原文作者: Reforge
原文编译:深潮 TechFlow

框架概览
数据截至 2025 年 1 月 12 日
-
最新版本/发布:v 0.1.8+build.1 (2025 年 1 月 12 日)
-
GitHub 仓库: Eliza
-
许可协议:开源 MIT 许可
-
主要语言:TypeScript
-
统计数据:
-
11, 200 个星标
-
3, 100 个分叉
-
366 位贡献者
简介
Eliza 是一个开源的智能体开发框架,旨在让构建 AI 智能体变得更加简单、强大且灵活。它是否真的能达到宣传的效果?在这篇文章中,我们将深入探讨 Eliza 的优势、局限性,以及在实际使用中需要注意的事项。
Eliza 的定位
-
框架目标:为开发个性化、多模态的 AI 智能体提供一站式工具,这些智能体能够处理复杂的任务。
-
主要应用场景:包括 AI 助理、社交媒体角色、知识型工作者以及互动虚拟角色等。
-
核心功能特点:
-
模块化运行时:支持注册操作和插件,方便扩展功能。
-
跨平台部署:兼容 X(原 Twitter)、Discord、Telegram 等多种平台,支持广泛的应用场景。
-
角色驱动定制:通过详细的角色文件(如背景故事、知识库、语调等)实现高度个性化的智能体。
-
多媒体处理能力:支持文本、视频、图像等多模态数据的处理。
-
推理功能:支持本地和云端推理,使其适应不同的部署环境。
-
检索增强生成 (RAG):通过外部数据源和知识库提供长期记忆和上下文感知能力。
从功能描述来看,Eliza 是一个多功能的智能体开发平台。但在实际应用中,它的表现如何?
Eliza 的实际能力
-
角色定制化:Eliza 提供了强大的角色系统,允许用户创建具有独特语调、风格和背景故事的智能体。
-
这使得 Eliza 在构建叙事驱动的虚拟助手或保持一致品牌语调的场景中表现尤为出色。
-
用户可以通过设置角色的个人简介、背景故事、知识点和语调等属性,灵活地调整智能体的个性化表现。
-
跨平台集成:Eliza 支持与 Discord、Slack、Telegram 等平台的无缝对接,使智能体能够适应不同的社区互动需求。
-
例如,社交媒体机器人和客户服务智能体可以轻松实现跨平台部署,并协同工作以提高效率。
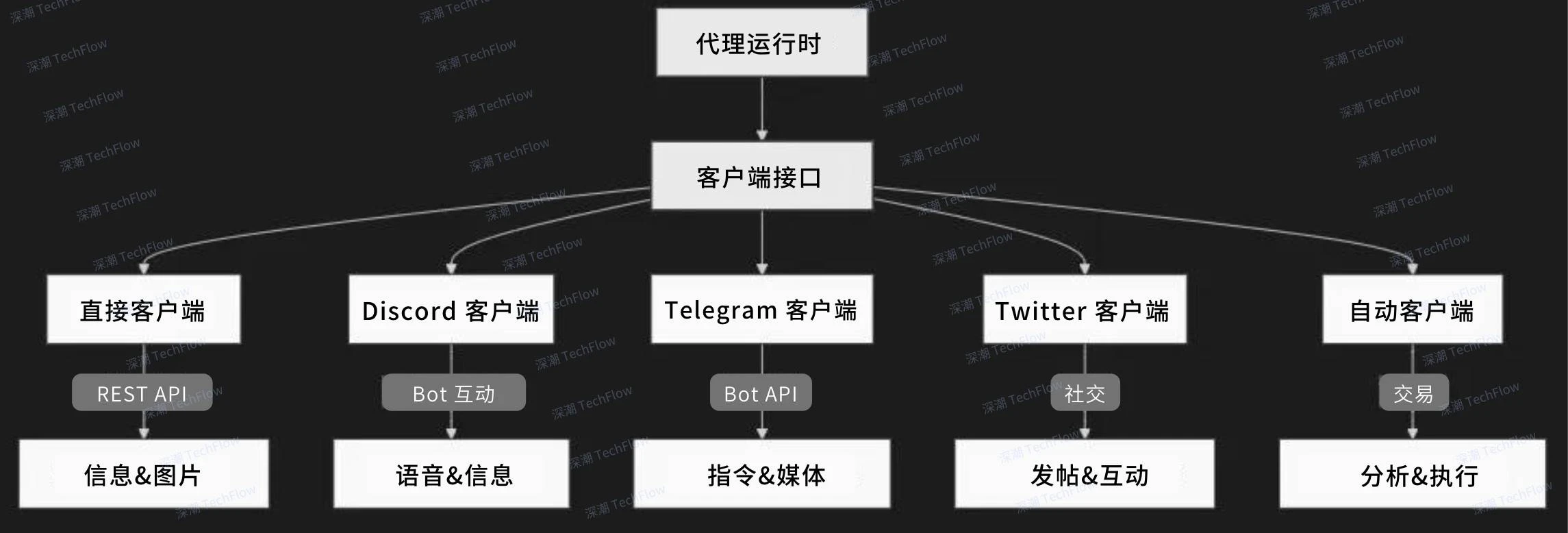
客户端包架构概述(来源:Eliza Docs)。原图来自 Reforge ,由深潮 TechFlow 编译。
-
可扩展的插件系统:Eliza 提供了丰富的插件支持,用户可以根据需求扩展功能,例如文本转语音、图像生成和区块链数据检索。
-
例如,在市场分析场景中,用户可以通过插件实现实时数据获取,并生成高质量的评论或见解内容。
-
检索增强生成 (RAG):这一功能使得智能体能够根据外部数据源和知识库生成更精准的回答。
-
例如,市场分析机器人可以通过整合外部文档和缓存机制,提供上下文相关且快速的响应,从而提高服务质量。
-
可信执行环境 (TEE) 支持:Eliza 提供了一层安全保护,允许智能体处理敏感数据和工作流,确保关键任务的安全性和可靠性。
Eliza 的不足之处
缺乏自适应学习
-
静态角色配置:Eliza 的角色个性配置是预定义的,无法根据用户的实时交互或历史对话动态调整。这意味着智能体在长时间使用中可能显得“千篇一律”,无法根据用户需求做出变化。
