GPT-4震惊四座,中国创业者激战“小模型”



作者:周鑫雨

发布ChatGPT仅三个多月后,OpenAI亲手为这场大模型热潮再添了把柴火。
北京时间3月15日凌晨,OpenAI在官网上宣告了多模态大模型GPT-4的诞生。优化了模型可支持的输入模态、文本长度等性能之外,OpenAI在GPT-4的基础上升级了ChatGPT,并一举开放了API——迭代的速度之快,令人咋舌。
在这场属于大模型的狂飙中,数字已经让人麻木。首先是模型的参数量——此前,OpenAI用GPT-3(参数量达1750亿)将大模型的参数量卷上千亿级别,但很快,谷歌在3月6日推出的多模态大模型PalM-E,则用5620亿的参数坐上了“史上最大视觉语言模型”的位置。
其次是公司狂飙的估值。全球早期项目数据服务商Dealroom的报告显示,全球生成式AI企业的估值达到总计约480亿美元,在2年里翻了6倍。
国内AI赛道升温来得晚,但企业估值飙升的速度有过之无不及——王慧文的AI公司“光年之外”,天使轮的估值达到了2亿美金。一家由某位技术大拿近期创立的大模型企业,模型demo还没影子,天使轮的估值也让其进入了亿元美金俱乐部——而在元宇宙的风口中,百万美金,似乎已经是国内创企天使轮的估值天花板。
风口中,也有一些纠结、负面的声音浮现。
3月2日晚,一篇主题为“为什么感觉欧美的AI比我们强”的贴文引起不少争议。发帖者比较了中美的AI发展环境,将欧美AI的发展视作卧薪尝胆的“精英教育”,而国内则是重商业化的“功利教育”,最后得出了一个略显绝望的结论:人的命运在子宫里就注定了,机器人也不可幸免。

主题为“为什么感觉欧美的AI比我们强”的贴文。图源:微博@陈怡然-杜克大学,贴文由其转载
当下,大模型的暴力美学对于多数企业来说,或许并非全力以赴的最好选择。算力、高质量数据,以及高密度的算法人才,这些都是上大模型牌桌所需的昂贵入场券,国内多数玩家无法在朝夕之间拥有等同OpenAI的储备。
但丰富的数据维度和广阔的应用场景,是上一波持续了10多年的互联网浪潮,留给中国创业者的富矿。近一个月以来,不少有场景、有用户数据的小企业,已经基于国内外大模型的基座,训练出适配自身业务的小模型。而一家拥有百亿参数大模型储备的公司,也自行“瘦身”,针对金融、广告等领域,推出了轻量化的模型,以进行新一轮的数据储备。
当下,用小模型打磨算法的利刃,为大模型的研发做好技术储备,或许是中国创业者在未来实现弯道超车的一条通路。
“全才”大模型 vs “专家”小模型
如何让AI更聪明、更像人,本质上是一个教育问题。
此前的很长一段时间,人们热衷于将AI送进“专科院校”,学会解决特定问题的能力——参数量往往低于百万的小模型由此诞生。比如谷歌旗下的AI公司DeepMind,让AlphaGO对上百万种人类专业选手的下棋步骤进行了进修,最终在2016年以4:1的成绩战胜围棋名将李世石。
