




ChatGPT恢复了Plus付费购买,GPT-4又能“花钱”使用了。但有不少用户发现,最近这个增长最快的对话机器人的响应速度变慢了不少,之前,它还出现过大规模封号和时常掉线的情况。
4月5日,ChatGPT Plus付费功能的停摆已经引发外界对AI算力供给不足的担忧。当前,市面上已经不仅ChatGPT一个文本生成大模型的应用了,同类产品有谷歌的Bard、百度的文心一言,市面上还有图片、音视频、3D效果甚至App的生成式AI大模型。
多模态大模型井喷式出现,支撑它们的算力还够吗?
目前,供给主流AI大模型的高性价比芯片是英伟达的A100,从去年开始,英伟达就在向代工厂台积电下急单,催产多种芯片,其中就包括A100,足见当前AI算力的紧俏。而OpenAI关于GPT-4.5、GPT-5的推出已经列出了时间表。
爱丁堡大学超级计算中心马克·帕森斯的预言正在成真,“算力会成为AI大模型发展的阻碍”,除了高性能芯片量产的局限性之外,还有芯片带宽的问题亟待解决。

ChatGPT暂停付费服务引发算力担忧

“因为需求量太大,我们暂停了升级服务”,这是4月5日ChatGPT停止Plus付费购买功能时给出的理由,当时距离它开通Plus功能仅仅2个月。
一天后,ChatGPT又恢复了Plus的订阅,人们又能以每月20美元的价格享受会员服务了,包括使用最新模型GPT-4、在高峰时段正常访问、拥有更快的响应速度等等。当有会员用户感觉,ChatGPT的响应速度变慢了,宕机时总是显示“Oops”的遗憾声的页面越来越频繁地出现,“服务器跟不上了?”
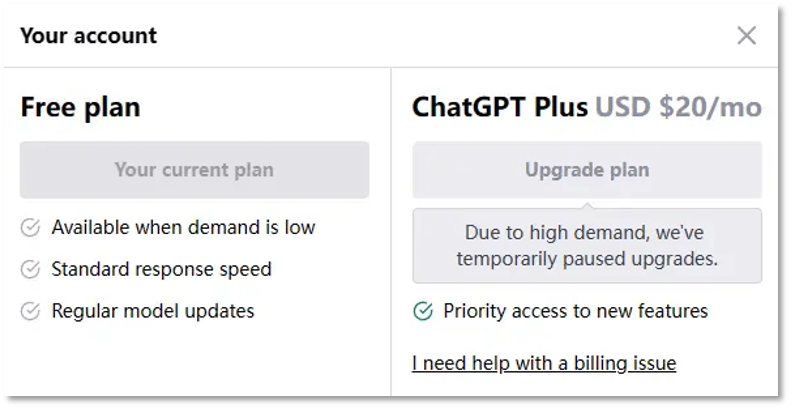
4月5日,ChatGPT暂停Plus付费服务
哪怕在停售Plus之前,ChatGPT突然无法使用的情况也大规模地发生过。3月20日,它曾全球性宕机12小时,付费用户也未能幸免,官方公布的原因是“数据库迁移”;到了3月30日,有大量亚洲用户发现被封了号,“用访问范围门槛减少访问量”的怀疑声出现。
降低访问量的确是ChatGPT研发方Open AI在做的事。近期,该公司多次下调付费用户的访问次数,起初,用户可以每四小时和GPT-4对话100次;不久后,下降到每四小时50次;再之后,变成每三小时25次。但即便如此,社交网络上仍然有不少人在反馈,ChatGPT掉线的频率在增加。
随着用户量的增加,ChatGPT已经暴露出访问响应速度跟不上的问题,而OpenAI似乎并不打算停止模型的升级。
日前,该公司公布了GPT未来版本的规划,预计在今年9、10月推出GPT-4.5,在今年第四季度推出GPT-5。在种种爆料中,GPT-5的性能相较于GPT-4有着指数级别的进化,拥有在视频、音频中读取信息等神奇能力。
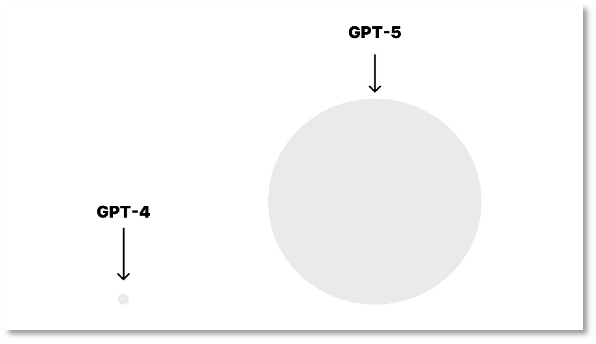
以“点和圆”比喻GPT-4与GPT-5的差异
人们在佩服OpenAI研发能力的同时,也在担忧供给GPT模型的“能源”——算力能否跟上的问题。毕竟,需要算力研发AI大模型的,不只OpenAI,还有开发各种多模态大模型的其他公司。而一个文本生成都被ChatGPT限制访问成那样,将来音视频生成,岂不是更费?
OpenAI自己也测算过,2012年以来,全球AI训练的计算量呈指数级增长,每3.43个月就会翻一倍。那么,到底GPT会用掉多少算力?

