过用户出售数据来支持Web3是否可行?这似乎不太可能,因为许多公司购买数据的目的很可能是为了服务广告。此外,广告如此广泛存在有一个根本原因。
为什么今天会有广告存在?调查显示,75%的美国人认为在线广告具有侵扰性6。在超级碗广告之外,几乎没有人喜欢广告。
简单的答案是,高质量的内容和服务需要钱来制作。《纽约时报》有5000名员工,谷歌有一些员工团队在为他们的免费地图产品改进算法,这些都是免费的。在一个可以选择付费的网站上,估计只有1-3%的用户会选择付费7。即使是那些愿意付费的人,一些内容或网站的价值(例如你前几天读到的那个简短的体育故事)可能只值这么一点钱(例如0.10美元),所以不值得花精力去做小额支付。由于这些原因,Web2.0已经默认了广告的使用,以支付从有趣的Buzzfeed故事到Tiktok短视频的免费服务。
Web3已经提出了新的货币化选择,但没有一个能解决95%不想付费的用户的关键问题。对于内容创作者或媒体公司来说,NFT绝对是有价值的工具,但这些很可能只被高度参与的粉丝购买。他们不会帮助捕捉其他95%参与度较低、不想购买的粉丝。微额支付很好,但可能仍然会失败,原因与Web 2.0相同,因为它们所涉及的努力对于小交易额(例如0.10美元)来说是不值得的。相比之下,无论用户是否点击,广告都会被显示并为网站创造收入。
每个人都讨厌广告。但没有人讨厌到要真正付钱的地步。如果Web3不能找到从数据中实现价值的方法,它将没有现实的机会参与竞争。
联合学习保护隐私
如果广告是一种必要的邪恶,我们如何才能在Web3中使其变得更好?这就把我们带到了最后的讨论,保护隐私的广告。
Brave浏览器是加密领域的先驱,以其注重隐私的浏览器而闻名,它阻止了大多数传统的广告,以及其保护隐私的广告。作为一个浏览器,Brave可以访问浏览历史等数据,这些数据有一天可能会被储存在个人数据舱中。为了取代它所屏蔽的传统广告,Brave浏览器以浏览器通知的形式向用户展示选择广告。浏览这些选择广告的用户会因此获得奖励。有趣的是,Brave还运行一个 “广告网络”,广告商可以购买针对对特定主题感兴趣的用户的广告,如 “体育”、”购物 “或 “旅游”。
Brave的广告是独特的,因为它使用保护隐私的机器学习来决定显示哪些广告。Brave利用一种称为 “联合学习 “的特殊技术来训练他们的广告模型,预测用户最有可能点击的广告。通过联合学习,一个模型的 “小块 “首先在用户的设备上用他们自己的数据进行训练,然后这个 “小块 “被发送到一个中央服务器,与其他小块结合,形成一个最终模型。与谷歌等公司使用的技术相比,这些公司的广告模型通常是在服务器或服务器集群中集中存放的大量数据上进行训练的,这种技术确保没有私人数据离开用户的设备8。这个想法是,如果没有私人数据离开用户的设备,那么他们的数据就会受到保护,不会在未经他们允许的情况下被转售或利用。仍然有一些隐私问题需要解决,例如,看一个用户的模型可能会告诉你一些关于他们的数据是什么样子。但最终,只要最终的模型有足够的预测性,这种设置仍然比现状的隐私好很多。
在一个所有用户的数据都可以在个人数据舱中获得的世界中,大量的数据将提供给所有各方(不仅仅是特定的公司),而且更多的模型,不仅仅是广告模型,可以安全地在这些数据上训练。想想医疗保健的模型,根据病人的医疗数据训练,而不是预测人们点击广告的模型。
技术的现状
我们离实现这个愿景还有多远?
去中心化的存储层已经到位了。像IPFS和Arweave这样的不可变的存储服务已经分别存在了7年和5年,并且正在迅速成熟起来。请注意,这些数据存储必须是不可变的,因为在一个去中心化的环境中,必须注意数据不被篡改。在这些之上,像Ceramic或Textile的ThreadsDB这样的工具增加了一个 “可变性 “层,通过在不可变的存储之上实现一个只需追加的分类账910,使修改数据变得更加容易。尽管账本中的每一个额外的更新都是不可变的,但解析综合更新的最终结果是可变的,就像 比特币 账户余额可以改变一样,尽管单个过去的交易是不可变的。
隐私和许可功能是仍然可以使用进一步发展的领域。Ceramic似乎最近才实施许可系统,它可能仍然需要一些时间来成熟和变得完全强大11。对于隐私敏感的用户来说,在用户的个人设备上实现数据舱,而不是在第三方的分散存储节点上实现,可能是有用的。对于在手机和电脑等个人设备上实现的数据存储,数据可能会根据需要在线或离线,而且对存储节点是否真的删除或以其他方式复制了你的数据的担心会减少。帮助获取数据价值的附加层在很大程度上似乎还没有被开发出来。专注于简单的数据交换和货币化的协议可能是一个好的起点。除此之外,必须创建去中心化的数据市场或实现个人数据存储的联合学习协议。
与技术一起考虑的最后一块缺失是监管。尽管如果用户要求,公司可以采用个人数据存储,但不能强迫他们不在其它地方存储额外的数据副本。类似于GDPR(通用数据保护条例)的未来法律,是欧盟关于数据隐私的法律,可以强制执行更好的行为,并加速企业采用个人数据存储作为遵守隐私法规的更简单的方法。这些法规,如个人数据存储,可以成为强大的工具,帮助确保数据隐私(和数据所有权)作为用户的基本权利。
Bitcoin Price Faces Stiff Resistance: Is Another Drop on the Horizon?
