



作者:XinGPT
要理解存储,必须先理解半导体整个产业链发生了什么。
故事的起点:推理已经超过训练
过去两年,半导体的故事一直是"NVIDIA + 训练集群"。但是从 2026 年开始,由于AI Agent需求的突然爆发,最典型的比如Claude Code的爆发式增长,让Anthropic 的 ARR 4 个月从 90 亿美金涨到 300 亿美金。
推理已经占了 AI 计算量的 66%, 两三年前这个数字还只有 33%。也就是说,三年时间,推理和训练的位置完全反过来了。
而这意味着什么呢?
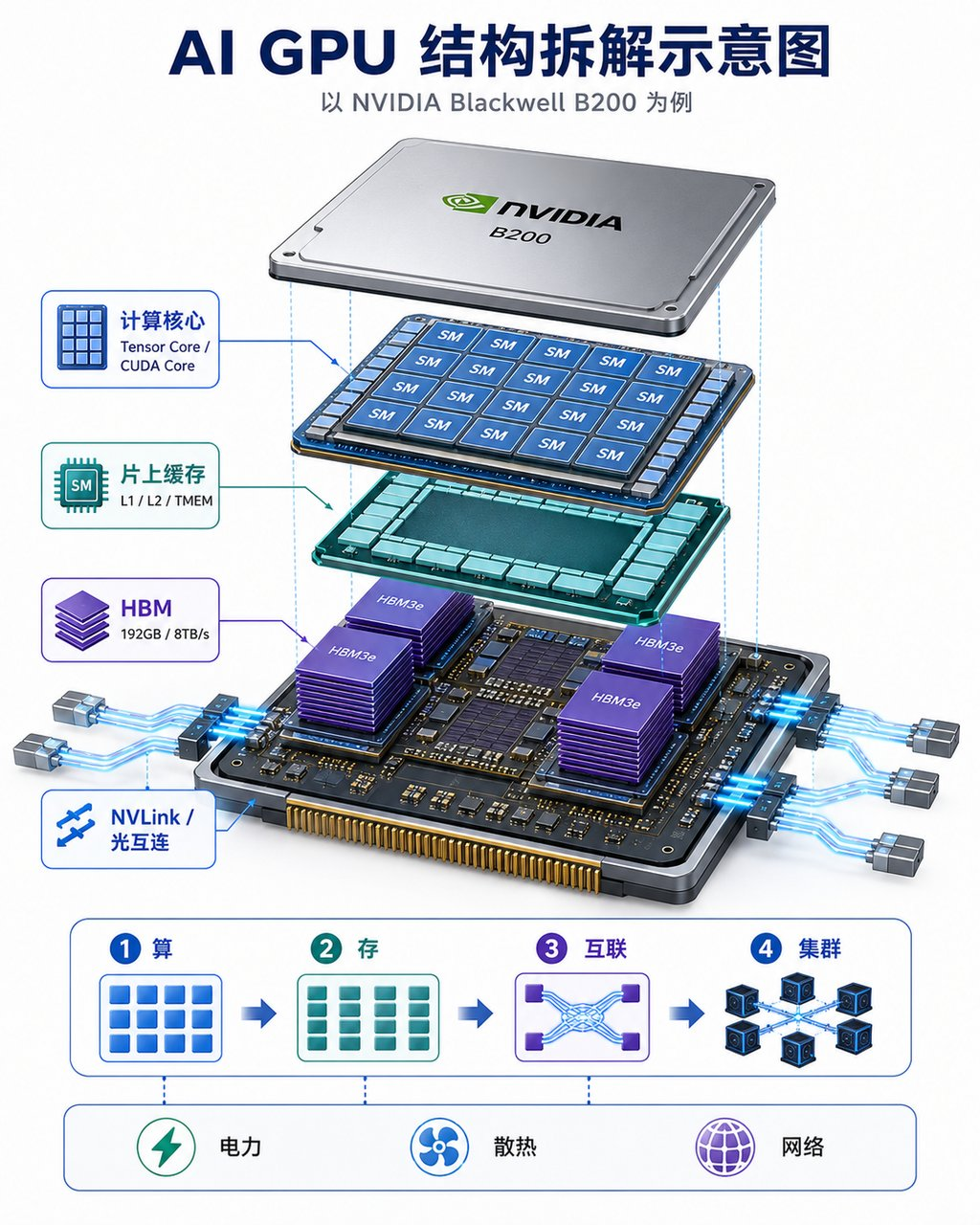
我们以NVIDIA Blackwell B200 GPU为例,从结构上看,B200 由两块 Blackwell die 组成,通过 NV-HBI 高带宽接口连接,die-to-die 带宽达到 10TB/s。整颗 GPU 拥有约 2080 亿个晶体管、148 个 SM、20,480 个 CUDA Core 和 1,024 个 Tensor Core,主要负责大模型中的矩阵运算。
在 GPU 内部,数据会按照距离计算核心的远近分层流动:
第一层是 Registers,也就是寄存器。它离计算核心最近,速度最快,用来保存正在计算的数据。
第二层是 L1 / Shared Memory。它位于每个 SM 内部,用来缓存短期、高频访问的数据,减少对更远内存的访问。
第三层是 TMEM,也就是 Tensor Memory。这是 Blackwell 针对 Tensor Core 引入的重要设计,用来让矩阵计算中的关键数据更靠近计算单元,提高 Tensor Core 的利用率。
第四层是 L2 Cache。B200 拥有约 126MB 的共享 L2 Cache,负责在多个 SM 之间缓存和复用数据,尤其适合推理场景中反复访问模型权重。
第五层是 HBM3e。B200 配备 192GB HBM3e,带宽约 8TB/s,是模型权重、KV Cache、激活值和输入数据的主要存储区域。对于大模型推理来说,尤其在 Decode 阶段,HBM 带宽往往直接决定 token 生成速度。
HBM 存放大规模模型数据,L2 / L1 / TMEM 负责把高频数据逐级送到计算核心,Tensor Core / CUDA Core 完成矩阵运算。计算结果再写回缓存或 HBM,并通过 NVLink / NV-HBI 与其他 GPU 协同工作。
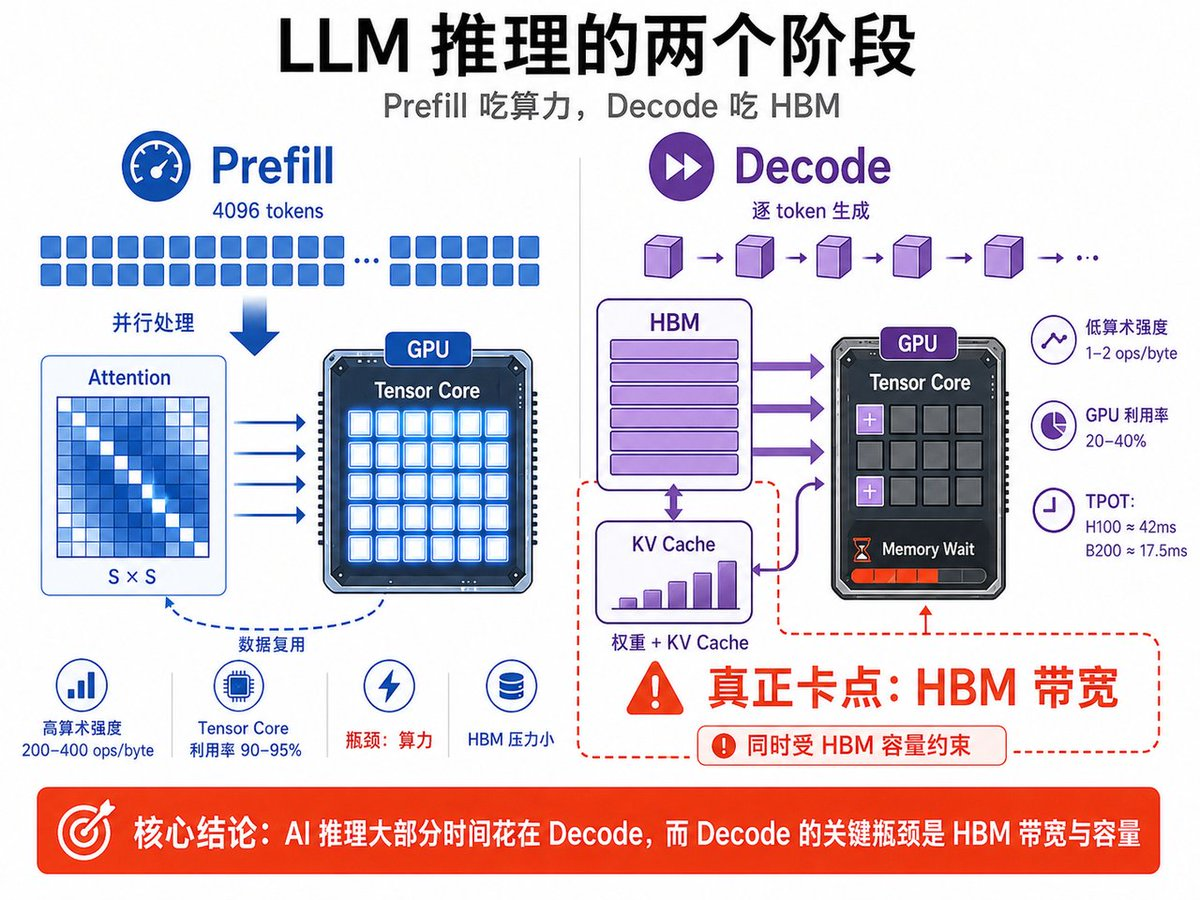
一块 GPU 在做 AI 推理的时候,处理一段 prompt 分成 两个阶段:Prefill 和 Decode ——可以粗暴地理解成" 读题 "和" 答题 "。
第一阶段:Prefill(上下文处理,也就是"读题")
你发一段 prompt 进去,比如 4096 个 token。模型第一件事,是把这 4096 个 token 同时全部读完,搞清楚每个 token跟其他所有 token 之间的关系。这件事叫注意力机制(Attention),它要计算一个 S × S 的矩阵,S 就是序列长度,这里 S = 4096。
GPU 里有一个专门做矩阵乘法的硬件单元,叫 Tensor Core,可以把它想象成"矩阵专用计算器"。这一阶段 Tensor Core 利用率高达 90-95%,全速干活。
这里有一个关键概念叫 arithmetic intensity(算术强度),意思是"每从内存读 1 个字节数据,能做多少次运算"。Prefill 阶段这个数字是 200-400 ops/byte,这个数据非常高,说明数据读进来一次,可以反复使用很多遍。
所以 Prefill 阶段的瓶颈是算力(FLOPS,每秒浮点运算次数),不是内存带宽,HBM 这时候 barely taxed 压力不大。
第二阶段:Decode(token 生成,也就是"答题")
Prefill 阶段结束后,模型会进入Decode 阶段,也就是逐 token 生成答案的阶段,模型通常采用 autoregressive,也就是“自回归”生成模式。
所谓自回归,就是模型不会一次性生成完整答案,而是一个 token 一个 token 地往外生成。每生成一个新的 token,都要基于前面已经生成的所有 token 再做一次计算。因此,对话越长,后续生成的计算负担就越重。
而GPU 每生成 1 个 token,都需要从 HBM 高带宽内存中读取两类关键数据: 第一类是模型权重,也就是模型本身的参数。
第二类是 KV Cache。KV Cache 是注意力机制留下来的中间结果缓存,其中 K 代表 Key,V 代表 Value。它的作用是避免模型每次都重新计算过去所有 token 的注意力结果,从而加速长文本生成。但代价是,随着上下文越来越长,KV Cache 会不断变大,占用越来越多的 HBM 容量和带宽。
举个例子,一个 70B 参数的大模型,如果用 FP16 精度存储,模型权重大约需要 140GB。也就是说,生成 1 个 token 时,仅仅为了完成一次 forward pass,也就是一次完整的前向计算,GPU 就需要从 HBM 中读取大约 140GB 的权重数据。
问题在于,Decode 阶段虽然要读很多数据,但真正需要做的计算并不多。这个时候,arithmetic intensity,也就是“算术强度”,会变得很低。
在 Decode 阶段,算术强度可能只有 1-2 ops/byte,也就是每读 1 个字节,只做 1-2 次计算。结果就是 Tensor Core 很快就完成了计算,但后续时间都在等待下一批数据从 HBM 送过来。
这也是为什么在大模型推理中,GPU 利用率经常只有 20%-40%。几万美元一颗的高端 GPU,很多时候并不是在满负荷计算,而是在等内存。
因此,Decode 阶段的性能瓶颈已经从 FLOPS,也就是理论算力,切换到了 HBM 带宽。
最直观的指标是 TPOT,全称 Time Per Output Token,意思是每生成一个输出 token 需要多少时间。
以 H100 跑 70B 模型为例,Decode 阶段的理论物理下限大约是 42 毫秒。这个数字主要由 H100 的 HBM 带宽决定。H100 的 HBM 带宽约为 3.35TB/s,如果每生成一个 token 需要读取约 140GB 数据,那么理论时间下限就是140GB ÷ 3.35TB/s ≈ 42ms
换到 Blackwell B200,HBM 带宽提升到约 8TB/s,同样读取 140GB 数据,理论下限变成:140GB ÷ 8TB/s ≈ 17.5ms
也就是说,Decode 速度提升约 2.4 倍, 主要来自 HBM 带宽提升。
那么,有没有办法缓解这个内存瓶颈?