但专科教育的弊端也很明显,小模型大多都有偏科的毛病。比如面对写营销文案时,精于图片生成的小模型就碰了壁。同时,专科的教育资源分散,每个小模型都需要分别从头进行基础训练。
作为父母的人类,大多有着培养出全才的期望。2017年,谷歌发明了一种新的教育方式:Transformer模型。
以往的“专科教育”中,AI的学习十分依赖人类对学习资料的标注和挑选,比如AlphaGO的学习资料来自于专业棋手,而非上围棋兴趣班的孩子。而Transformer训练方式的精髓在于让AI通过大量的预习,自行对不同科目的学习资料“划重点”。
用于训练的数据越多,模型预习的效果越好;参数越多,模型划出的重点也就越精确。自行划重点的教育方法解放了人类的双手,同时让AI对不同科目多管齐下,实现了跨领域的知识积累。
2018年,谷歌基于Transformer发布了首个参数过亿的基础模型BERT,并在翻译这门科目上,成绩远优于神经网络培训(比如CNN和RNN)模式下培育的模型。
自此,Transformer席卷了模型教育界,大模型的“大”,也被不少公司卷了起来。目前,100亿的参数量被业界认为是模型能力实现跃升的拐点。
大模型最为直观的优越性,在于有小模型难以企及的推理演绎能力,能理解更复杂、更广阔的场景。
除了内容生产领域外,大模型还能用在哪?移动互联网服务商APUS创始人李涛还举了一个例子:一线城市的交通拥堵,80%的问题根源不在于过多的车辆,而在于协同程度低的智慧交通系统——每个路口红绿灯的秒数设置成多少?不同路段的红绿灯如何配合?仅靠人或者小模型,这些问题难以解决。
而大模型的出现,让巨量的交通数据有了用武之地,“人最多只能根据一个路段的交通情况做出决策,而大模型能够看得更全面”。
大模型更大的潜力,还在于能够降低小模型训练的成本。大模型好比是历经了义务教育的孩子,在此基础上,上大学选专业,进而成为更高阶的专业人才是件成本较低、水到渠成的事。
这也意味着,有了大模型作为基座,从中训练出针对特定应用场景的轻量模型,能够省去从0开始培养基础理解的过程。当然,这一做法的风险是,大模型的能力会直接影响培育出模型的质量。
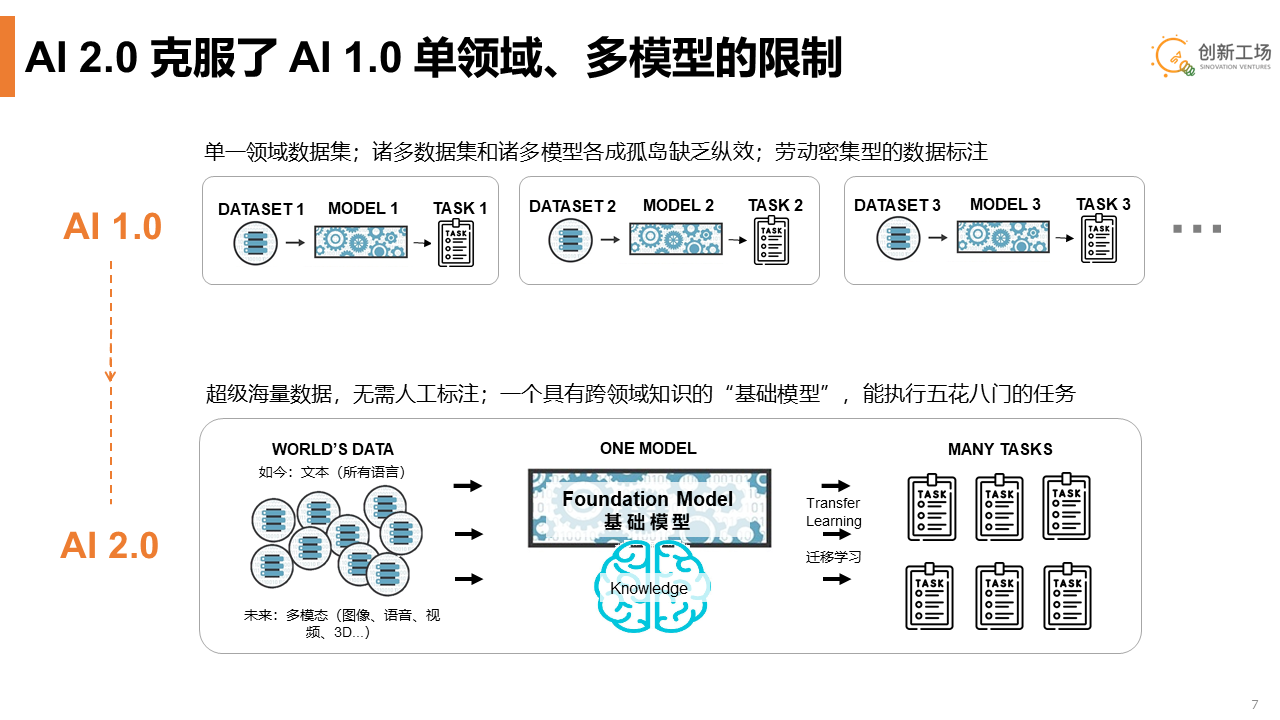
大模型/基础模型出现的AI 2.0时代 vs 此前的AI 1.0时代下,人工智能落地到应用的过程。图源:创新工场
以ChatGPT为代表的生成式AI,则是大模型时代下,从象牙塔走向广阔应用的第一批优秀毕业生。GPT-3.5是掩藏在语言生成能力出众的ChatGPT背后的大模型基座,低调,但作用巨大——如今,它已经的教育资源已经升了级,迭代成了GPT-4。
不过,大模型时代的到来,并不意味着高精尖的中小模型将被淘汰。落地到具体的应用,经济性就不得不被企业纳入考量之中,给成本昂贵的大模型“瘦身”显得尤为重要。“具体的应用场景,未来依然会是中小模型的天下。”李涛总结。
发展大模型难在哪?
