反馈控制:DeFi的下一个重要原语



写在前面:原文作者是来自Gauntlet的Hsien-Tang Kao和Tarun Chitra,在这篇文章中,他们使用Ampleforth的rebase机制、RAI的反射指数、EIP-1559的费用市场提案及THORChain的激励钟摆机制来说明反馈控制器在不同机制中的使用,此外,他们还将展示反馈控制如何使链上衍生品定价成为可能。

(图片来自:Flickr)
今年,我们已看到了大量新出现的DeFi协议,它们提供了新的机制来支持交易、借贷以及其他金融活动。尽管这些协议在功能和用途上差异很大,但一些原语已成为了很多新协议的通用组件。其中,常数函数做市商(CFMMs)及自动利率曲线,是两大最受欢迎的DeFi组件,它们出现在众多defi产品中(例如Uniswap和Compound)。随着行业聚集在这些原语周围,这就引出了一个问题:是否存在更好的选择?实际上,反馈控制系统(Feedback control system)正是一种可能改善协议激励、效率及弹性的方法。
什么是反馈控制?
“反馈是生命体的核心特征,反馈的过程控制着我们如何成长,如何应对压力及挑战,以及负责调节体温、血压、胆固醇水平等因素。从细胞中蛋白质的相互作用,到复杂生态系统中有机体的相互作用,这些机制在每一个层面都起着作用。” —— 马伦·霍格兰(Mahlon Hoagland)和伯特·窦德生(Bert Dodson) ,《生命的运作方式》,1995年控制理论在应用数学、电气工程及机器人学中得到了广泛的研究。它在许多行业都有广泛的应用,包括航空航天系统、自动驾驶车辆及物联网设备。在经典的“反馈系统”教科书中,Karl Johan Åström和Richard M. Murray将控制定义为在工程系统中使用算法和反馈。
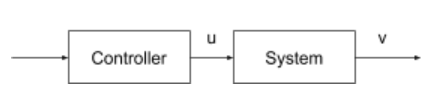
[1] 开环系统
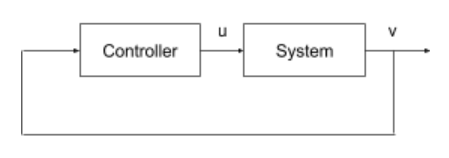
[2] 闭环系统
图[1]和[2]说明了开环和闭环控制系统的区别。在开环系统中,控制器输出与系统输出无关。与之相反的是,闭环(反馈)系统的控制器,将系统输出作为附加输入。在闭环系统中,系统动力学依赖于控制器动力学,而控制器动力学又依赖于系统动力学,这就产生了系统与控制器动力学的耦合效应。由于循环依赖性,理解反馈系统是非常重要的。
反馈控制与强化学习简史
比例-积分-微分(PID)控制器是最为常见的反馈控制器。它利用期望系统状态与观测状态之间的差值连续计算控制信号。1922年,俄国人Nicolas Minorsky为美国海军舰艇的自动操舵系统,发表了第一个PID控制器的理论分析。20世纪50年代,商用数字计算机问世,这使得最优控制理论得到迅速发展。最优控制的首要问题,是找到一个能产生最优状态轨迹,并使动态系统行为的测度最小化或最大化的控制律(control law)。Richard E.Bellman的“最优性原理”(或贝尔曼(Bellman)方程)、动态规划算法及马尔可夫决策过程,就是在这一时代发展起来的,它们目的是为解决最优控制问题。20世纪80年代末90年代初,在最优控制和人工智能领域的前期工作,推动了强化学习的发展。强化学习在不完全了解系统状态的情况下,通过试错学习或逼近来解决最优控制问题。近二十年来,随着计算和深度学习算法的发展,出现了新一轮成功的深度强化学习算法。深度强化学习通过使用深度神经网络,扩展强化学习,而不需要显式地设计状态空间。DeepMind利用这些算法来创建可以玩Atari游戏的人造代理,以及比人类做得更好的 Go 。