最重要的方法是提高 batch size,也就是让 GPU 同时处理更多用户请求。因为模型权重可以在多个请求之间共享,GPU 读取一次权重,就可以同时服务多个用户。这样一来,每个用户、每个 token 分摊到的内存读取成本就会下降。
这也是为什么现代 AI 推理 serving 系统都在追求高并发和高 batch。Batch 越大,GPU 的计算单元越容易被填满,单位 token 成本也越低。
但 batch size 不能无限提高,因为更多并发请求会带来更大的 KV Cache。KV Cache 需要长期放在 HBM 中,所以 HBM 容量也变得非常关键。 带宽决定数据读取速度,容量决定同时能服务多少请求。
所以,AI 推理的核心瓶颈可以概括为:Prefill 阶段更吃算力,因为它要并行处理大量输入 token。Decode 阶段更吃 HBM,因为它要反复读取模型权重和不断增长的 KV Cache。
而在实际推理服务中,大部分时间都花在 Decode 阶段。 因此,决定推理效率的核心卡点就是HBM的带宽和容量。
这里我们对AI推理的经济学做个小结:
AI推理可以简化为一个核心等式:Token价格 ∝ (GPU成本 + 电力成本) / (每秒生成的Token数)
而每秒生成的Token数(Throughput)又直接受限于两个物理约束:
-
HBM容量 :决定单卡能装下多大的模型、支持多长的上下文、以及多大的Batch Size。
-
HBM带宽 :决定每生成一个token时,从HBM读取模型权重和KV Cache的速度。
在 Decode阶段 (逐token生成输出),GPU的算力利用率通常极低(<10%),因为大部分时间都花在 从HBM读取数据 上。这就是典型的 Memory-Bound(受内存带宽限制) 场景。此时,HBM带宽直接决定了Token生成速度——带宽翻倍,吞吐量近乎翻倍,单位Token成本近乎减半。
当模型参数量超过单卡HBM容量时,系统必须采用 模型分片(Model Parallelism) ,将权重分散到多张卡上。每生成一个token都需要跨卡通信,引入巨大的网络延迟和额外算力开销。OpenAI早期的GPT-4服务之所以响应慢、成本高,一个核心原因就是模型太大,不得不分散在大量GPU上,通信开销吞噬了效率。
因此, HBM容量和带宽的每一次跃升,都直接对应着Token推理成本的指数级下降 :
-
H100 → H200 :容量+76%,带宽+43% → 支持更大Batch和长上下文
-
B200 → Vera Rubin :容量不变(288GB),带宽 2.75倍 → Decode阶段吞吐量大幅提升
-
Rubin Ultra :容量 4倍 (1TB+)→ 可在单卡/单机架内装下万亿参数MoE模型,消除分片开销
NVIDIA声称Rubin可实现 10倍于Blackwell的每Token成本(TCO)降低 ,其本质来源正是HBM4带宽的跃升(减少Memory-Bound时间)+ FP4精度(减少数据搬运量)+ 更大容量(减少跨机通信)的三重叠加。
根据上述的半导体产业短缺逻辑, 按照AI 产业链的七个环节进行评估,按当前的紧缺程度得出一个半导体板块紧缺的产业图,其他板块的研究内容我们将后续陆续推出
存储板块全景:分类、技术代际、玩家清单
从 DRAM、NAND、NOR 到 HBM、HBF
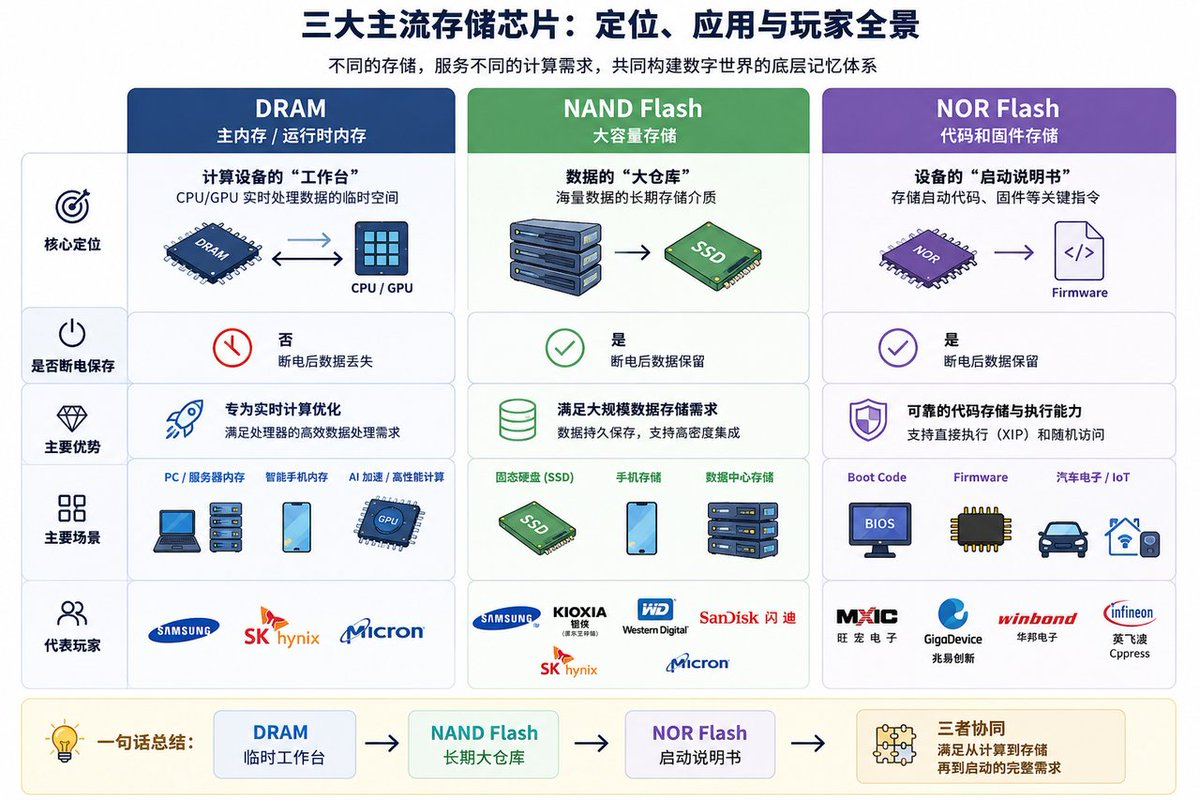
下面我们聊回到存储产业,存储芯片大体可以分成两类:一类是“运行时内存”,负责让 CPU、GPU 快速读取和处理数据;另一类是“长期存储”,负责在断电后继续保存数据。
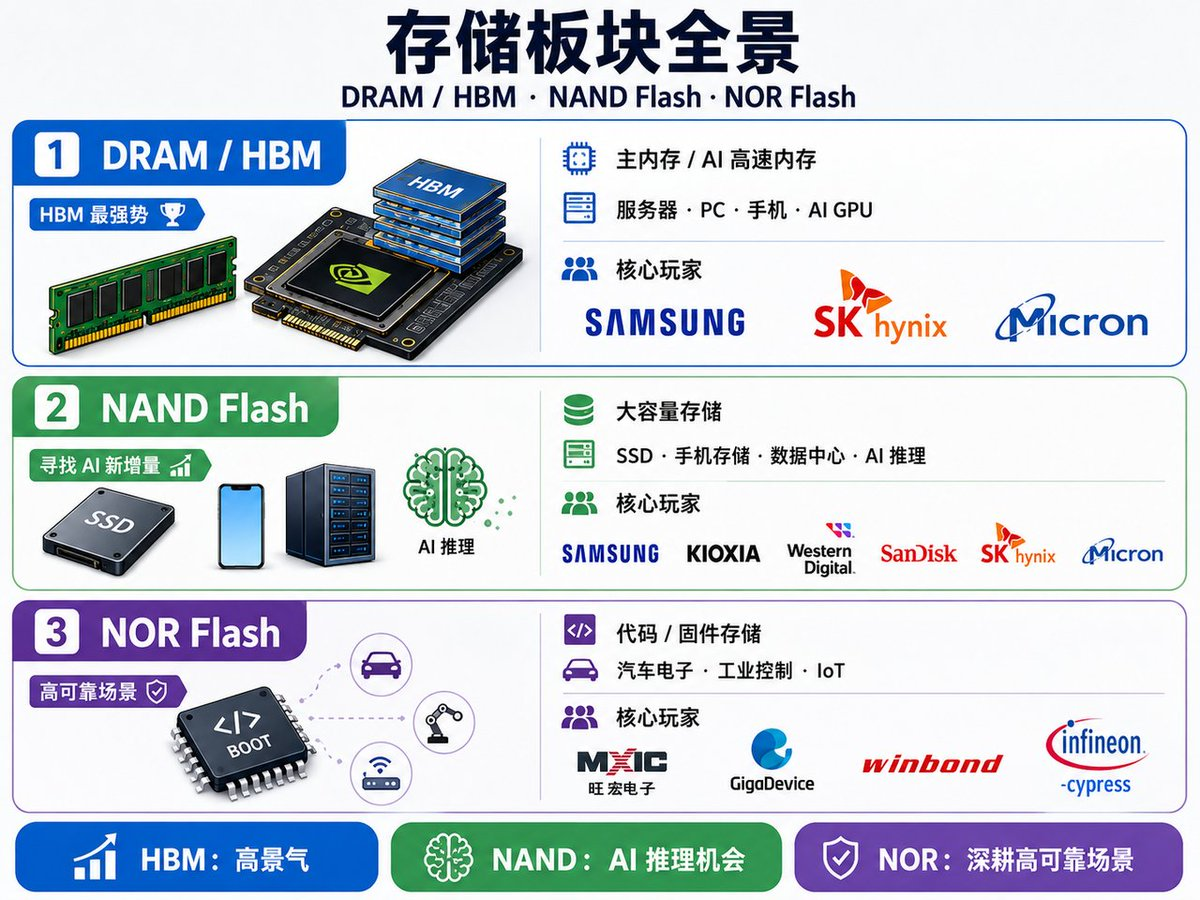
从产品分类看,最核心的三大传统品类是 DRAM、NAND Flash 和 NOR Flash。 进入 AI 时代后,HBM 成为 DRAM 中最重要的高端分支,而 HBF 则代表 NAND Flash 向高带宽、高容量 AI 推理场景延伸的新尝试。
传统存储三大类:DRAM、NAND、NOR
DRAM 是最典型的易失性存储,也就是断电后数据会消失的内存。它主要承担“运行时数据暂存”的角色,是 CPU、GPU 和其他计算芯片在工作时最依赖的主内存。
DRAM 的优势是速度快、延迟低,适合实时计算;缺点是成本较高、断电不保存数据。它的技术代际主要围绕带宽、功耗和容量演进,目前主流产品包括 DDR4、DDR5,以及面向图形和 AI 加速场景的 GDDR、HBM 等。DDR5 正在逐步替代 DDR4,成为服务器和高端 PC 的主流内存标准。
NAND Flash 是应用最广泛的非易失性存储,也就是断电后数据仍然可以保存。它主要用于 SSD、手机存储、U 盘、存储卡和数据中心硬盘。和 DRAM 相比,NAND 的速度慢很多,但容量更大、单位成本更低,因此更适合作为“大容量数据仓库”。