一个月以来,不少号称“类ChatGPT”的对话应用涌入市场。
仅从日常对话体验出发,每一款产品的差异似乎并不大。忽悠或取悦提问者、时效性差等问题仍是通病,但相较囿于特定场景和答题模板的智能客服,当下涌现的对话机器人已经让人初步有了“想继续聊下去”的兴趣。
但再往下深究模型的参数、Token等细节,一切又变得不那么乐观。自研模型达到百亿参数规模的初创企业寥寥无几,而参数规模可观的企业,不少又有些猫腻。
为了测试大模型的能力,一位互联网企业的战略分析师向36氪展示了他设计的创意写作、新闻检索、逻辑推理等300-400组Prompt(问答提示),对十多个突破10亿参数规模的“类ChatGPT”应用进行逐一测试需要花上两三个月的时间。
测试后,他发现大多产品的回答模式和ChatGPT太类似了:“很难让人不怀疑,‘自研’模型的水分有多少。”
为什么目前国内仍然没有出现ChatGPT?多数从业者都觉得答案显而易见,却又让人无奈:做大模型不仅得花大量金钱和时间“死抠”,还需要愿意不计成本投入其中的社会环境。
算力、算法、数据、场景,这是跑通大模型的四个关键要素。前两者也是可以想见的浮于海平面上的困难,尤其对于小公司而言。
《ChatGPT中国变形记》 一文对这些灵魂拷问都有所提及:想要跑通一次100亿以上参数量的模型至少需要用1000张GPU卡训练一个月,一定程度上决定算法能力的人才又大多聚集在硅谷或实力雄厚的大厂。
掩藏在海面下的困难,则是长期以来囿于商业回报的行业价值观。
“自改革开放以来,中国经济保持了30多年的高速增长期,并快速跻身世界前列,这和互联网发展拉动更多行业进行快速商业化落地有很大关系。”一名在国内外互联网企业AI团队近20年的从业者告诉36氪。但发展的经验,亦成了惯性的枷锁,“在ChatGPT所带来的新机会面前,我们不可避免地仍然用旧的商业回报的视角去加以评估”。
不少投资人也觉得,爽快地拿钱是件不容易的事。受中概股形势严峻、企业赴美上市难等因素影响,不少科技企业对美元基金的态度变得保守谨慎。而如今政府主导基金在人民币LP中的比例加大,基金募集人民币面临更大的挑战。
夹在其间的双币基金更是面临着两头不讨好的困境。“除了个别不缺钱的头部基金,大部分投资机构都在观望。”一名双币基金投资人表示。
即便训练出了大模型,依然没有人敢断定,资金回报一定会在“5+2”的投资周期后到来。
3月2日,OpenAI以$0.002/1000 tokens(约等于100万个单词/18元人民币)的“白菜价”公开了ChatGPT的API,往行业投掷了一枚不确定性的炸弹。仅过了半个月,GPT-4又以终结者的姿态空降赛道。这更是让国内不少企业觉得:“卷不过。”
最先受到冲击的是模型层的公司,模型性能还没磨到能与ChatGPT同台竞技的水平,又失去了定价权。
内容行业的改革也不可避免,如搜索、设计、文案撰写等等。一名互联网搜索业务的员工聊起响应新技术改革过程时的无措:“比如与营收直接挂钩的广告,在生成式AI接入后,用户可能拥有选择不看广告的权利;即便放上广告,接入大模型后搜索的成本也翻了番。”
而商业变现的想法,看似只需在现有应用上前缀“AI+”一般简单,却又不甚明朗。
“朦胧美”,不少投资人如此形容近两个月AI赛道上的标的。“ 在科技行业,很多新技术一开始都是主题投资,投的是一种想象力经济。 ”一名经历了元宇宙、Web3等诸多风口的投资人告诉36氪,“我们倾向于认为目前的‘AI+’都有做成的可能,但也正因为如此,企业的vision(远见卓识)和商业模式在寻求融资的过程中会被更加强调。”
一个月前见到一名双币基金的投资人时,她正拒绝了一家立下“1年内训练出大模型”军令状的公司。最近再见她,对方用同样的两个问题劝退了不少赶风口的企业:
“你们做大模型的必要性在哪?”