-
无法从反馈中学习:目前,Eliza 并没有机制从用户的纠正或反馈中学习,也无法根据之前的错误调整自身行为。这种缺乏自适应学习的特性,会导致智能体反复犯同样的错误或提供不符合用户期望的回答。
缺乏分层规划能力
-
无子任务分解功能:Eliza 无法将复杂的高层目标分解为多个小任务。例如,在需要进行多篇文献研究并总结出多段内容的场景中,Eliza 会显得力不从心。分层规划通常需要目标分解和子任务分配功能,而 Eliza 并未内置这些能力,开发者需要自行集成任务规划库来弥补这一不足。
智能体之间协作能力有限
-
缺乏协调机制:虽然 Eliza 支持多房间和多用户的环境,但它并不具备智能体之间的动态协作功能。智能体无法共享上下文信息、分配任务或解决冲突目标,这在需要多个智能体协同工作的场景中会显得尤为局限。
记忆功能和上下文处理的局限性
-
基础的键值存储:Eliza 的记忆系统仅能简单地存储数据,但无法优先处理最近或更相关的上下文信息。在长时间的对话中,智能体可能会忘记关键细节,导致对话缺乏连贯性。
-
缺乏记忆清理机制:Eliza 没有内置的记忆清理功能,无法自动移除过时或不相关的数据。这会导致记忆系统逐渐膨胀,不仅降低性能,还可能生成与上下文无关的回答。
错误处理能力不足
-
基础的 API 错误处理:当外部服务出现故障时,Eliza 仅会返回错误提示,而不会尝试切换到备用数据源。更完善的错误恢复机制,例如在服务失败时切换到次级选项,将显著提升系统的稳定性和用户体验。
缺乏真正的多模态智能
-
跨模态能力不足:虽然 Eliza 支持一些多模态插件(如文本转语音和图像生成),但它无法将文本、图像和音频等多种输入结合起来进行统一分析和推理。例如,Eliza 无法同时处理视觉数据和文本输入,这限制了它在多模态场景中的应用潜力。
Eliza 最适合的应用场景
-
市场情报智能体:可以帮助企业跟踪用户情绪趋势、分析社交媒体上的讨论热点,并生成实时的自动化响应。这类智能体特别适合需要快速反应的市场营销或品牌管理工作。
-
内容生成机器人:在多个社交平台上生成一致的品牌化内容,如定期发布的帖子或广告信息。这些机器人能够确保品牌语调的一致性,同时减少人工操作的工作量。
-
客户支持机器人:基于整理好的知识库,为用户提供快速、准确的回答,尤其适合处理常见问题(FAQ)。这些机器人不仅能够根据上下文提供脚本化的响应,还可以通过角色个性化设计,与品牌文化保持一致,提升用户体验。
总结
Eliza 提供了一个灵活且可扩展的框架,非常适合开发以角色为核心的智能体,尤其在简单或脚本化的工作流中表现出色。它在创建跨平台一致性的虚拟角色方面具有明显优势,但由于缺乏学习能力和战略规划功能,目前还不能称为真正的自主智能体开发框架。
如果用户的目标是构建能够自适应环境、进行协作或处理复杂逻辑的智能体,开发团队需要在 Eliza 的基础上进行大量的二次开发。这意味着,对于那些需要高效实用的应用场景,其核心价值更多体现在定制化功能的开发,而非框架本身的原生能力。
需要注意的是,目前阶段的 Eliza 不应被视为一个全面的智能体开发框架,与其 Web2 领域的同类产品(如 Langchain 、 Autogen 、 Letta 等)相比,它的功能仍有一定差距。Eliza 的真正优势在于角色驱动的自动化应用,但在实现真正的自主智能体开发方面还处于初级阶段,仅能满足一些基础需求。