NAND 的技术演进主要有两条线:一是从 SLC、MLC、TLC 到 QLC,不断提升每个存储单元能存多少 bit;二是从 2D NAND 走向 3D NAND,通过垂直堆叠来提升容量。目前 200 层以上、300 层以上 3D NAND 已经成为行业竞争重点。NAND 的核心矛盾是容量、成本、性能和寿命之间的平衡。TLC 和 QLC 成本更低、容量更大,但写入寿命和性能相对弱于 SLC、MLC。
NOR Flash 也是非易失性存储,但它的定位和 NAND 完全不同。NOR 的特点是读取速度快、支持随机访问,可以直接执行代码,也就是 XIP,Execute In Place。因此,NOR 主要用于存放启动代码、固件和关键系统参数,比如手机、汽车电子、物联网设备、PC 主板和嵌入式系统中的 Boot Code、Firmware。
NOR 的容量通常不大,写入和擦除速度也不快,成本也高于 NAND,所以它不适合做大容量存储。但在设备启动、安全认证、汽车电子和工业控制等场景中,NOR 的可靠性和快速读取能力非常重要。随着汽车电子和物联网设备增加,高密度 NOR 仍有结构性增长空间。
简单来说,DRAM 负责“运行时计算”,NAND 负责“大容量保存”,NOR 负责“启动和固件”。
AI 时代最重要的存储分支:HBM
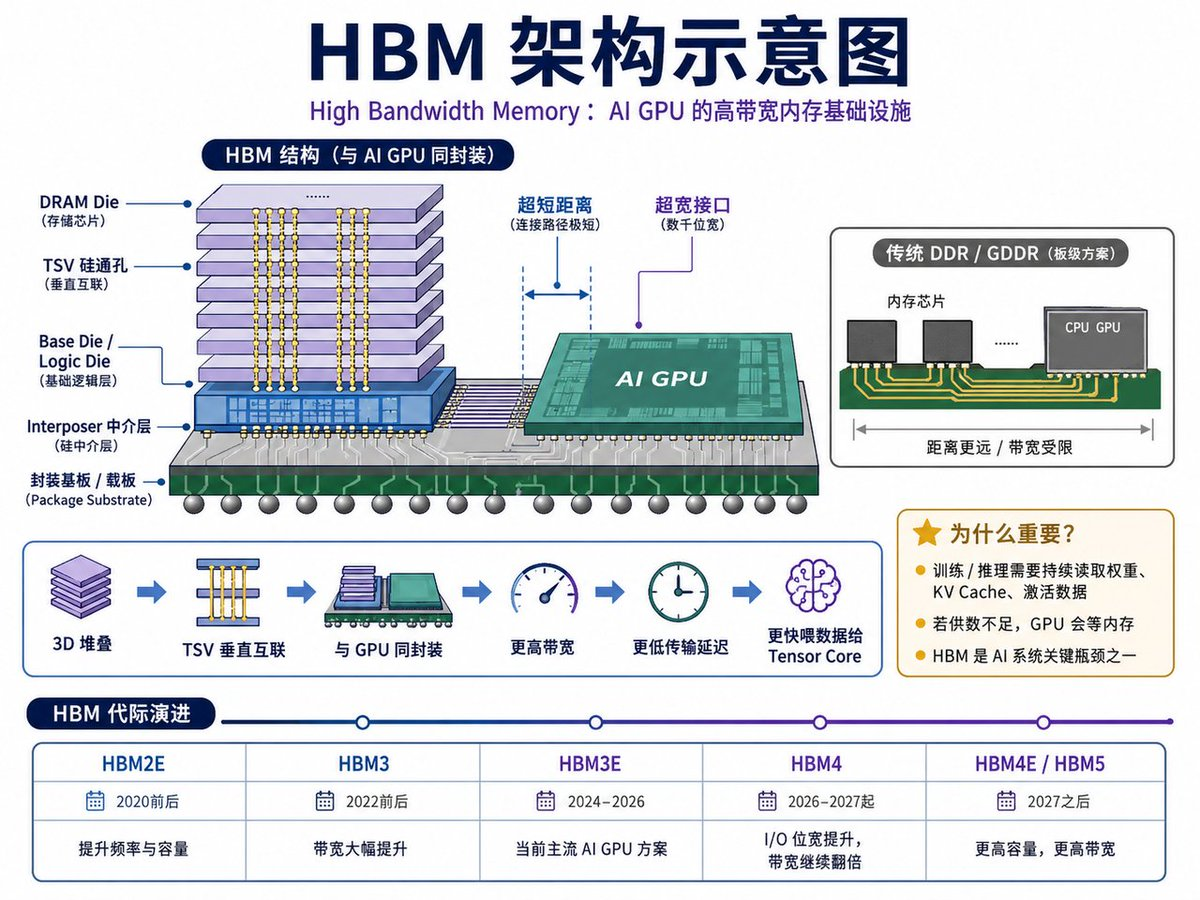
如果说传统 DRAM 是服务器和 PC 的主内存,那么 HBM 就是 AI GPU 的高端专用内存。HBM 的全称是 High Bandwidth Memory,高带宽内存。它本质上仍然属于 DRAM,但结构和封装方式与传统 DDR、GDDR 很不一样。
传统内存通常通过 PCB 走线与处理器连接,带宽提升会受到功耗、距离和信号完整性的限制。HBM 则采用 3D 堆叠结构,把多层 DRAM die 垂直堆起来,再通过 TSV,也就是硅通孔,进行垂直互联。随后,HBM 堆栈通过中介层 Interposer 和 GPU 放在同一个封装里,实现非常短距离、超宽接口的数据传输。
这带来了两个直接结果:第一,HBM 带宽极高;第二,HBM 离 GPU 很近,可以更快地把数据送到计算核心。对于大模型训练和推理来说,这一点非常关键。因为 AI GPU 的 Tensor Core 虽然算得非常快,但如果 HBM 无法及时提供模型权重、KV Cache 和激活数据,GPU 就会出现“等内存”的情况。
因此,HBM 已经成为 AI 算力系统中的核心瓶颈之一。特别是在大模型推理的 Decode 阶段,性能往往不再由 GPU 的理论 FLOPS 决定,而是由 HBM 的带宽和容量决定。带宽决定数据喂给 GPU 的速度,容量决定一张卡能放下多少模型权重、KV Cache,以及能同时服务多少 batch。
从技术代际看,HBM 的迭代节奏很快。HBM2E 主要用于早期 AI 加速和高性能计算;HBM3 在带宽上明显提升;HBM3E 是当前 AI GPU 的主流配置;HBM4 则会进一步提升 I/O 位宽、单堆栈带宽和容量,并引入更复杂的 base die 设计。未来 HBM4E、HBM5 会继续向更高带宽、更大容量演进。
NAND 的新方向:HBF
HBF(High Bandwidth Flash,高带宽闪存)是一种为 AI 推理而生的新型存储,可以把它理解为介于 HBM 和普通 SSD 之间的“中间层高速存储”。AI 模型越来越大,权重文件动辄上百 GB,甚至 TB 级别。HBM 带宽够快,但容量有限、价格昂贵;SSD 容量足够,但速度和延迟又跟不上高性能推理的节奏。HBF的出现,就是为了解决这个矛盾。
它借鉴 HBM 的 3D 堆叠和高速互联技术,把多层 NAND Flash die 垂直叠起来,通过高速通道连接,从而既拥有比普通 SSD 高得多的带宽,又保持大容量特性。它不是为了取代 HBM,而是作为“近线高速存储层”,专门存放大模型的权重,让 GPU 在推理时不再频繁等待数据。
到 2026 年,HBF 已经进入工程样片阶段,厂商计划下半年开始交付样片,并在 2027 年看到首批商用参考设计。预计 2028 年后才会大规模量产。它的意义在于,AI 推理服务器可以用比全 HBM 方案更低的成本,同时获得接近 HBM 的带宽和容量,让大模型加载更快、吞吐更高。
玩家清单:谁在存储产业链中占据关键位置
从全球格局来看,存储行业高度集中,但不同产品线的竞争格局差异明显,每类玩家都有其核心优势和战略重点。
DRAM 和 HBM 领域 :三星、SK 海力士和美光是绝对的核心玩家。DRAM 仍是服务器、PC 和移动设备的主内存,而 HBM 则是 AI GPU 的关键高速内存。三星擅长整体工艺和封装整合,尤其在 3D 堆叠和 TSV 可靠性上有优势;SK 海力士凭借与 NVIDIA 的深度绑定和量产先发优势,占据 HBM 市场超过半壁江山;美光则在 HBM3E 和 HBM4 工程样片上快速跟进,尤其在大容量堆叠和可靠性优化上进展明显。