“有什么明确的商业模式吗?”
场景和数据,国内小模型的机会
但好在,中国不缺AI模型的落地场景,以及丰富的用户数据——这让国内公司在培育大模型这一“西瓜”的同时,还能收割轻量化模型撒下的“芝麻”。
回到模型训练的本质:量变引起质变。暴力出奇迹的基础在于海量的数据,而我国超10亿规模的互联网民,已经给大模型的研发提供了足够的燃料。席卷了近十年的数字化浪潮,又让AI在足够多的成熟产业有快速落地的可能,同时又能为方兴未艾的行业注入新血。
不少曾经立下“All in 大模型”flag的基金,经历了近3个月的火热后,选择自行降温。一名双币基金投资人告诉36氪,团队已经调整了投资战略,“比起投一家模型层公司,不如和现有的portfolio(投资组合)讨论如何接入模型优化业务。”
但聚焦到特定的应用场景,最终发挥作用的往往不是大模型,而是轻量的中小模型 。大模型涉猎广,但对具体场景的推理演绎能力往往不如“专家”中小模型。另一方面,从更现实的成本问题出发,中小模型能将大模型运行所需的算力成本降到1/10甚至1/100。
李涛认为,国内企业现阶段可以奉行的是“拿来主义”,基于海外的开源大模型,将中小模型打磨至顶尖水平:
“现在国内企业能跑通的是这样一条路:用海外大模型对落地场景进行验证,再基于我们丰富的数据资源训练中小模型,最后落地至具体场景——大模型的4个要素,除了算力是长跑,剩下3个都是能够把握在手里的。”
这也意味着,国内有场景、有数据的模型层公司,在OpenAI给予的竞争压力下,依然能抓住不少机会。中小模型落地后,各行各业积攒的数据又能成为自研大模型的“飞轮”。