英伟达A100成AI“石油”
算力,即计算机处理数据的能力,与数据、算法并成为人工智能的三大基石。而GPT这样的大语言模型的建立需要大量的计算能力,GPU芯片是主要的算力产出工具。
据公开数据,GPT-3具有1750亿个参数,45TB的训练数据,有上万枚英伟达的A100芯片支撑。如果缺乏足够的高性能芯片,训练的效率将大大降低。英伟达和微软研究院的一篇论文这样假设,“假设我们在单个GPU中拟合模型,所需的大量计算操作可能导致不实际的超长训练时间”,而GPT-3在单个V100英伟达GPU上估计“需要288年的时间”。2017年发布的V100显然已经不够高效,更具性价比的选择是A100芯片,售价超1万美元,性能确实V100的3.5倍。
OpenAI并没有公布GPT-4的参数规模,外界传闻的“100万亿参数”已经被该公司CEO山姆·阿尔特曼(Sam Altman)否认,但从研究人员根据前代模型数据的推测和媒体从内部人士获得的信息看,GPT-4的参数量至少在万亿级别。这也意味着,GPT-4的参数量是GPT-3的10倍以上,相应地,GPT-4的算力需求也在指数级上升。
GPT-4上线后,微软就被传出GPU数量告急的传闻。有媒体报道,微软内部需要用GPU做研究的团队被告知,想用GPU必须经过特殊渠道申请,因为“公司的大量GPU需要用于支持Bing的最新AI功能和GPT的模型训练”。
对此,微软负责商业应用程序的副总裁查尔斯·拉马纳(Charles Lamanna)向媒体解释,“没有无限量的GPU,如果每个人在每次活动、每个会议上都使用它,那么可能就不够用了,对吧?”
微软不差钱,也不存在被芯片“卡脖子”的情况,为什么不砸钱“买买买”?事实上,全球芯片量产的种类虽多,OpenAI最需要一种——GPU,而这种芯片主要由英伟达供给。
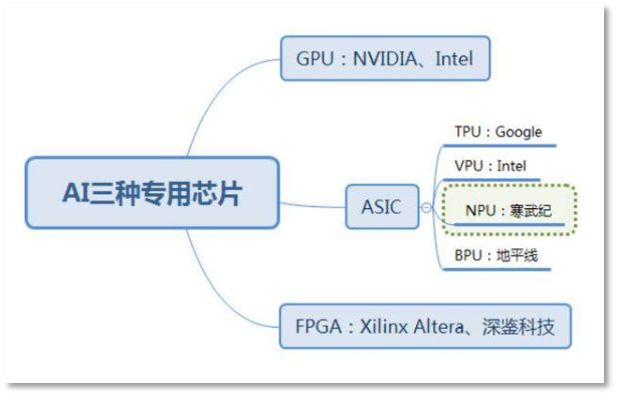
AI三种专用芯片及其供应商
而在GPU市场,英伟达长期占据主导地位。根据Verified Market Research的数据,英伟达在数据中心GPU市场占比超过80%,云端训练市场占比超过90%,云端推理市场占比60%。
英伟达在2020年推出首款安培架构产品A100芯片,目前已经成为人工智能行业最关键的工具之一。A100可以同时执行许多简单的计算,非常适用于进行“推理”或生成文本。无论是开发聊天机器人,还是图像生成软件,足够多数量的英伟达A100都至关重要。
Stateof.ai去年发布人工智能发展报告估算了部分大公司和机构拥有的A100数量,其中,开发出AI绘图软件Stable Diffusion的的Stability AI拥有4000个A100。按照这个数据对比国内首个类ChatGPT模型MOSS,它只用了8个A100,难怪内测时被“挤崩”了。
这份报告不包括OpenAI的数据,不过,根据市场调查机构TrendForce估算,ChatGPT在训练阶段需要2万块A100,而日常运营可能需要超过3万块。
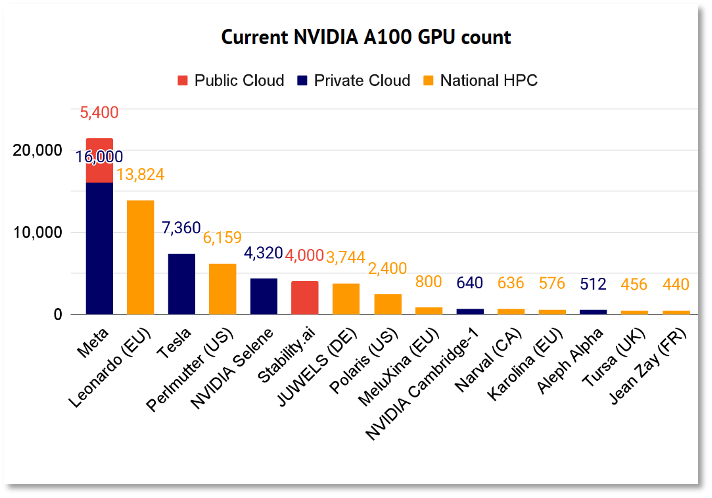
A100俨然AI大模型研发圈的“抢手货”,英伟达也有意普及,但到了量产环节,全球最大的芯片代工厂台积电的产能有点跟不上。去年年底和今年一季度,英伟达都给台积电下了急单,由于芯片的重要部件7nm晶圆片在台积电的产量固定,因此,产能利用率提升还需要一个爬坡期。
B站科技UP主“动动枪”分析,考虑台积电的生产线和产能相对固定,增开生产线没那么容易,“英伟达在一段时间内会将主要产能放在专业级GPU上,来满足企业、云服务商对高算力芯片的需求”。