对于 HBM,竞争不仅是 DRAM 制程,更多还在 TSV 堆叠、封装良率、测试流程、客户认证以及长期供货能力。拿到 NVIDIA、AMD、Google 等 AI 芯片大订单,就意味着在当前 AI 存储超级周期中拥有定价权和产能保障。
NAND Flash 领域 :核心玩家包括三星、铠侠/西部数据、闪迪、SK 海力士和美光。过去 NAND 市场主要被消费电子、SSD 和数据中心需求驱动,而随着 AI 推理需求增长,高带宽 NAND 或 HBF 技术的开发,为厂商提供新的增长机会。三星在高密度 3D NAND 和企业级 SSD 上仍保持领先,铠侠/西部数据在存储规模和可靠性方面优势突出,闪迪则专注 HBF 和高带宽闪存原型,快速布局 AI 推理市场。SK 海力士和美光也在积极跟进高带宽 NAND 方案,争夺 AI 数据中心市场份额。
NOR Flash 领域 :主要玩家包括旺宏、兆易创新、华邦电和英飞凌/Cypress。NOR 市场规模不如 DRAM 或 NAND,但应用分散且对可靠性要求高。它主要用于汽车电子、工业控制、物联网和嵌入式系统,负责启动代码、固件和关键参数存储。中国厂商在 NOR 领域相对竞争力突出,兆易创新在高密度 NOR 和汽车级应用上不断突破,市场份额稳步增长。
综合来看,存储板块可以按照 AI 半导体链条分为三层:
-
高端 AI 内存玩家 :HBM 核心供应商,如 SK 海力士、三星、美光,主攻 GPU 高带宽内存和大模型训练需求。
-
大容量存储玩家 :NAND 和 SSD 厂商,如三星、铠侠/西部数据、闪迪、SK 海力士、美光,未来 HBF 的落地将为这些厂商打开 AI 推理市场的新增长点。
-
嵌入式和控制类存储玩家 :NOR Flash 供应商,如旺宏、兆易创新、华邦电、英飞凌/Cypress,专注工业、汽车、物联网等可靠性要求高的场景。
这一格局显示出存储产业链在 AI 驱动下的分层趋势:HBM 代表高端算力支撑,NAND/HBF 代表大容量与高带宽结合,NOR 保障嵌入式与工业控制的稳定性。随着 HBF 等新技术推进,NAND 和 AI 推理存储市场的格局可能发生新的变化。
关于每个公司的具体财务分析和业务深度研究我们将在后文详细展开。
供需格局深度分析:15年来最严重的结构性短缺
当前全球存储芯片市场正经历着由多重需求叠加驱动的历史性繁荣,其核心引擎是 AI 的爆发。AI 训练、AI 推理、以及全球数据中心大规模扩张三重力量交织强化,共同构成了对存储芯片"无底洞"式的需求。三层引擎的传导逻辑不同,但方向完全一致。
需求侧
引擎一 AI 训练——参数军备竞赛驱动 HBM 容量膨胀
大语言模型的参数规模正从数百亿向万亿级别加速演进。每一次迭代不是线性的——GPT-4 约 1.8 万亿参数(MoE 架构),下一代模型的目标是 10 万亿+。训练这样的模型需要在数千甚至数万张 GPU 上并行数月。
但训练真正的瓶颈是 GPU 和 HBM 之间的带宽 。每张 GPU 在训练时,需要把梯度、优化器状态、激活值在 HBM 里反复读写。HBM 容量不够 → 无法装下完整的模型状态 → 必须跨 GPU 通信 → 通信开销吃掉计算收益。
所以 NVIDIA 的每一代 GPU,HBM 容量都在跳升:
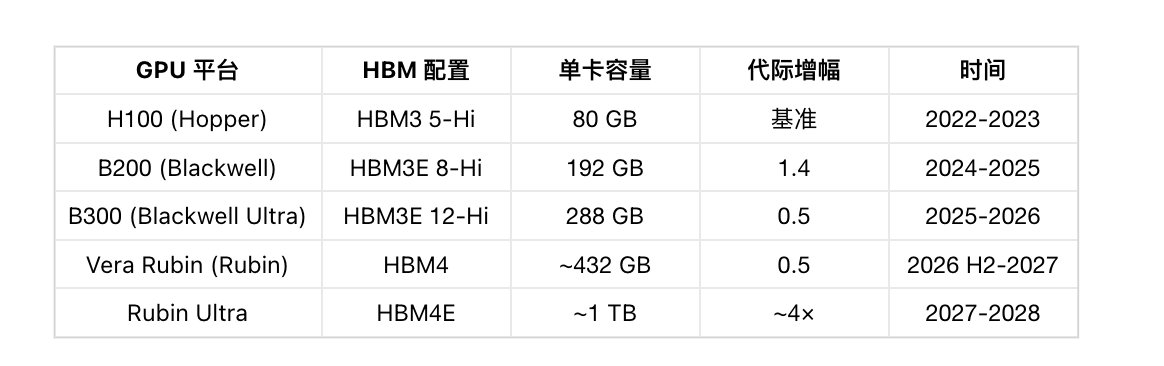
从 H100 到 Rubin Ultra,单卡 HBM 容量从 80 GB 飙到 ~1 TB, 四年翻了 12.5 倍 。
而且不光是 NVIDIA。Google TPU v8AX、Amazon Trainium3 也在从 HBM3E 8-Hi 升级到 12-Hi。AMD MI350→MI400,HBM 容量从 288 GB 跳到 432 GB。整个 AI 加速器行业都在同一方向上狂奔。
训练环节对存储的需求是全栈的:
-
HBM :GPU 的"工作台",训练过程的全部中间状态都在这里。HBM 不够 → 无法训练大模型。
-
NVMe SSD :训练数据集动辄数十 TB(比如 Llama 3 训练用了 15T tokens 的数据),必须高速喂给 HBM。数据加载的瓶颈会直接拖长训练时间——如果 SSD 带宽跟不上 GPU 的消耗速度,几万张 GPU 就闲着等数据。
-
HDD :冷数据存储。训练完成后的模型权重、历史 checkpoint、原始语料库都需要长期保存。
引擎二:AI 推理——规模效应让存储需求"长尾化"
推理的单次计算复杂度确实远低于训练,但它的需求特征完全不同: 训练是爆发式的集中消耗,推理是持续膨胀的长尾吞噬 。
几个关键数字需要修正传统认知:
