DA的可扩展性:Avail目前的状态




随着用户开始将 Avail 集成到他们的链设计中,经常会出现一个问题:“Avail 能处理多少交易?”在这篇文章中,我们将根据目前两个链的架构,比较以太坊和 Avail 的吞吐量。
这是关于 Avail 扩展性系列文章的第一篇,将讨论 Avail 目前的性能以及其在近期和长期的扩展能力。
Avail vs Ethereum
以太坊的区块最大可以容纳 1.875 MB 数据,区块时间约为 13 秒。然而,以太坊的区块通常并不是被填满的。几乎每个区块都会因为达到 gas 限制而未达到数据的上限,因为执行和结算都消耗 gas。因此,每个区块存储的数据量是可变的。
将执行、结算和数据可用性结合在同一个区块中的需求,是单一区块链架构的核心问题。L2 rollup 开始了模块化区块链的运动,允许在一个单独的链上处理执行操作,且该链的区块专门用于执行。Avail 进一步采用了模块化设计,将数据可用性也解耦,允许一个链的区块专门用于数据可用性。

目前,Avail 的区块时间为 20 秒,每个区块可容纳大约 2 MB 数据。假设平均交易大小为 250 字节,每个 Avail 区块今天可以容纳大约 8, 400 笔交易(每秒 420 笔交易)。
更重要的是,Avail 可以始终将区块填满到存储限制,并根据需要增加大小。我们有许多可以快速调整的杠杆,以在需要时将每个区块的交易数量提高到超过 500, 000 笔(每秒 25, 000 笔交易)。
我们能增加吞吐量吗?
为了增加吞吐量(特别是每秒交易数),链的架构师需要增加区块大小或减少区块时间。
要被添加到链上,每个区块必须产生承诺、构建证明、传播它们,并让所有其他节点验证这些证明。这些步骤始终需要时间,这为区块的生成和确认时间设定了一个自然的上限。
因此,我们不能将区块时间简单地减少到比如一秒钟。这样根本没有足够的时间来产生承诺、生成证明,并将这些部分传播给整个网络的所有参与者。在理论上的一秒钟区块时间内,即使每个网络参与者都运行着能够瞬间产生承诺和证明的最强大的机器,瓶颈也在于数据的传播。由于互联网速度的限制,网络无法足够快地将区块通知给所有全节点。所以我们必须确保区块时间足够高,以允许在达成共识后将数据分发到网络中。
相反,通过增加区块大小来也可以增加吞吐量,即增加我们每个区块可以包含的数据量。
当前架构:向链上添加一个区块
首先,让我们看看向链上添加一个区块所需的步骤。向链上添加每个区块需要三个主要步骤。这包括生成区块、传播区块和验证该区块所需的时间。
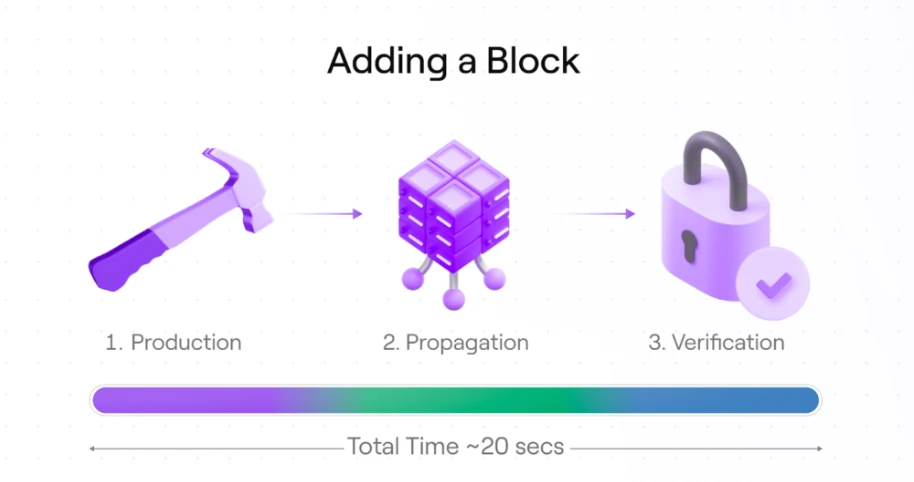
1. 区块生成
这一步包括收集和排序 Avail 交易、构建承诺以及扩展(纠删码)数据矩阵所需的时间。
区块生成测量生成区块所需的时间,因为这至少总是需要一些时间。因此,我们必须考虑不仅是最佳情况下的时间,还有在不同机器上的平均情况和最坏情况下的时间。
能够参与新区块生成的最弱机器是在平均情况下性能达到极限的那一台。所有更慢的机器最终都会落后,因为它们无法赶上更快的机器。
2. 传播延迟
传播延迟是衡量将区块从生产者传播到验证者和点对点网络所需的时间。
目前,Avail 的区块大小为 2 MB。在当前 20 秒的区块时间限制内,这样的区块大小可以被传播。更大的区块尺寸使得传播变得更加棘手。