PID 控制器
了解反馈控制或PID控制器的直观方法,是通过一个比例控制器(P controller)
其中
K_p
是一个常数,在一个比例控制器中,控制输入
u(t)
与观测输出和期望系统输出之间的误差
e(t)
成比例。
这里我们将展示一个恒温器如何使用反馈机制来控制室温。假设当前温度为90°F,恒温器温度设置为70°F,则误差为20°F。当
K_p
= 0.1千瓦/°F时,恒温器控制空调设备,使其使用
u(t) = 2
千瓦来冷却整个房间。
当温度下降到80°F时,误差减小到10°F,空调将输出1千瓦的功率。从这个例子中,我们可以看出,恒温器输出一个控制信号来改变空调器的输出功率,并降低温度。恒温器测量温度误差,并改变输出控制信号,这种反馈回路使室温逐渐收敛到所需温度。
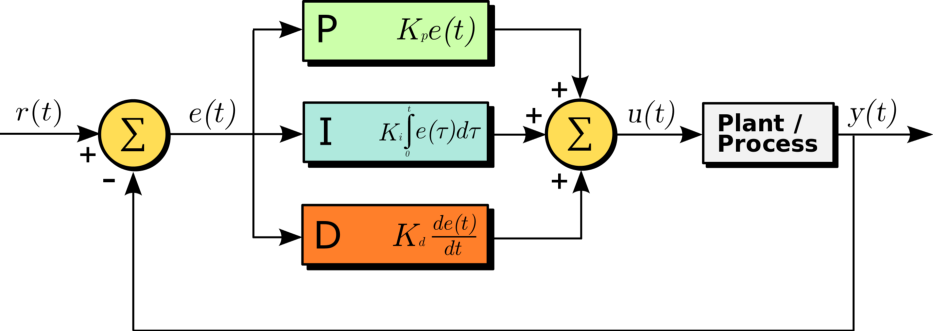
PID控制器方块图(来源:Wikipedia)
PID控制器扩展了比例控制器的概念。除了当前误差
e(t)
,它还测量累积误差
\int e(t)
及误差变化率
\frac{de(t)}{dt}
来计算控制输入:
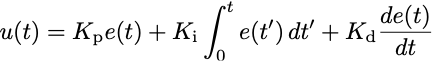
其中,
K_p
、
K_i
以及
K_d
都为常数。
反馈控制和DeFi
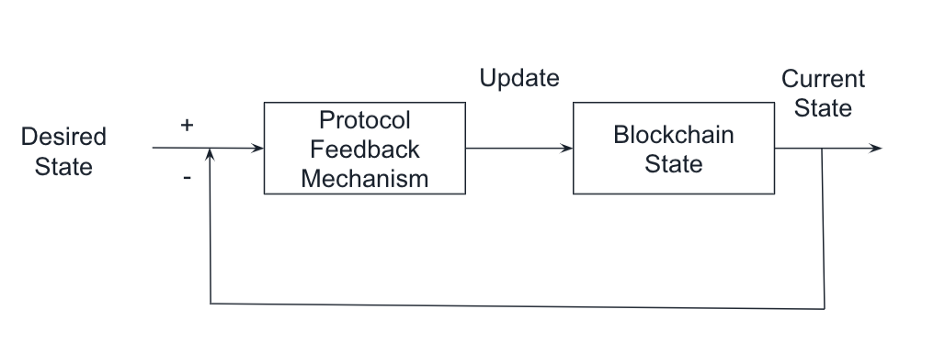
反馈控制是一种简单而强大的思想,它在现实世界中已经被广泛应用。在现有的应用之外,反馈控制也是DeFi应用的重要组成部分。假设一个协议有一个高层次的目标,该协议测量当前状态的距离,并使用反馈机制更新协议参数,以激励市场参与者将系统推向期望状态。例如,稳定币协议希望将代币与1美元锚定,协议根据稳定币价格不断调整利率,当稳定币价格高于1美元时,该协议将降低利率并激励参与者发行更多的稳定币。否则,协议将提高利率并激励参与者偿还债务。通过算法调整利率,当稳定币在1美元左右时,市场就可以达到供需平衡。
很多DeFi应用已经在协议设计中隐式或显式地使用这种模式。这里我们将使用Ampleforth的rebase机制、RAI的反射指数、EIP-1559的费用市场提案及THORChain的激励钟摆机制来说明反馈控制器在不同机制中的使用。 我们还将展示反馈控制如何使链上衍生品定价成为可 能。
波动性抑制资产
Ampleforth和RAI开创了不相关和低波动性加密资产的概念。乍一看,这些协议似乎有不同的底层机制。AMPL动态调整供应,以解决不适应性问题,而RAI则使用动态赎回率机制来最小化反射指数波动。然而,这两个协议本质上都是反馈控制系统,它们旨在创造一个波动性抑制资产。而这些协议的主要区别,在于它们使用了不同的控制输入。我们将使用反馈控制框架来展示这两种协议之间的异同。