推理已经不是"小头"了。 2026 年,推理占 AI 计算总量的 66%,两年前这个数字还只有 33%。推理和训练的位置已经彻底反转。随着 Agentic AI(能自主调用工具、多步推理、多 Agent 协作的 AI)爆发,推理的占比只会继续上升。
单次推理的内存需求被严重低估。 一个前沿 LLM 的模型权重占 100-200 GB(FP16 精度),KV Cache 还要再吃同等甚至更多的内存。KV Cache 有一个简单粗暴的规律: 每次上下文 Token 翻倍,KV Cache 占用的内存也翻倍 。Agentic 工作负载的上下文通常很长(多轮对话、代码库上下文、文档检索),KV Cache 的压力远超单纯的 Chatbot。
GPU 推理时的角色分工:

Agentic AI 绝大多数时间在 Decode。这就是为什么 HBM 的带宽决定推理速度,HBM 的容量决定能同时服务多少用户 。
规模效应才是真正的故事。 一台训练集群需要几千张 GPU,但推理部署可能需要几十万甚至上百万张。Anthropic 的 ARR 从 $90 亿涨到 $300 亿只用了 4 个月。
Anthropic 自己说:如果有更多 GPU,ARR 还能更高。他们在 GPU 上受限于 HBM 供给。
推理对存储的全栈需求:
-
HBM :GPU 推理的核心瓶颈(带宽 + 容量)。Agentic 推理的长上下文 + KV Cache 让这个瓶颈持续恶化。
-
企业级 SSD :模型权重落盘、KV Cache 卸载到 SSD(长上下文策略)、用户数据存储。企业级 SSD 月环比涨 140%。
-
HBF(高带宽闪存) :闪迪和铠侠合作的下一代产品,单堆栈 512 GB,模块 4 TB,专为推理权重存储设计。2027 年初量产。如果成功,推理的内存层级会被重写,HBM 管速度,HBF 管容量。
引擎三:数据中心扩张——存储价值的"放大器"
Hyperscaler 的 CapEx 狂飙不只是为了 AI。传统云计算、大数据、流媒体也在增长。但 AI 改变了数据中心的存储结构。
几个具体数据点:
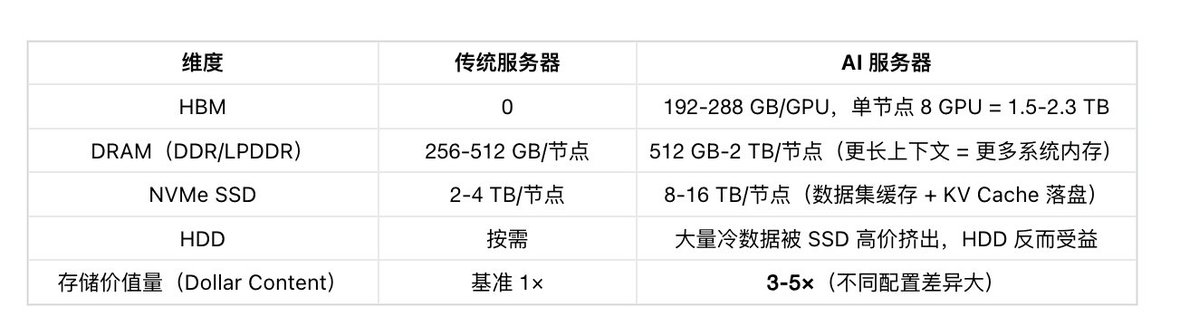
-
2026 年数据中心吃掉全球 DRAM 产能的 ~70% (SemiAnalysis),其中服务器 DRAM 约 40%,HBM 约 10%+ 且快速上升
-
希捷 2026 财年 Q3 数据中心出货占 88%,近线 HDD 产能 2026-2027 全部售罄,2028 年订单已在谈
-
铠侠(Kioxia)2026 年 NAND 产能已被客户 100% 预订
-
NVIDIA Vera Rubin NVL72 系统,内存需求从 Blackwell NVL72 的级别大幅跳升(SOCAMM LPDDR5-based 内存成为新增长点)
HDD 的意外回归是一个特别有意思的副作用:企业级 SSD 太贵了(月环比 +140%),大量冷数据被从 SSD 推回 HDD。AI 推理时代,存算分离的经济性让 HDD 反而找到了新的生存逻辑——近线 HDD 需求爆发,希捷净利润同比 +248%。
三重引擎的交叉验证
总结一句话: 训练定义了 HBM 容量的上限,推理定义了 HBM 需求的广度,数据中心扩张提供了需求总量的底盘 。三道力量没有一道在减速,而供给端(详见下一节)是一个"铁笼"。这就是这一轮存储行情的底层叙事。
供给侧:HBM产能挤压与2-3年的产能建设周期
面对需求侧的爆炸性增长,存储芯片的供给侧却面临着前所未有的结构性制约,无法快速响应市场变化,这是导致当前全球存储芯片严重短缺、价格飞涨的根本原因。供给侧的核心问题可以归结为两点:一是 HBM生产对传统DRAM和NAND产能的巨大挤压效应 ,二是 存储芯片产能建设固有的2-3年长周期 ,导致供给弹性极低。
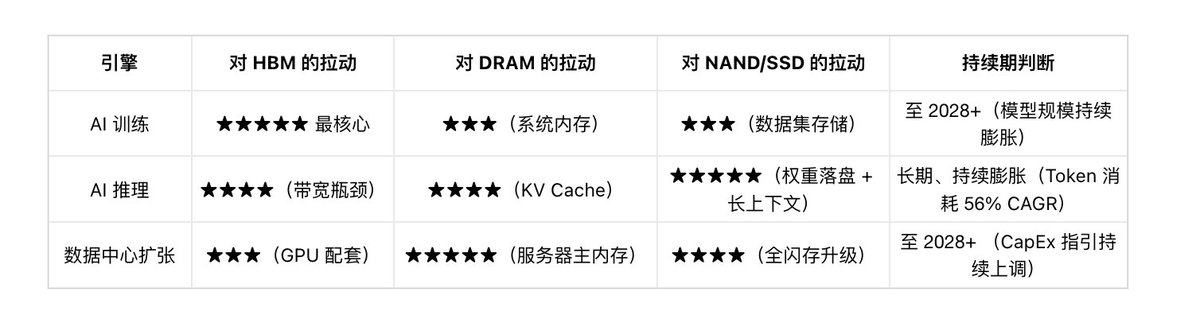
根据Semianalysis估计,HBM wafer 产能占三星、SK Hynix 和美光总 DRAM wafer 产能的比例,在 2022 年还不到 5%,但到 2025 年底已经上升到约 20%。到 2027 年底,这个比例可能达到约 35%。
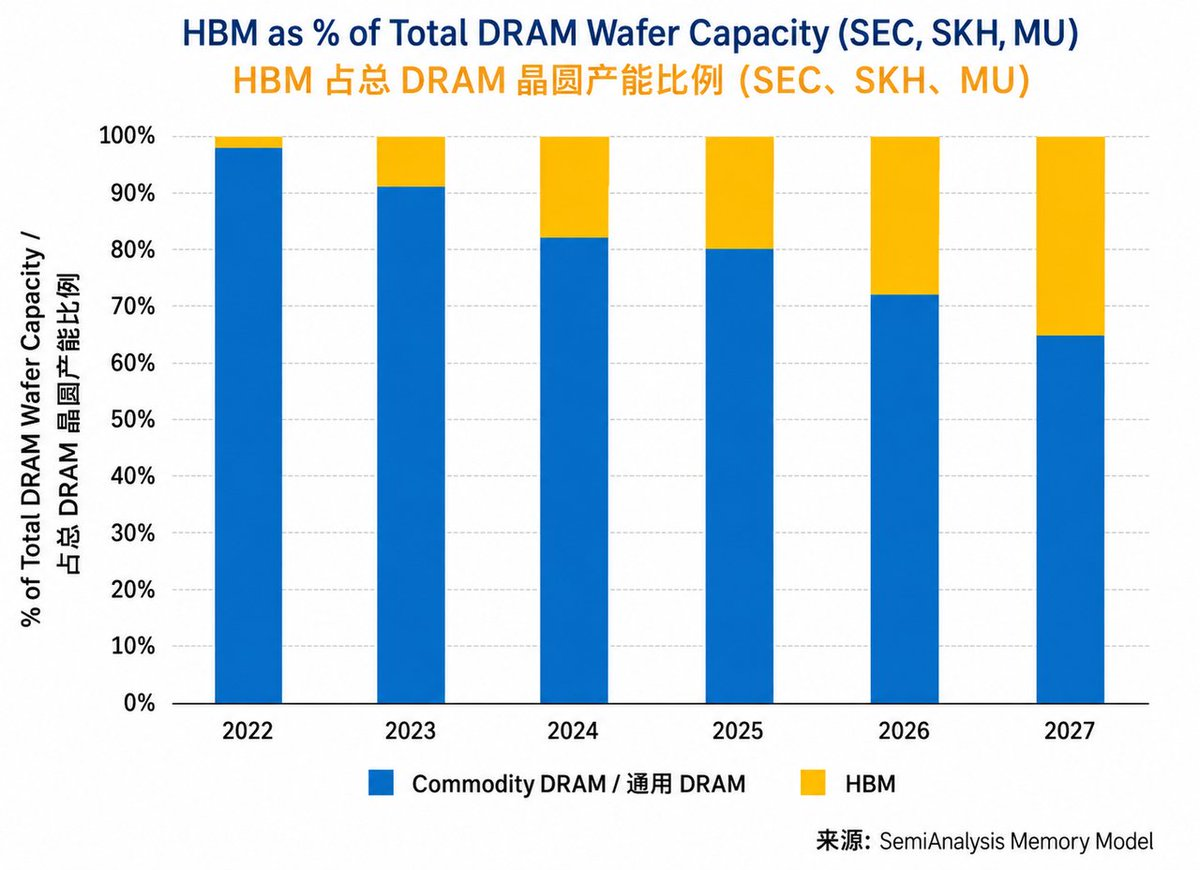
首先,HBM作为当前存储市场的“香饽饽”,其生产过程异常复杂且“吞金”。如前所述,HBM采用3D堆叠和TSV(硅通孔)技术,将多颗DRAM裸片垂直封装在一起。这种复杂的封装工艺不仅技术门槛高、良率爬坡慢,而且其 晶圆消耗量是同价值传统DRAM产品的3到4倍 。这意味着,生产一颗价值100美元的HBM,需要消耗掉原本可以生产3-4颗标准DRAM芯片的晶圆产能。
这种产能的结构性转移造成了严重的连带效应。据统计,为了保障HBM的出货,三星将其约30%的消费级DRAM产能转向了HBM,SK海力士的转移比例更是高达40%,而美光也转移了约25%的产能。这些数字是相当惊人的,它直接导致全球标准DRAM的可用产能大幅减少。