Bitcoin price started a downside correction below the $96,500 zone. BTC is now trading below $95,000...
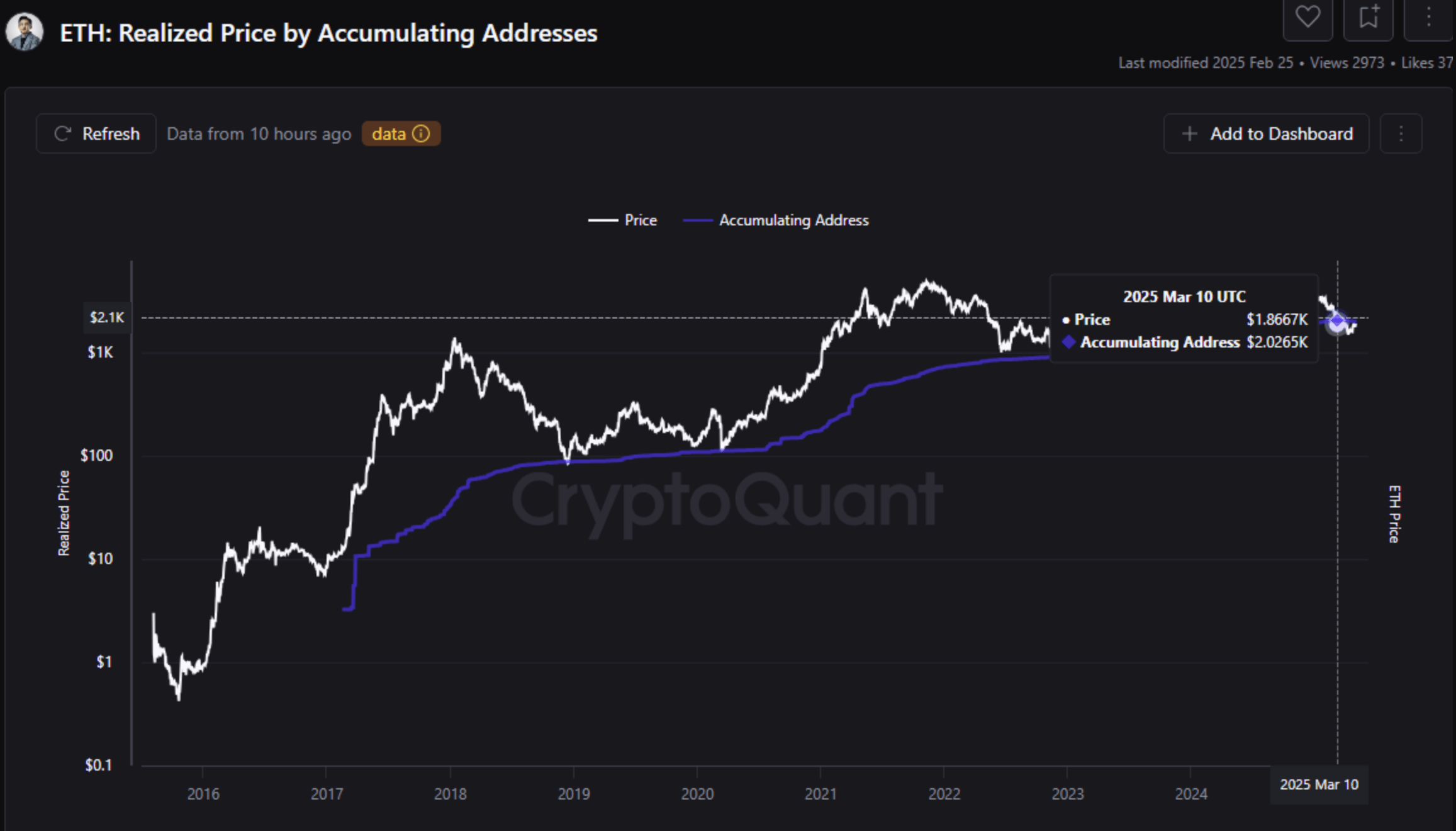
Ethereum Holders Stay Committed Despite Unrealized Losses – Signs Of An Incoming Rally?
According to a recent CryptoQuant Quicktake post, Ethereum (ETH) accumulation addresses are continui...

XRP News: Ripple Blamed for XRP Price Stagnation, but Legal Expert Calls It a Myth
The post XRP News: Ripple Blamed for XRP Price Stagnation, but Legal Expert Calls It a Myth appeared...