除了算力 还得改善芯片带宽
早在GPT-4发布前,爱丁堡大学超级计算中心EPCC主任马克·帕森斯(MarkParsons)已经预言过,算力会成为AI大模型发展的阻碍。
帕森斯指出,由于用于训练系统的最大GPU的内存容量有限,所以需要多个处理器并行运行,但是使用并行运行的处理器也有局限性,因为当GPU超过一定数量,单个GPU的性能会受限制,同时成本也会增加。也就是说,AI芯片的算力会出现类似边际效用递减的情况,人们无法靠无限增加芯片来提升算力。
此外,帕森斯教授认为,当前AI芯片的带宽也会成为AI发展的瓶颈,因为带宽决定了AI芯片每秒钟可以访问的数量。
“在一个GPU上训练了一个子集数据后,你必须将数据带回、共享,并在所有GPU上进行另一次训练,这需要大量的芯片带宽”,帕森斯教授说道。而当前最大的挑战就是“如何改善GPU服务器之间的数据传输”。
有人向新必应询问为什么GPT会出现算力不足的现象,它和帕森斯所见略同,也强调了GPU带宽的重要性:
GPT算力不足,主要是因为它的模型规模和数据量都在不断增长,而现有的数据处理器性能和能效都难以满足其需求。GPT使用的处理器主要是GPU(图形处理器)和TPU(张量处理器),这两种处理器都是专门为深度学习而设计的,并且具有高度的并行性和矩阵运算能力。然而,随着GPT模型参数数量的增加,GPU和TPU的内存容量和带宽都成为了瓶颈,导致训练效率下降。此外,GPU和TPU的功耗也很高,给电力和散热带来了挑战。因此,GPT需要更高性能和更低功耗的处理器来支持其发展。
看上去,当前芯片数量和性能都在限制AI大模型的发展“资源”。而GPT模型的参数量仍在高速增长中,据悉,每18个月左右就会增加10倍,这无疑对全球的算力提出更高的要求。
如果ChatGPT真的是因为算力不足而出现限流、宕机的情况,那么,自然语言生成式大模型未来可能会集体触碰AI发展的天花板。归根结底,卷来卷去的大模型,最终还得看英伟达等芯片供应商的迭代能力。