1、Ampleforth Rebase机制
AMPL是一种根据市场价格动态调整供应的数字资产,当AMPL的价格高于1美元时,其供应量就会扩大,反之则会缩小。代币供应机制的扩张与收缩,激励理性的AMPL交易员介入,推动AMPL价格向1美元目标迈进。为了用公式表示rebase机制,我们首先将误差定义为目标值与观测值之间的差:
假设目标值为1美元,观察值为当前价格,则误差项为:
当价格偏差e(t)大于偏差阈值d_t时,AMPL的供应调整为:
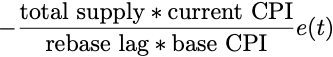
根据上面的方程,我们可以将rebase表示为一个比例控制器,其中:
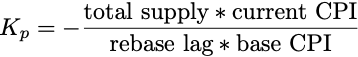
控制规则:
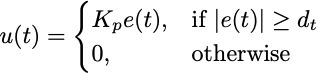
从这个例子中可以看出,
rebase lag
是决定系统行为的关键参数。选择适当的
rebase lag
参数与调节控制器的比例增益是一样的。比例增益对系统特性的影响在控制系统中得到了广泛的研究:高比例增益(或低
rebase lag
)可以减小稳态误差,加快上升时间,但会增加超调量(overshoot),使系统更具振荡性。
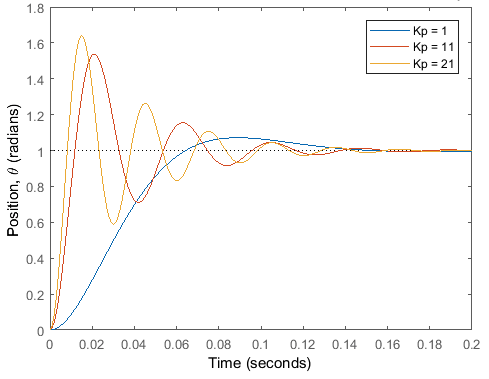
(来源:Matlab和Simulink的控制教程)
2、RAI反射指数
反射指数是一种波动性低于其抵押品的资产。该系统使用类似MakerDAO的债务抵押头寸(CDP)进行资产发行。当反射指数的赎回价格偏离市场价格时,协议会调整赎回率(赎回价格的变化率),以激励CDP持有人产生更多债务或偿还未偿债务。RAI反射指数是在协议设计中第一个明确引用PID控制器的协议。这个反射指数中的误差项是市场价格和赎回价格之间的差额:
赎回率是控制输入,并由一个比例控制器修改:
以及
在上面提到的两个例子(Ampleforth和RAI)中,都有一个反馈控制系统。这些协议以特定的参考价格为目标,但使用不同的经济机制来影响代币的供应。Ampleforth直接改变了系统的总供应量,以激励参与者进行“供应发现”或“市值发现”,从而将AMPL价格推向1美元。RAI改变了赎回价格,激励参与者重新平衡未偿债务总额,以减少价格波动。
EIP-1559: 以太坊费用市场更改提议
当前的以太坊费用市场使用简单的第一价格拍卖机制来定价交易费用。这种拍卖机制是次优的,它为竞拍人带来了相当大的开销,因为每个竞拍人都需要根据其他竞争对手的预期出价进行竞标。EIP-1559通过一种自适应的收费机制解决了这个问题,这样收取的总费用可以超过网络的社会成本。
拟议的交易费用包括动态调整的基础费用(base fee)以及给矿工的额外小费(tip fee)。区块使用量是决定基础费用的主要因素:当区块使用量高于目标使用量时,基础费用增加,反之则降低。这种费用调整算法寻求博弈论均衡并建立费用下界。这项提议可能是以太坊1.0最重大的变化,它将极大地改变用户体验和货币政策。
毫不奇怪,EIP-1559可以被描述为一个反馈控制问题,它的基础费用调整算法为:
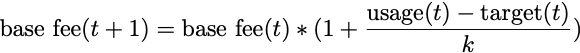
算法中的误差项为:
基础费用调整算法也是一个比例控制器,其中:
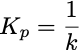
控制输入为:
以及
THORChain的激励钟摆机制
THORChain是一个为跨链资产交换提供便利的去中心化网络,该协议要求系统的总池子资本大于担保资本,以保证其安全。在THORChain中,2:1的资本比例被认为是最优的系统状态。这种激励钟摆机制是为了使系统处于平衡状态,它将总的通货膨胀报酬和交易费用重新分配给参与者,使系统逐渐收敛到最优状态。特别是,分配给流动性提供者的系统收入比例为:
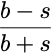
其中,
b
和
s
表示总的担保资本和总的池子资本,其余部分则给予担保人(bonder)。在最优状态下,激励钟摆将33%的系统收益分配给流动性提供者,将66%的系统收益分配给担保人(bonder)。如果系统只有担保资本,激励钟摆会将100%的系统收入分配给流动性提供者。
THORChain的激励钟摆使用链一个确定的公式来计算系统的收入分配。虽然它没有使用PID控制器的公式,但是激励钟摆和PID控制器有一个非常相似的概念:
- 该机制试图将误差随时间的变化最小化,即使系统状态收敛到最优状态;
- 控制信号是一个误差函数,其中误差是测量的bonded-to-pooled资本和最佳bonded-to-pooled资本之间的差;
链上衍生品定价
2020年当中最大的惊喜之一是,现货资产DEX能够处理和中心化交易所相同数量级的现货交易。
然而,最活跃的加密交易产品——永续合约,尚未实现去中心化。尽管目前已经有了一些去中心化期货产品的尝试,比如FutureSwap和McDEX,但截至目前,这些协议都没有实现他们的承诺。其中的一个主要原因是,相比现货交易,期货交易对延迟要敏感得多。这是因为预言机价格更新需要非常迅速,以避免抢先交易(front running)和 延后交易(back running) 。此外,由于较低的保证金要求允许用户用较少的抵押品进行大规模押注,因此流动性往往会以更快的速度在衍生品交易场所增加和移除。然而,在不需要高流动性速度的情况下,有许多新的机制可以复制衍生品的结果。这些方法涉及自动做市商(如Uniswap),它们具有动态曲线。在这一方向上的一个基本工作是Alex Evans的一个定理,其表明,如果一个Balancer池根据一个修改后的PID控制器调整其权重(如下所示),那么你可以复制任何无杠杆回报。
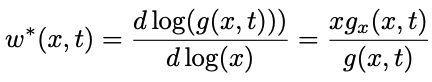
在上面的等式中,Balancer 池的权重
w*
遵从控制方程,作为预期收益
g
的一个函数。生成任意的衍生品收益是一个增加杠杆作用的问题 —— 如果某人可以针对支付
g(x,t)
的Balancer池股份进行借贷,并用借入的资金创建新的资金池份额,那他们就可以将自己的敞口杠杆化为
g
的常数倍数。而像Aave和Compound这样的链上借贷平台,就非常适合进行这种操作。那这与永续合约交易有什么关系?