例如,如果我们增加 Avail 以支持 128 MB 的区块,计算可能能够扩展(约 7 秒)。然而,瓶颈则变成了在网络上发送和下载这些区块所需的时间。
在 5 秒内通过点对点网络向全球发送 128 MB 的区块可能是目前可以实现的极限。
128 MB 的限制与数据可用性或我们的承诺方案无关,而是通信带宽限制的问题。
这种需要考虑传播延迟的需求为我们提供了 Avail 当前理论上的区块大小限制。
3. 区块验证
一旦传播完毕,参与的验证者并不会简单地信任由区块提议者提供给他们的区块 —— 他们需要验证生产出的区块是否真的包含了生产者所声称的数据。
这三个步骤之间存在一定的紧张关系。我们可以让所有的验证者都是强大的机器,并通过同一数据中心的优秀网络紧密连接起来 —— 这将减少生产和验证时间,并让我们传播大量更多的数据。但是,因为我们也希望拥有一个去中心化、多样化的网络,包含不同类型的参与者,所以这并不是一个理想的方法。
相反,吞吐量的提升将通过理解向 Avail 链添加区块所需的步骤,以及哪些步骤可以优化来实现。
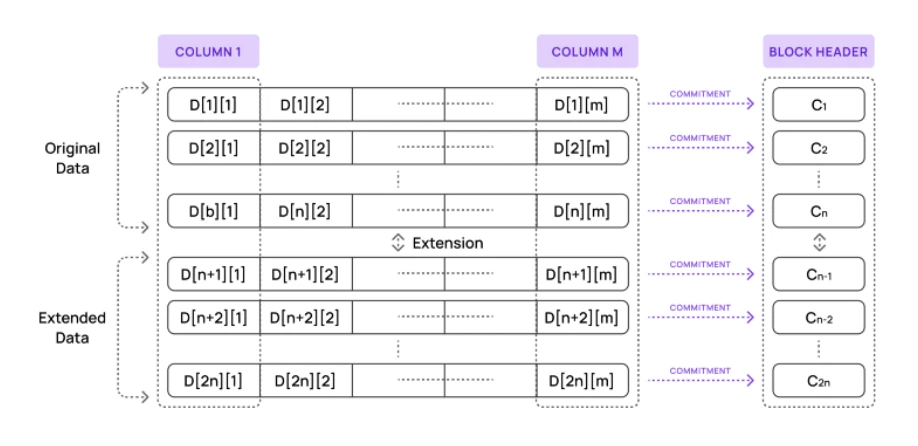
目前,使用 Avail 的验证者会取得整个区块,并复制提议者生成的所有承诺,以验证区块。这意味着区块生产者和所有验证者都需要执行上面图表中的每个步骤。
在单一区块链中,每个验证者重建整个区块是默认做法。然而,在像 Avail 这样的链上,交易不被执行,这种重建并不是必需的。因此,我们可以优化 Avail 的一种方式是允许验证者通过采样来达到对数据可用性的自己的保证,而不是通过重建区块。这比要求他们复制所有承诺,对验证者的资源要求更低。更多相关内容将在后续文章中介绍。
探索数据可用性采样是如何工作的?
在 Avail 中,轻客户端使用三个核心工具来确认数据的可用性:样本、承诺和证明。
-
目前轻客户端执行样本操作,它们向 Avail 网络请求特定单元格的值及其相关的有效性证明。他们采集的样本越多,就越能确信所有数据都是可用的。
-
承诺由区块提议者生成,总结了 Avail 区块中一整行的数据。(提示:这是我们将在本系列后续优化的步骤。)
-
网络中的每个单元格都会生成证明。轻客户端使用证明和承诺来验证提供给它们的单元格的值是否正确。
使用这些工具,轻客户端然后执行三个步骤。
-
决定:所需的可用性信心决定了轻客户端执行的样本数量。他们不需要许多样本(8-30 个样本)就能达到超过 99.95% 的可用性保证。
-
下载:轻客户端然后请求这些样本及其相关证明,并从网络(全节点或其他轻客户端)下载它们。
-
验证:他们查看区块头部的承诺(轻客户端始终可以访问),并针对承诺验证每个单元格的证明。
仅凭这些,轻客户端就能在不需要下载区块的绝大部分内容的情况下确认区块中所有数据的可用性。轻客户端执行的其他步骤也有助于 Avail 的安全性,但未在此列出。例如,轻客户端能够与其他轻客户端共享他们下载的样本和证明,以防他们需要。但这就是轻客户端确认数据可用性的程序!
在本系列的第二部分中,我们将探讨短期内提高 Avail 吞吐量的方法。我们将解释为什么我们相信 Avail 能够满足未来一年内任何网络的需求,并且如何改进网络以迎接未来几年的挑战。