与此同时,由于 HBM的封装需要先进的封装产线(CoWoS等) ,这些产能也被大量占用,进一步限制了其他先进封装业务。这种由HBM引发的“虹吸效应”,使得原本供需相对平衡的DDR4、DDR5以及NAND Flash市场,在短时间内陷入了严重的供不应求状态。例如,随着DDR4产能被大量削减,其价格在2025年下半年出现了惊人的上涨, 涨幅一度高达1800% ,这充分说明了产能挤压的严重程度。
由此我们可以看出,这轮周期的独特之处在于:推动需求增长的产品转换,也就是 HBM,本身制造强度更高,实际上引入了一种 reverse scaling(反向扩展需求)。即过去的计算平台拐点,比如 PC、手机、云计算,主要是扩大需求,并不会明显压缩供给。但这一次,AI 驱动下向 HBM 的迁移,一方面提高需求,另一方面由于HBM的制造难度超过传统DRAM,而变相体现为收紧供给。
其次,半导体产能的建设周期是存储供给侧的另一大硬约束。
从决定投资新建一座晶圆厂(Fab),到最终能够产出合格的芯片,通常需要经历长达 2到3年 的时间。这个过程包括厂房建设、洁净室装修、天价设备(如EUV光刻机)的采购、安装与调试,然后是漫长的工艺研发和良率爬坡。
在当前的市场环境下,即使三大原厂明天就决定大举投资扩建DRAM产能,这些新增产能最早也要到 2027年底或2028年初 才能实际进入市场。更重要的是,面对AI带来的结构性机遇,原厂们的资本开支策略也变得更加审慎和聚焦。它们更倾向于将宝贵的资本开支投入到利润更高、增长前景更确定的HBM和先进DRAM技术上,而不是去大规模扩建已经相对成熟、利润较薄的传统NAND Flash产能。
例如,SK海力士计划在美国印第安纳州新建一座专注于AI存储器(包括HBM)的先进封装厂,美光则计划投资数百亿美元在美国爱达荷州和纽约州新建晶圆厂,这些投资都指向未来的HBM和先进DRAM产能,而非解决当前的传统存储短缺问题。因此,至少在2027年底之前,市场几乎看不到能够显著缓解当前供需紧张局面的新增供给。这种供给的刚性,与需求的弹性形成了鲜明对比,共同将存储行业推向了一个“超长待机”的超级周期。
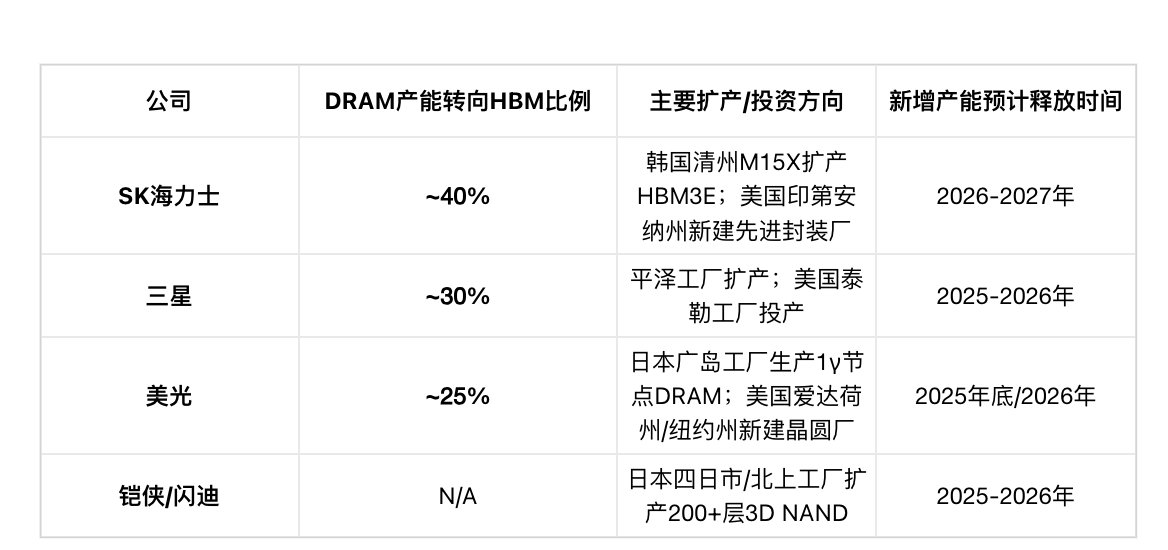
Table 3: 主要原厂产能转移与扩产计
根据估计,从 2025 年四季度末到 2027 年四季度,三大厂合计 1b 和 1c 产能会增加约 80%;到 2026 年底,三星和 SK Hynix 接近 30% 的 DRAM wafer 生产会转到 1c,美光也会把约 30% 的 DRAM 生产转到对应的 1γ 节点。
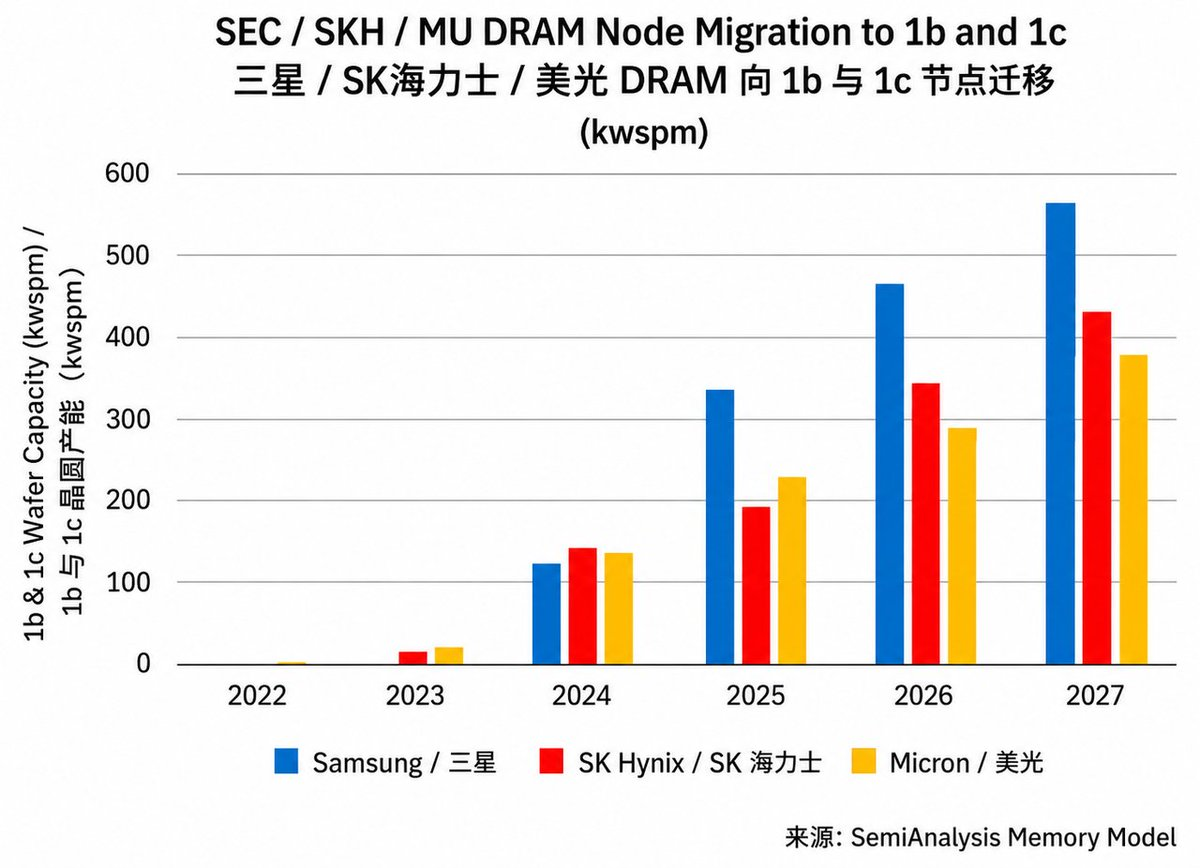
2026 年实际新增晶圆产量有限且主要集中在 HBM, NAND 几乎没有实际晶圆增量。
根据 SemiAnalysis 数据,预计2026 年几乎所有新增的晶圆产能都将集中在三家晶圆厂:
三星的 P4(主要是第一阶段和第三阶段,第四阶段在26 年底的投入有限)、SK 海力士的M15X 以及美光的 A3。
供需缺口量化:高盛预测2026年DRAM供应缺口达4.9%
当前存储市场的供需失衡已经达到了一个极为严重的程度,多家顶级投资银行的量化分析为这场“超级周期”的强度提供了坚实的证据。 高盛(Goldman Sachs) 在2025年年中发布的一份深度研究报告中,明确指出当前的存储芯片市场正经历着 过去15年以来最严重的供需失衡 。该报告通过对全球DRAM和NAND Flash的供给与需求进行详细建模,预测出惊人的缺口数据。 对于DRAM市场,高盛预测在 2026年和2027年 ,供应缺口将分别达到 4.9%和2.5% 。这意味着全球对DRAM的总需求将超过总供给的近5%,在一个以百万片晶圆为计量单位的市场中,如此大规模的短缺是极为罕见的,足以引发价格的持续、大幅上涨。对于NAND Flash市场,情况同样不容乐观,报告预测其也将处于短缺状态,尽管缺口略小于DRAM,但结合其巨大的市场体量,其对整个行业的影响同样深远。
这份报告的量化分析深刻揭示了失衡背后的结构性原因。高盛的模型充分考虑了HBM产能扩张对传统DRAM产能的挤压效应,以及原厂资本开支转向的滞后性。报告认为,尽管原厂已经意识到市场的紧张并开始增加投资,但由于2-3年的产能建设周期,这些投资在短期内无法转化为有效供给。因此,供需缺口将在未来一到两年内持续存在,甚至可能进一步扩大。
根据 SemiAnalysis 的 Memory Industry Model测算,DRAM市场供需失衡正在恶化。2026 年整体 DRAM 供给预计将比需求低约 7%。
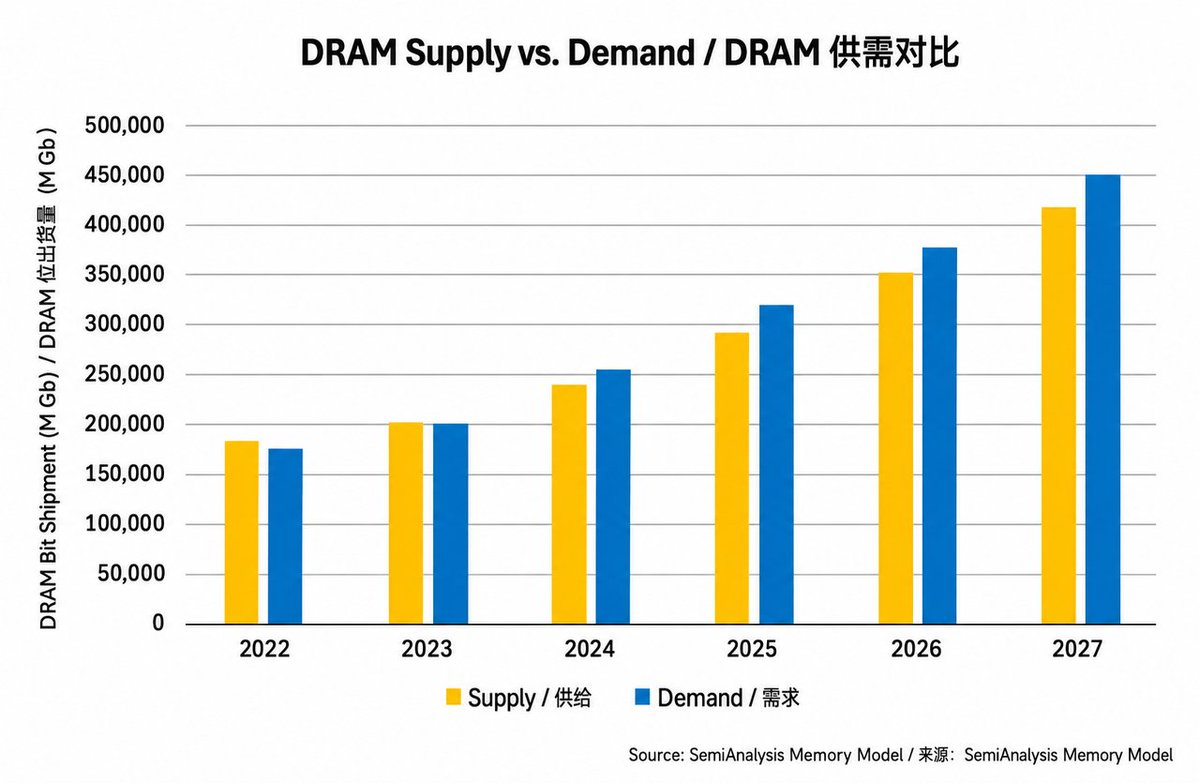
在这个整体缺口中,HBM 的供给缺口预计会从今年约 5%,扩大到 2026 年约 6%,并在 2027 年进一步扩大到约 9%。