我们可以将永续合约产品视为一个将指数价格
p(t)
映射为正或负回报的函数。例如Balancer这样的常数函数做市商(CFMMs),允许将
p(t)
表示为一个数量向量,以及池的权重控制着从数量到价格的映射。因此,我们可以将永续产品(用金融术语来说,是一个复制投资组合)的替代结构视为一个CFMM,其形状正在调整以保持收益。虽然权重更新仍可以前推和后推,但要做到这一点要比操纵价格要困难得多。这是因为你需要操纵做市商持有的数量(上面等式中的x)来调整收益
g
。与操纵价格(单一标量)不同,你必须调整抵押品数量
x
(许多LP锁定的一对现货资产)。正如我们在Uniswap论文的附录D中所指出的,随着锁定的总值增加,这种操纵会越来越困难(难度呈线性上升)。
这个例子说明,当使用适当的比例控制器时,当与动态调整的做市商耦合时,很多衍生品产品可存在于链上。虽然设计此类控制器的研究尚处于起步阶段,但像Yield、Opyn及其他团队设计的CFMM,这种流行趋势已经表明,控制理论使得链上衍生品成为可能。
以太坊的计算和存储容量有限
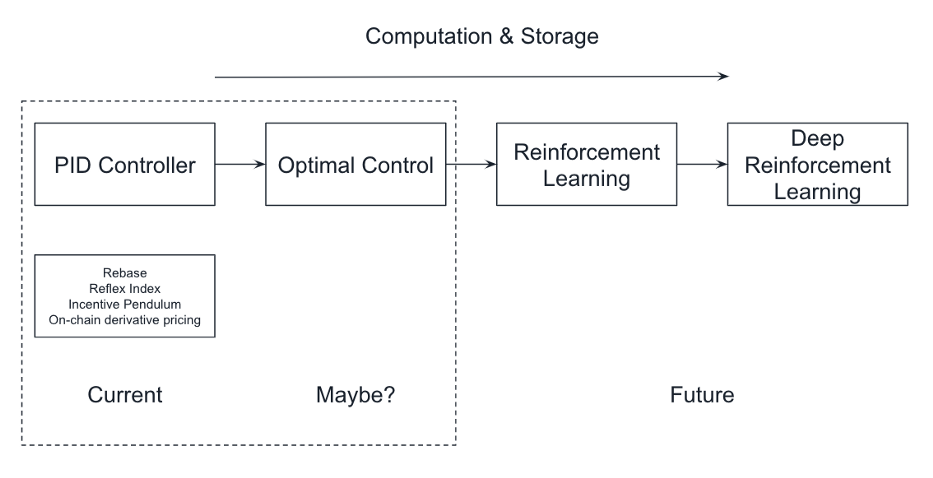
在关于反馈控制与强化学习的历史上,算法的进步可以说是成功的主要因素。然而,人们往往忽视了这样一个事实:计算和存储范式的转变,也导致了这些技术突破。在20世纪50年代没有商用计算机的情况下,动态规划(Dynamic programming)是解决最优控制问题的一种方法,如果没有GPU集群和巨大的存储空间,Deepmind无法有效地训练用于玩Atari游戏的深度强化学习模型。
我们知道,以太坊的计算和存储容量是有限的。目前,大多数的DeFi协议都是通过使用简单的反馈算法来克服这些限制,这些算法不需要大量的存储来跟踪历史状态的变化。因此,PID控制器或其他恒定的空间及时间复杂度算法(run time和空间需求不会随着输入大小的增长而增长)很适合资源受限的计算环境。
关于链上杠杆控制理论自然而然的下一步,是制定DeFi协议反馈机制作为一个最佳控制问题。原因有二:关于最优控制,已有大量的理论工作,而且它不依赖于庞大的计算能力。另一个可能的途径是通过协议的治理过程,在链上引入更复杂的算法优化参数。许多中立的第三方可以在链外处理区块链数据及外部数据源,运行复杂的算法,并提交优化的治理投票参数,以提高协议效率。
最后的想法
- 比例控制器是工业中最常见的控制器形式,它以电流误差为输入,较好地解决了大部分问题。为了进一步改进现有的反馈系统,协议可以考虑添加“过去误差”(积分项)和“预期未来误差”(导数项)作为控制器的输入。
- 联合曲线或利率曲线是激励特定用户行为的机制。参数化这些曲线是非常重要的,因为设计空间很广。例如,具有不同形状的曲线,可能会获得非常相似的结果,但很难断言其中一条曲线严格优于另一条曲线。基于联合曲线的方法存在维数灾难(curse of dimensionality)。参数化三维或更高维曲面,似乎是一项具有挑战性的任务。协议开发团队可以考虑使用反馈控制方法来简化设计及参数化方法。开发人员不需要设计描述一系列参数值之间关系的整个曲线,而只需要关注参数值的“变化率”。
- 考虑到智能合约通常涉及高风险及反馈系统的动态性,设计一个基于反馈控制的智能合约是一项挑战。我们知道,模拟在工业中被广泛应用于参数调试,而Gauntlet可帮助协议设计者通过模拟大量的协议参数及市场环境来对他们的协议进行压力测试。建立一个安全高效的DeFi生态系统,一直是我们的首要任务。
原文:https://medium.com/gauntlet-networks/feedback-control-as-a-new-primitive-for-defi-27b493f25b1 作者:Hsien-Tang Kao 和Tarun Chitra 翻译:洒脱喜