目睹OpenAI踏出一条明路后,也有更多人愿意不计较太多成本,涌向“无人区”。
比如基于“用AI操纵AI”的想象力,在海外,一些通过大模型搭建“下一代RPA(Robotic process automation,机器人流程自动化)平台”的公司,已经受到了资本的青睐。
最典型的案例是去年4月,含着谷歌AI核心研发团队这一“金汤匙”出生的美国AI创企Adept,迅速拿下了6500万美元的A轮融资。类似方向的公司还有得到a16z投资的Replicate,以及德国的Deepset。
“RPA+AI”这一应用方向的突破性在于,将大模型落地为调用和控制智能工具的中台,让企业在少代码化操作的情况下智能化调用相应的数字工具。一名相关方向的国内创业者预估,“未来十年内,RPA行业可能不再单独存在,数字化工具可以无代码地直接连接到个体。”
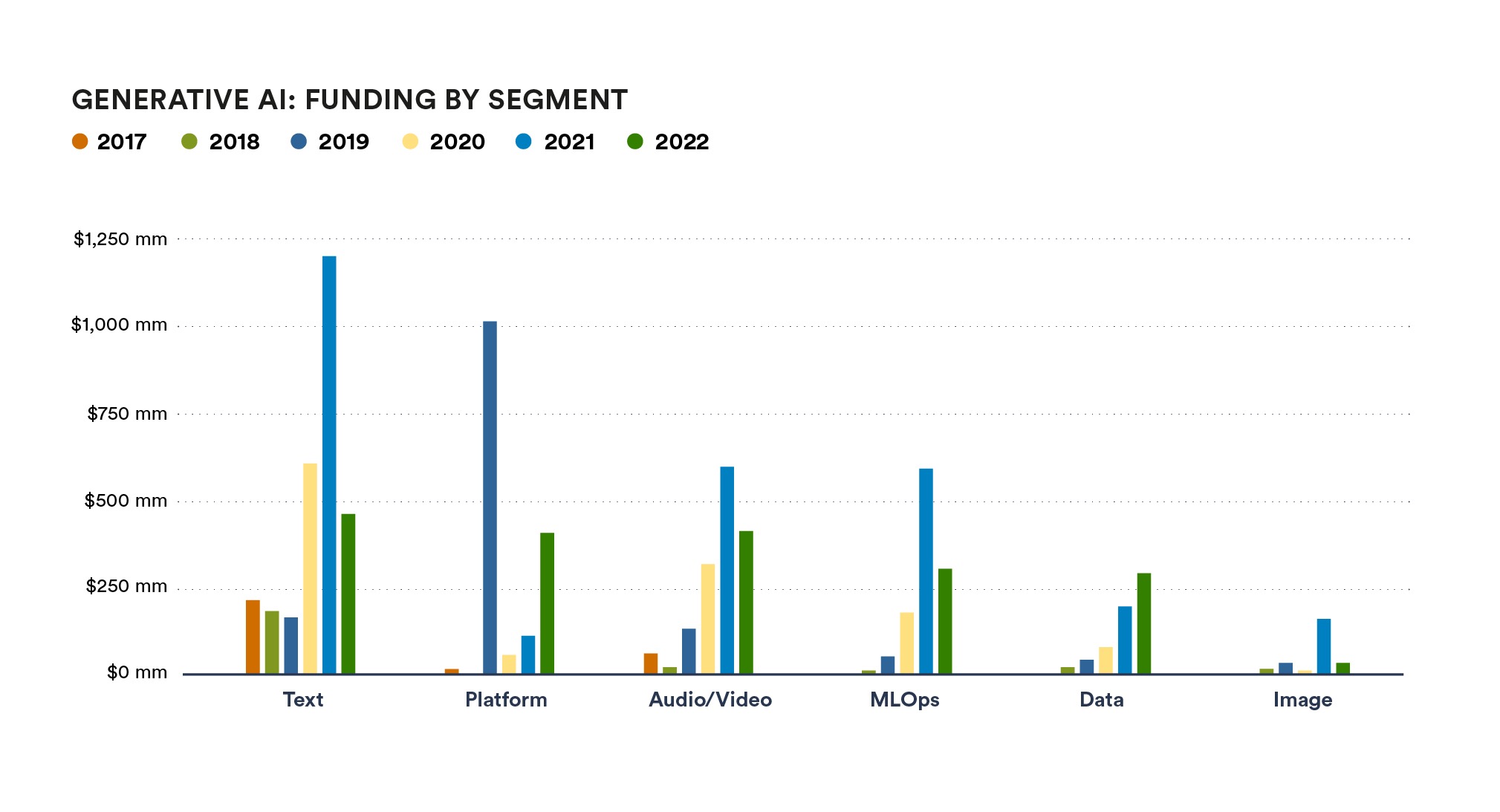
2019年-2021年期间,海外流向生成式 AI 业务的资本增加了约 130%,增长主要由机器学习运维(MLOps)、文本写作、数据等领域拉动。图源:Base10
服务于模型训练、管理、运维的一些中间业态也初步形成。比如,一些企业研究出了让模型训练成本更低、效率更高的模式,让人们只需用一张消费级GPU的显存,就能实现对ChatGPT的部分复刻。
无论是保守冷静,还是拥抱不确定性,投资人们首先要面对的是浪潮中水涨船高的企业估值。多少是企业的本事,多少是泡沫中的水分,在被ChatGPT卷起的AI梦真正落地前,让赛道去伪存真,也需要经历一定的时间。


