开发者说:为什么我选择 Rust?



翻译:孙元超@Cdot Network
来源:https://www.parity.io/why-rust/
Why Rust?
编程很难。
不是因为我们人体本身构造复杂,而是因为我们都只是人类。我们的注意力持续时间有限,记忆也不是永久的——换句话说,我们往往会犯错。电脑和软件无处不在:在太空中,天上,地面,佩戴在身上,甚至在我们的身体里。每天都有越来越多的系统实现自动化,越来越多的生命依赖于软件及其质量,航空电子设备,自动驾驶汽车,核电站,交通控制系统,植入式心脏起搏器。这些系统中的bug几乎总是危及人类的生命。
“程序正确性是通过测试来检验的”和“程序正确性是经过逻辑验证的”之间存在着巨大的差异。不幸的是,即使我们对代码的每一行都进行了测试,我们仍然不能确保它是正确的。然而,拥有一个形式系统来证明我们的代码是正确的(至少在某些方面是正确的)则是另一回事了。
Rust的方式
「Rust作为一种编程语言」的不同之处,不是因为它的花哨语法或受欢迎的社区,而是因为人们在使用它编写程序时能获得信心。Rust非常严格并且追究细节的编译器会检查你使用的每个变量和引用的每个内存地址。它可能看起来会妨碍你编写高效且富有表现力的代码,但令人惊讶的是,恰恰相反:编写一个有效且地道的Rust程序实际上比编写一个有潜在危险的程序更容易。在后一种情况下,你将与编译器发生冲突,因为你尝试的几乎所有操作都会导致内存安全问题。
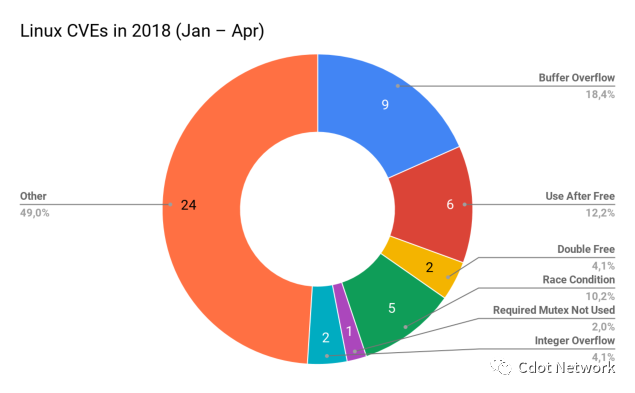
上图右侧部分显示了并发性和内存安全相关的问题,这些问题根源上不可能发生在常规(非unsafe块)Rust代码中。所以只需要换成Rust,他们就可以杜绝这段时间内大约一半的bug。同时,缓冲区溢出是其中最危险的bug,因为它们常常导致「密钥泄露」、拒绝服务和远程代码执行漏洞。
上图还表明,“一个人只需要知道如何编写C”和“只需要把底层的东西留给专业人士”这样的想法是不够的。Linux内核是由行业中最优秀的5%的人编写的,然而,内存bug这位老朋友一年又一年的给我们贡献着CVE(通用漏洞披露)。
当然,与kernel中数百万行正常工作的代码相比,这50个bug根本算不了什么。但是之前说过的生死攸关的问题,还记得吗?当我们谈到关键系统时,即使是最小的错误也可能导致灾难性的后果。还没提及这50个只是被发现了的bug。谁知道还有多少没被发现呢?如果使用Rust,我们会事先知道这些问题。
Rust有多快?
你可能会想:当然,Rust可能提供了这么多东西来杜绝这些隐患,但是要花多少代价呢?通常,在现代编程语言中的内存安全需要负担垃圾回收器的开销。并发问题通常通过使用特殊的同步原语锁定所有受影响的数据结构和执行路径来解决。
但对于Rust就不是这样了。它的强大来自于巧妙的类型系统,可以在编译时就解决所有这些问题。「Type System的设计」同时防止了内存问题和数据竞争问题。
就像在C++中一样,你可以只使用你需要的东西。例如,在Rust中,你只在绝对需要时才使用互斥锁。而且,Rust编译器会需要的位置迫使你使用它,所以永远不会忘记。所有这些基本上都是零成本的。由于大多数检查都是在编译时执行的,因此编译后的程序集与C或C++编译器生成的程序集没有太大区别。
由于这个原因,Rust现在在「嵌入式电子」、「物联网」,甚至「操作系统开发」领域都非常有前景,而这些领域以前都是由C语言主导的,因为需要很高的控制要求、资源和性能也有严格的限制。
Rust的最新版本甚至在用户空间引入了SIMD支持。以前,由于API稳定性的限制,它只能在nightly版本中使用。现在,你可以通过直接使用向量指令或使用「便捷的包装库」来释放硬件的全部潜力。而且,即使你不打算这样做,编译器仍然会在可能的情况下自动向量化循环语句和其他东西,在许多情况下,可以达到手工编写向量指令代码的性能水平。
我们为什么使用Rust
Parity Technologies使用Rust也是出于同样的原因。因为它让我们可以毫无畏惧地编写复杂而且高性能的软件。我们可以自由地进行实验,因为我们确信Rust将为我们提供支撑。无论是实现一个简单的命令行实用程序还是一个多线程庞然大物,它都没有什么区别。Rust确保我们的程序不存在未定义的行为、数据竞争或任何内存安全问题。更不用说,Rust「非常快」,编写起来很有趣,易于阅读,而且几乎没有运行时。
内存bug之所以难以发现,是因为你不能轻松地编写测试来捕获它。如果你在beta测试期间没有发现bug,那么它可能会在代码中存在数年,就像定时炸弹等待着爆炸的那一刻。当然,也有像「Valgrind」这样的工具可以帮助捕获这些bug。但即使是Valgrind,如果问题发生时不是执行在调试模式下,或者执行时没有表现为内存方面的问题,它也不会捕获到bug。