这些量化数据不仅是对当前市场状况的描述,更是对未来价格走势和原厂盈利能力的强有力预测。在严重的供不应求的市场中,定价权完全掌握在原厂手中。客户,尤其是那些需要保证稳定供应的云服务商和AI公司,为了确保能够获得足够的芯片,愿意接受更高的价格,并签署长期的供应协议。
库存现状:库存周转天数降至历史极低位
库存水平是判断存储芯片行业周期位置最灵敏、最直接的先行指标之一。在正常的行业周期中,下游客户(如PC厂商、手机制造商、服务器品牌商)通常会维持大约 12到16周(84-120天) 的库存,以应对需求波动和供应链的不确定性。然而,在当前这场超级周期中,库存已经不是一个简单的缓冲,而是一个反映市场极度饥渴状态的“晴雨表”。当前整个存储产业链的库存水平已经降至 历史性的极低位置 。
我们把库存分成四层来分析:
第一层:DRAM/HBM 原厂(三星 / SK海力士 / 美光 / 南亚科)
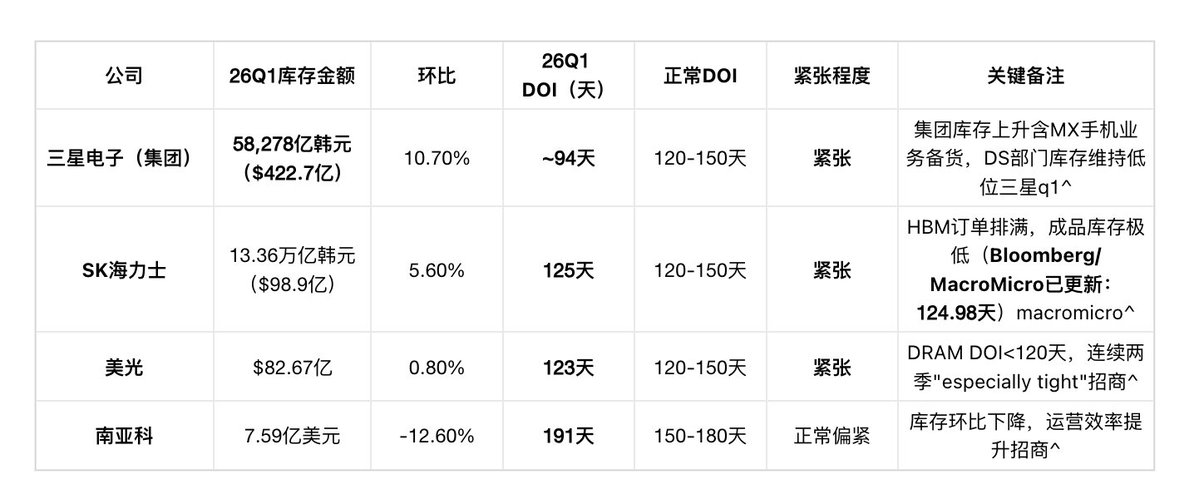
注: Bloomberg口径的DOI是总库存(含在制品、原材料、成品),而SK海力士在2026年2月高盛虚拟投资者会议上自行披露的 约4周(28天) 仅指DRAM和NAND 成品库存 。Bloomberg/MacroMicro最新更新(DART 5/15截止后)显示SK海力士总库存DOI为 124.98天 (25Q4为143天),26Q1环比下降18天——成品库存极低,大量晶圆卡在HBM的TSV穿孔/堆叠产线上。SK海力士在同一场会议上直言:" No customer can fully meet their memory demand this year. "美光在Q1 FY2026(2025年12月)和Q2 FY2026(2026年3月)财报电话会上连续两个季度确认DRAM库存天数"remain tight and below 120 days",Q2进一步用了" especially tight "的表述。
HBM的TSV穿孔、晶圆减薄、12层堆叠和测试流程极长,大量晶圆卡在产线上,成品则是 下线即拉走 。这是一个非常危险的信号,意味着公司的成品库存几乎在出厂的同时就被客户拉走,几乎没有多余的备货。这种“手牵手”式的供应状态,表明市场需求远比官方订单数据显示的更为强劲,因为客户也在消耗自己的安全库存。
第二层:FLASH / HDD 原厂(闪迪 / 西部数据 / 希捷)
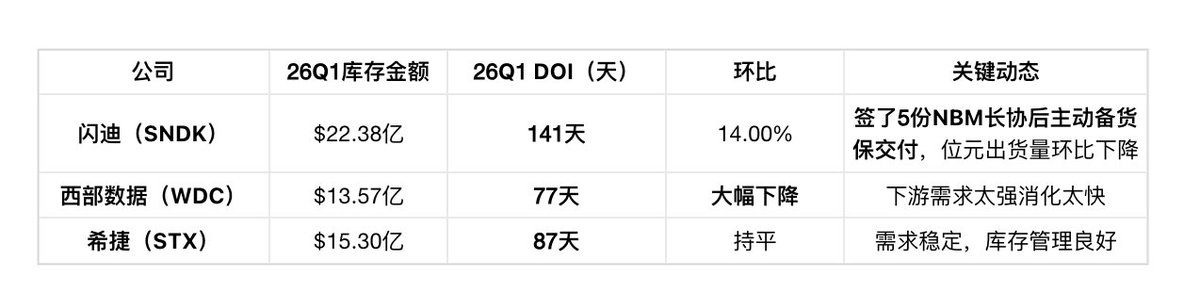
三家走向不同: 闪迪在涨库存 (签了NBM长协后主动备货), 西部数据在降库存 (DOI 77天环比下降,需求太强消化太快), 希捷在中间 (87天稳定)。
第三层:台湾模组厂和利基厂
台厂模组厂26Q1全面加码备货。 群联电子 库存突破500亿新台币,与一线CSP/OEM签了LTA。 威刚 目标6月底库存拉升至500亿新台币以上。 十铨 公告"DRAM与NAND需求预期维持强劲,将透过长期采购策略确保稳定供货"。
利基厂方向相反—— 华邦、旺宏、晶豪科 的库存和DOI环比均在下降(华邦DOI 145天、旺宏163天、晶豪科210天,均环比下降)。利基产品(尤其eMMC)缺货更严重,厂商没有余力囤货。
第四层:大陆模组厂
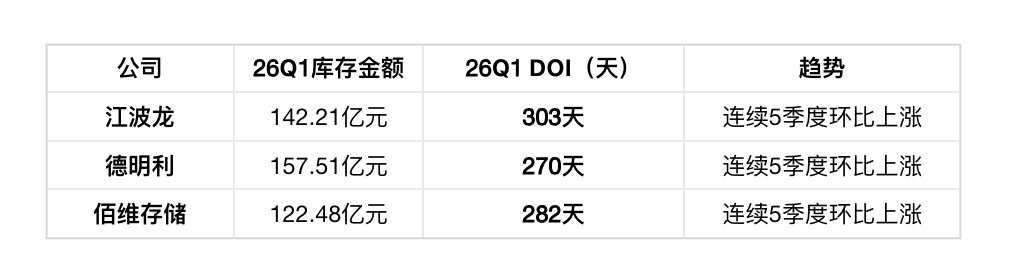
三家合计422.2亿元,平均单月利润约10亿元,有充分资金支撑囤货策略。大陆利基型厂商(兆易、普冉、东芯、君正、聚辰、恒烁)合计库存连续8个季度环比上涨,但增速远低于模组厂,DOI趋势向下(175-453天区间内改善)。
长协锁单对库存行为的重塑
四层数据并在一起,产业链库存的结构是清晰的:
-
原厂成品库存4周级别 ,供给端零缓冲
-
中游模组厂在主动建库存 ,锁未来供应,赌继续涨价
-
下游客户签LTA和长协 :闪迪5份NBM覆盖2027财年超1/3位元产量,含逾110亿美元财务担保;美光签了首份五年期SCA
-
HDD的LTA已延伸至2028-2029年
在这种极低的库存环境下,一种名为 “重复下单”(Double Ordering) 的现象开始在市场上蔓延。由于客户担心无法拿到足够的芯片,他们可能会向多家供应商下达超过其实际需求的订单,以确保最终能获得满足生产所需的最低数量。这种行为在短期内人为地放大了市场的需求信号,使得厂商看到的订单数据可能比真实需求更高,从而进一步推高价格预期和厂商的扩产意愿。
风险同样明确。 一旦供给释放,这些囤积库存会从需求侧瞬间翻转为供给侧。Double Ordering的真实规模难以拆解,所有人都在抢产能的时候,真实需求和恐慌锁单的边界是模糊的。
尽管券商报告强调,NAND现货过去一个月跌了30-40%,主因是贸易商资金周转压力下降价变现和买方消化库存。但TrendForce仍预期Q2传统DRAM合约价环比+58-63%,NAND合约价环比+70-75%,涨势未逆转。
