原文作者:hmalviya 9
原文编译:Frank,Foresight News
编者注:《Attention Is All You Need》论文发表于 2017 年,截止目前被引用超 11 万次,它不仅是当今以 ChatGPT 为代表的大模型技术起源之一,其中介绍的 Transformer 架构和注意力机制也被广泛用在了 Sora、AlphaFold 等众多或将改变世界的 AI 技术之中。
「Attention Is All You Need」,这篇研究论文彻底改变了现代人工智能(AI)的未来。在这篇文章里,我将深入探讨 Transformer 模型和 AI 的未来。
2017 年 6 月 12 日,八位谷歌工程师发表了一篇名为「Attention Is All You Need」的研究论文,这篇论文讨论了一种改变现代 AI 未来的神经网络架构。

而就在刚刚过去的 2024 年 3 月 21 日的 GTC 大会,英伟达创始人黄仁勋与那 8 位 Google 工程师进行了一次小组讨论,并感谢他们引入了 Transformer 架构,使现代 AI 成为可能,令人惊讶的是,NEAR 的创始人居然也在这份 8 人名单之中。
什么是 Transformer?
Transformer 是一种神经网络。
什么是神经网络?它受人类大脑结构和功能的启发,通过大量的人工神经元互相连接进行信息处理,但却并不是人类大脑的完全复制品。
简单理解的话,人脑就如同亚马逊雨林,拥有许多不同的区域,以及连接这些区域的众多通路。而神经元就好比这些通路间的连接器,它们可以向雨林的任何部分发送和接收信号,因此连接就是通路本身,负责联通两个不同的脑部区域。

这让我们的大脑拥有非常强大的学习能力,它可以快速学习、识别模式并提供准确的输出结果。而像 Transformer 这样的神经网络试图实现与人类大脑相同的学习能力,只不过它们目前的技术水平还达不到人类大脑的 1% 。
近年来,Transformer 在生成式 AI 方面取得了令人瞩目的进步。回顾现代人工智能的演变历程,我们可以看到早期的人工智能主要是像 Siri 以及其他一些语音 / 识别应用程序。
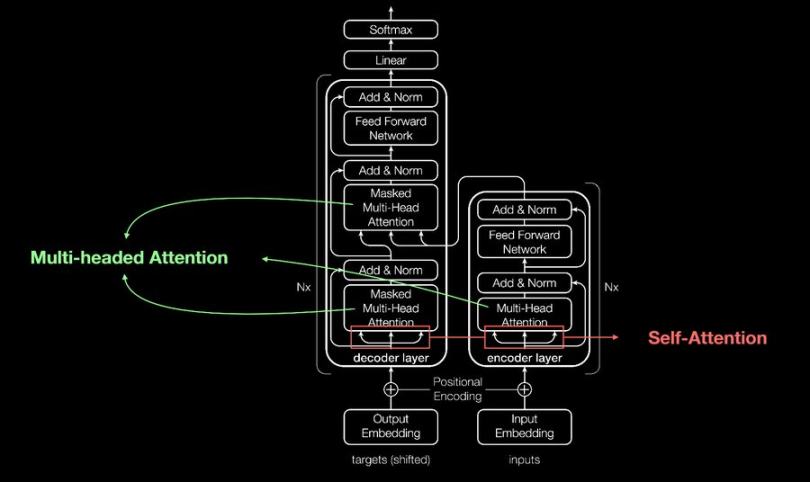
这些应用程序都使用循环神经网络(RNN)构建。RNNs 存在一些限制,而这些限制已经被 Transformers 所解决并改进——Transformers 引入了自注意力机制,使它们能够同时分析任一序列的所有部分,从而捕捉长距离依赖关系和上下文内容。

对于 Transformer 的创新周期来说,我们仍处于非常早期阶段。Transformer 有几种不同的衍生版本,例如 XLNet、BERT 和 GPT。
而 GPT 是其中最知名的一种,但它在事件预测方面仍然能力有限。
当大型语言模型(LLM)能够根据过去数据和模式预测事件时,这将标志着现代 AI 的下一个重大飞跃阶段,并且也将加速我们实现通用人工智能(AGI)的步伐。
为了实现这种预测能力,大型语言模型(LLM)需要采用时间融合转换器(TFT),它是一种基于不同数据集预测未来值的模型,还能够解释其做出的预测。
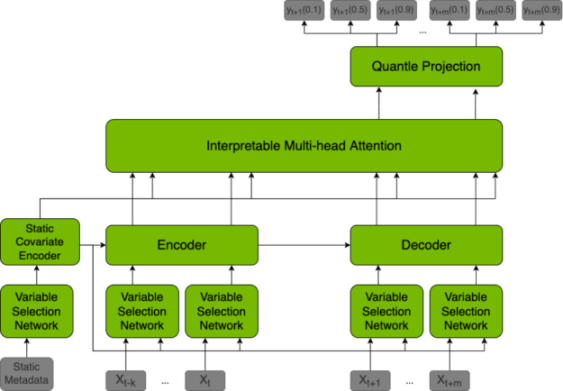
TFT 除了用于预测之外,还可以用于区块链领域。通过在模型中定义特定规则,TFT 可以自动执行以下操作:有效管理共识过程、提高出块速度、奖励诚实验证者、惩罚恶意验证者。
区块链网络本质上可以为具有较高声誉分数的验证者提供更多的区块奖励,这可以基于他们的投票历史、区块提案历史、Slash 历史、Staking 金额、活跃度和其他一些参数来建立。
公链的共识机制本质上是验证者之间的一种博弈,需要超过三分之二的验证者就谁来创建下一个区块达成一致。在这个过程中,可能会出现许多分歧和争论,这也是以太坊等公链网络效率低下的一个因素。
TFT 可以作为一种共识机制,通过提升出块时间并根据区块生产信誉奖励验证者,从而提高效率。譬如将 TFT 模型应用于共识过程的 BasedAI,就是将利用该模型在验证者和网络参与者之间分配代币发行量。

BasedAI 还提出利用 FHE 技术,让开发者可以在其名为「Brains」的去中心化 AI 基础设施上托管隐私保护的大型语言模型(Zk-LLMs),通过将 FHE 技术集成到大型语言模型中,可以做到在用户选择启用个性化 AI 服务时,保护他们的隐私数据。
当人们确信数据会受到加密保护并且完全隐私的前提下,愿意贡献数据的时候,或许我们就将实现通用人工智能(AGI)的突破,这一空白正在由专注于隐私的技术填补,例如 nillionnetwork Blind Computation、零知识机器学习(ZkML)和同态加密(FHE)技术。
然而,所有这些注重隐私保护的技术都需要大量的计算资源,这使得它们还处于应用的早期阶段。