因此,通过使用Rust,我们消除了最复杂、最不可预测的一类错误。
测试的作用
当然,内存安全问题只是所有问题的一部分。例如,我们可以编写一个函数对它的整型参数求和,但是它只随意返回了一个常数。或者我们写了一个随机数生成器却生成的是可预测的值。这种行为并没有违反Rust的内存安全保证,但显然是不正确的。

这就是测试的用武之地。测试允许我们检查编译器无法理解的不变量因素。基本上,我们需要确保相应的测试覆盖了返回的每个结果和程序中做出决策的每个点。在上面的例子中,测试必须检查函数是否确实返回其参数的和,还有产生的随机数是否足够随机。
在某种意义上,逻辑错误更容易处理。从定义上讲,它们与程序员编写程序时考虑的领域是相同的(而内存bug则不在其中)。
幸运的是,我们知道如何处理这些bug。在过去的几十年里,程序员和计算机科学家创造了一套方法和工具,通过使用这些方法和工具,我们可以减少逻辑错误的数量,并将它们保持在最小。
数学的力量
在最严格和复杂的途径中,程序正确性是被验证出的,而不是通过检验。像「Iris」和「Coq」这样的语言可以用来证明整个程序的正确性。不是像测试一样检查一些输入的有效性,而是把它被当作一个数学定理一样证明,一次和所有可能的输入和每个可能的场景。只有通过构造这样的证明,你才能获得程序是正确的信心(只要你的规范和理解是正确的)。
基本上,Rust做的是相同的事情,但是只针对一些限定的特殊问题,比如并发性和内存安全性。实际上,它使用逻辑来证明你的程序在这些方面是正确的。想想看,仅仅通过编写常规的Rust代码,你就可能拥有与每次编译项目时让一组数学家研究某个定理相同的信心水平。
不幸的是,证明系统的每个部分都是如此是十分复杂和耗时的,以至于通常只对软件的最关键部分进行验证,比如操作系统内核、密码算法,在某些情况下,还有语言的标准库。
在很长一段时间内,像Haskell这样的函数式编程语言的一个杀手级特性就是可以形式证明代码,而传统的命令式编程语言由于广泛使用了共享可变性、不安全的指针运算和无法控制的副作用,仍然无法应用形式证明。但是Rust可以改变这一点,尽管它是一种命令式语言,但它已然「在进行形式化证明的路上」。
「来自RustBelt项目的Ralf Jung等人」已经发表了一些「论文」,证明了Rust语言声明的基本不变量确实包含在标准库的一些重要原语中。
问题是,出于性能原因,Rust标准库包含许多潜在的unsafe代码和raw指针运算。
为了证明标准库的正确性,Ralf Jung和同事设计了一个叫做λrust的方法可以不收安全约束的使用分离的逻辑和他们自己的演算过程。通过这种演算,他们试图证明标准库原语和容器的工作方式符合预期,并且它们没有违反Rust的基本不变量。作为副产品,他们甚至在同步原语,比如「MutexGuard」和「Arc」中发现了一些bug。
但这项工作远未完成。正如作者所指出的:
- Rust作为一种编程语言:https://www.rust-lang.org/en-US/
- 密钥泄露:http://heartbleed.com/
- TypeSystem:https://blog.rust-lang.org/2015/04/10/Fearless-Concurrency.html
- 嵌入式电子:http://blog.japaric.io/
- 物联网:https://www.tockos.org/
- 操作系统开发:https://wiki.osdev.org/Rust
- 库:https://github.com/AdamNiederer/faster
- Faster:https://benchmarksgame-team.pages.debian.net/benchmarksgame/faster/rust.html
- Iris:http://iris-project.org
- Coq:https://coq.inria.fr
- Formalizing:https://www.ralfj.de/blog/2015/10/12/formalizing-rust.html
- Ralf Jung:http://plv.mpi-sws.org/rustbelt/)
- Ralf Jung相关论文:https://people.mpi-sws.org/~dreyer/papers/rustbelt/paper.pdf
- MutexGuard:https://www.ralfj.de/blog/2017/06/09/mutexguard-sync.html
- Arc:https://www.ralfj.de/blog/2018/07/13/arc-synchronization.html