因此,当前的低库存状态既是当前超级周期强度的体现,也蕴含着未来市场波动加剧的风险。对于投资者而言,密切跟踪库存周转天数的变化,是判断周期何时接近顶峰的最重要信号之一。当库存开始从底部回升,并持续超过 120天(DRAM/HBM紧张线) 或 150天(正常线) 的正常水平时,就可能意味着供需关系正在发生微妙的转变。
拐点判断:产能利用率、现货价格、合约价格与库存天数四大核心指标
在存储芯片这个强周期性行业中,精准判断周期拐点(无论是顶峰还是谷底)是投资成败的关键。尽管本轮由AI驱动的超级周期被许多人认为具有“结构性转变”的意味,但行业固有的周期性规律并未完全消失。因此,建立一套行之有效的监测体系,跟踪核心指标的变化,对于及时捕捉周期转向的信号至关重要。

当“现货回调+合约继续上行”同时出现时,不必然意味着价格见顶,反映了结构性紧缺的确认。当前(2026年5月)正处于这种状态。
-
合约反映真实供需 :合约市场参与者是CSP和OEM等大客户,反映真实生产需求;现货市场以贸易商为主,容易受情绪影响
-
长协锁定价差 :美光签署5年SCA、闪迪签署5份NBM(覆盖2027财年超1/3位元产量)、西部数据/希捷LTA延伸至2028-2029年——这些长协价格不受短期现货波动影响
-
产能分配机制 :原厂优先满足高价值合约客户,缩减PC/消费级供货——合约价持续上行而现货价回调,恰恰证明结构性紧缺在加剧
当“合约价格连续两季环比涨幅<10%”+“库存天数持续回升突破180天”+“产能利用率从>95%回落至<90%”三个条件 同时满足 时,才是确认周期见顶的信号。当前三个条件均未触发。
指标一:产能利用率(26Q1最新数据)
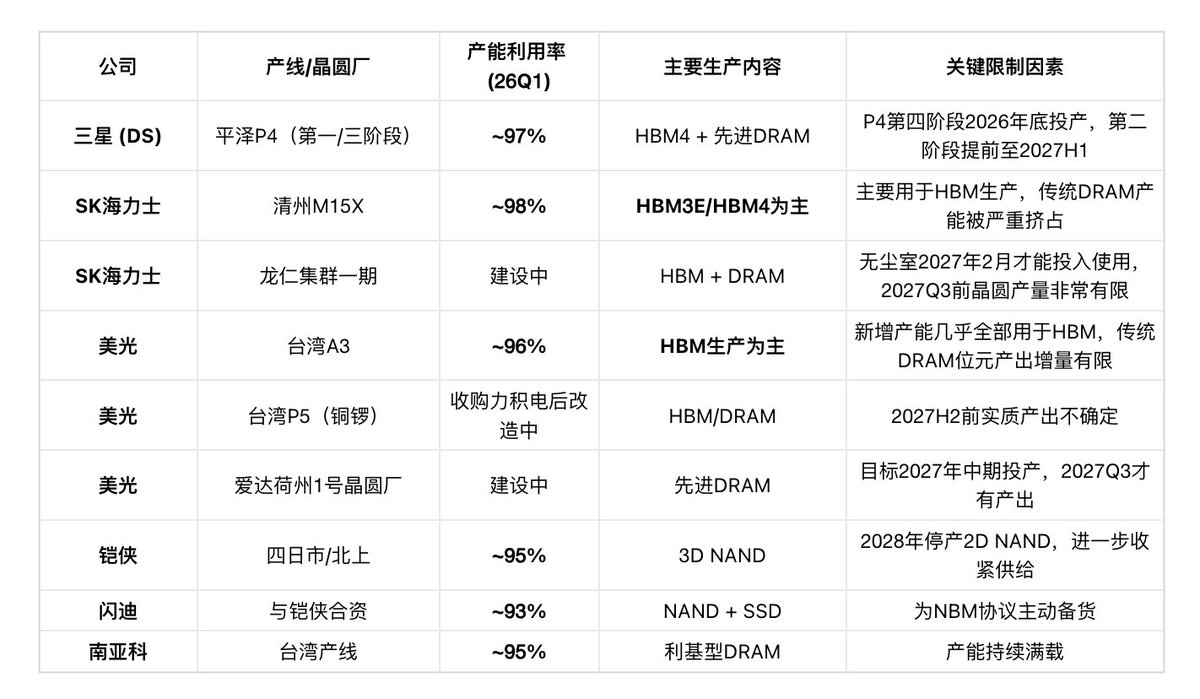
SemiAnalysis:“2026年几乎所有新增的晶圆产能都将集中在三家晶圆厂:三星的P4、SK海力士的M15X以及美光的A3。其中,美光的A3和SK海力士的M15X预计都将 主要用于HBM生产而非传统DRAM ,这将限制晶圆和位元产出的增量。 NAND方面,2026年几乎没有实际晶圆增量贡献 ,位元增长主要依靠技术工艺的升级。”
这意味着:即使产能利用率从95%提升到98%,传统DRAM/NAND的有效供给也几乎零增长。
指标二:现货价格指数(截至2026年5月8日)
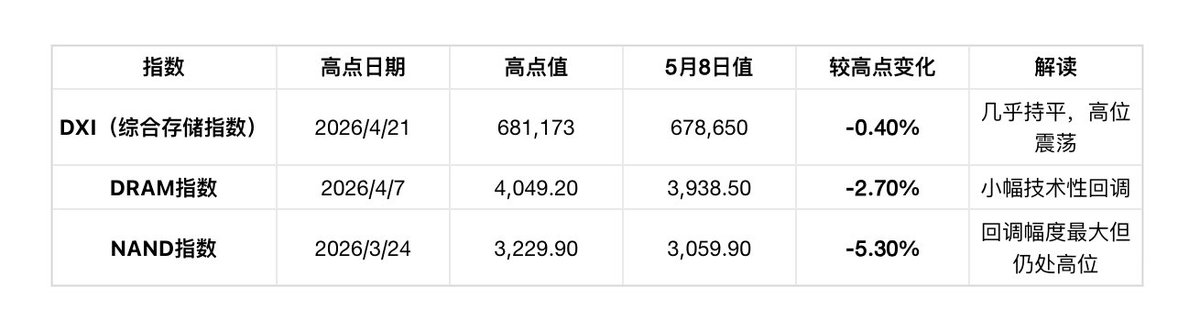
数据来源:Wind
DRAM现货详细价格(日度,截至5月8日) :
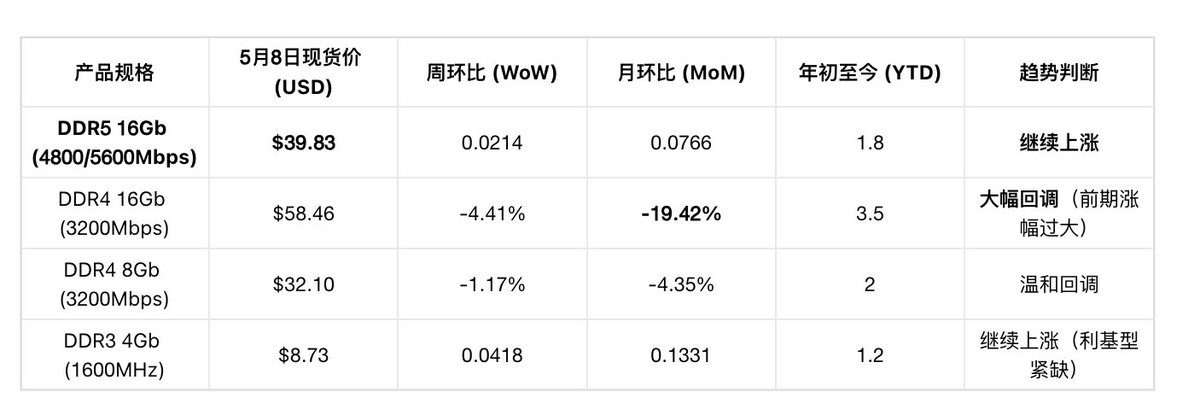
DDR4与DDR5的“剪刀差”现象 :DDR4现货回调是因为前期涨太猛(与合约价差过大),而不是因为需求崩塌。DDR5现货仍在上涨(WoW +2.14%),说明AI服务器需求(主要用DDR5)依然强劲。
NAND现货价格(周度,截至4月27日) :
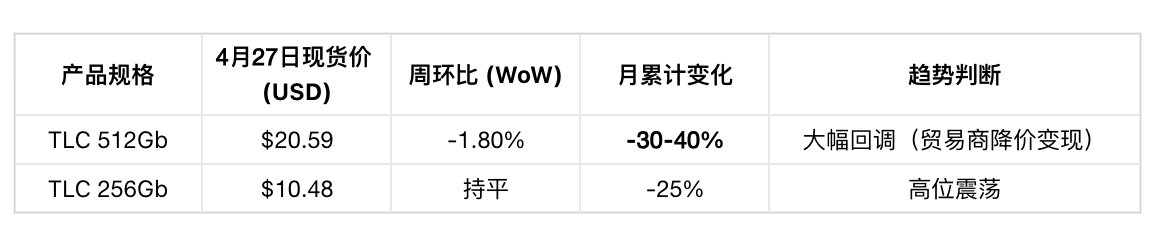
NAND现货回调三大原因 (招商证券):前期涨幅过高(3个月翻倍)+ 贸易商资金周转压力 + 买方普遍观望。但 合约价完全不受影响 :TrendForce预计Q2 NAND合约价仍环比上涨 70-75% 。
指标三:合约价格最新预测(TrendForce 2026年5月)
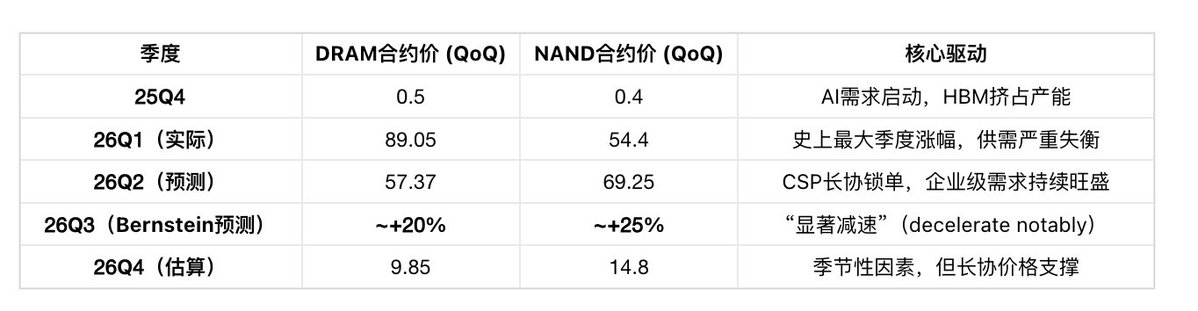
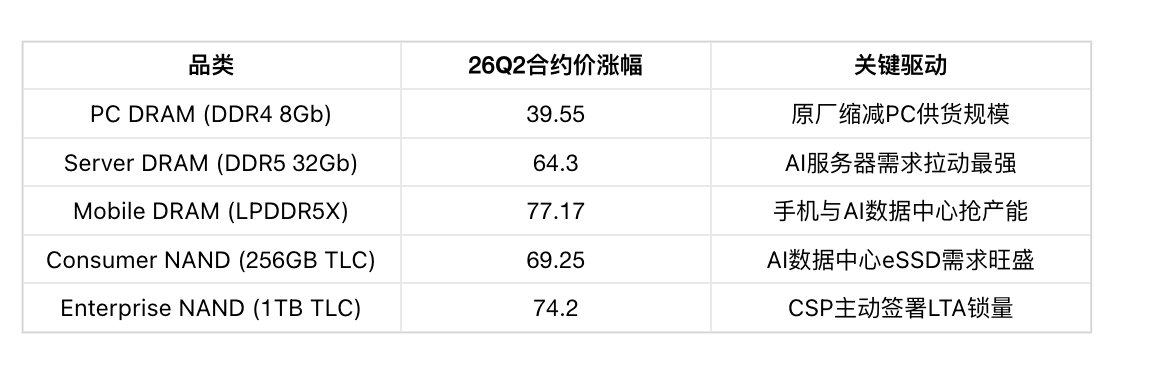
细分品类合约价预测(26Q2) :
Bernstein Mark Li(2026年5月7日) :“Price increases are expected to decelerate notably into the third quarter. We expect the cycle to peak in mid-2027, with a gentle descent thereafter.”
指标四:库存周转天数(26Q1最新)
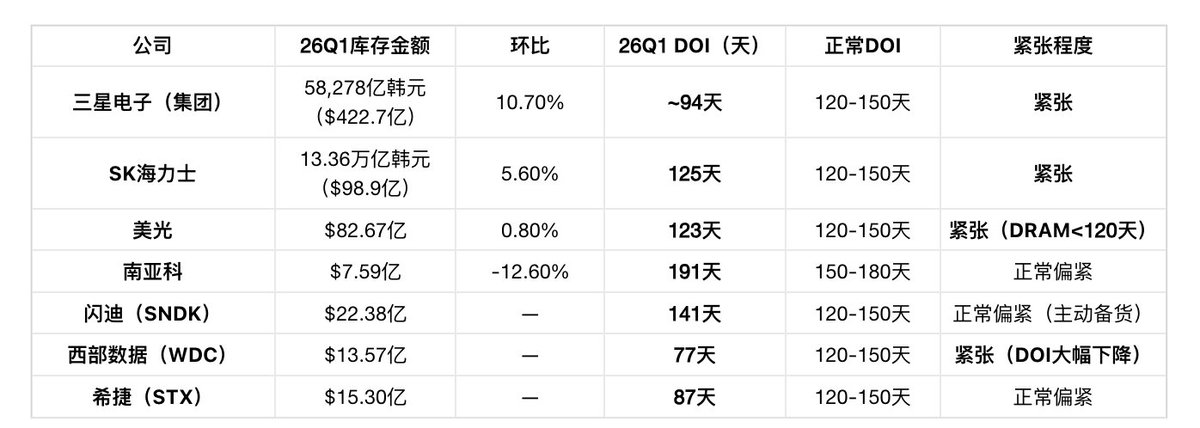
四层库存结构:
-
原厂成品库存4周级别(SK海力士成品仅28天),供给端零缓冲
-
中游模组厂主动建库存(江波龙+德明利+佰维合计422.2亿元,DOI 270-303天),赌继续涨价
-
下游客户签LTA和长协(闪迪5份NBM覆盖2027财年超1/3位元产量,美光首份5年SCA)
-
HDD的LTA已延伸至2028-2029年
综合判断:当前处于周期什么位置?
结论 :当前(2026年5月)存储超级周期处于 上行周期中段(约60-70%位置) ,而非尾声。核心论据:产能利用率还有提升空间、合约价格仍在强劲上涨、原厂库存处于战略性低位、长协锁单占比>50%大幅降低了“需求崩塌”风险。


