一文了解 ZK 在推进链上 AI 的作用



原文来自: Modulus Labs
编译:DeFi 之道
很高兴终于可以与你们分享我们的第一篇论文,该论文是通过以太坊基金会的资助完成的,它的标题是《 The Cost of Intelligence: Proving Machine Learning Inference with Zero-Knowledge 》(或 paper0,这是酷孩子们的叫法)。
没错,这些都是真数字!有图表!论文还讨论了理论结构及其对性能的影响!事实上,paper0 是第一个跨通用 AI 原语套件对 ZK 证明系统进行基准测试的研究工作,你现在就可以阅读整篇论文。
而这篇文章,你可以将其视为论文的总结,有关详细信息,请参阅原论文。
事不宜迟,让我们深入了解:
Paper0 : 我们的调查要点
事实上,计算的未来将大量使用复杂的人工智能。看看我的文本编辑器:

Notion 的提示告诉我,他们的 LLM 可以让这句话变得更好
然而,链上不存在功能性神经网络,甚至连最小的推荐系统或匹配算法都不存在。真见鬼!甚至连实验也没有一个……当然,原因是非常明显的,因为这太贵了,毕竟,即使运行价值数十万 FLOP 的计算(仅够在微型神经网络上进行一次推理)的成本也是数百万 gas,目前相当于数百美元。
那么,如果我们想将 AI 范式带入无需信任的世界,我们该怎么做?我们会翻车(roll-over),然后放弃(give up)吗?当然不是…等等! Roll -over)……Give up ……
如果像 Starkware、Matter Labs 和其他公司这样的 Rollup 服务,正在使用零知识证明来大规模扩展计算,同时保持密码学安全,那么我们能为 AI 做同样的事情吗?
这个问题成为推动我们在 paper0 中工作的激励种子。 剧透警报,以下是我们发现的:

“现代 ZK 证明系统的性能越来越高,并且越来越多样化。它们已经可以支持成本在某种程度上是合理的人工智能操作。
事实上,有些系统在证明神经网络方面比其他系统好得多。
然而,所有这些仍然达不到实际应用所需的性能,并且对于神奇的用例来说是严重不足的。
换句话说,如果不进一步加速用于 AI 操作的 ZK 系统,用例就会非常有限。“
paper0 总结
这是众所周知的秘密:AI 性能几乎总是与模型大小成比例。 这种趋势看起来也没有放缓。 只要这种情况仍然存在,对于我们这些 web3 中的人来说,这将是特别痛苦的。
毕竟,计算成本是我们最终、不可避免的噩梦来源。

今天的 ZKP 已经可以支持小模型了,但中型到大型模型打破了范式
基准:实验设计
对于 paper0,我们关注任何零知识证明系统中的 2 个基本指标:
- 证明生成时间 :prover 创建 AI 推理的伴随证明所需的时间,以及
- prover 内存使用峰值 :证明者在证明期间的任何给定时间用于生成推理证明的最大内存;
这主要是一个实际的选择,并且是从我们构建 Rockybot 的经验中做出的(证明时间和内存使用是确定任何无需信任人工智能用例可行性的直接优先事项)。 此外,所有测量都是针对证明生成时间进行的,并且没有考虑预处理或 witness 生成。
当然,还有其他方面的成本需要跟踪。 这包括验证者运行时间和证明大小。我们将来可能会重新审视这些指标,但将它们视为 paper0 的范围之外。
至于我们测试的实际证明系统,通过投票,我们选定了 6 个:
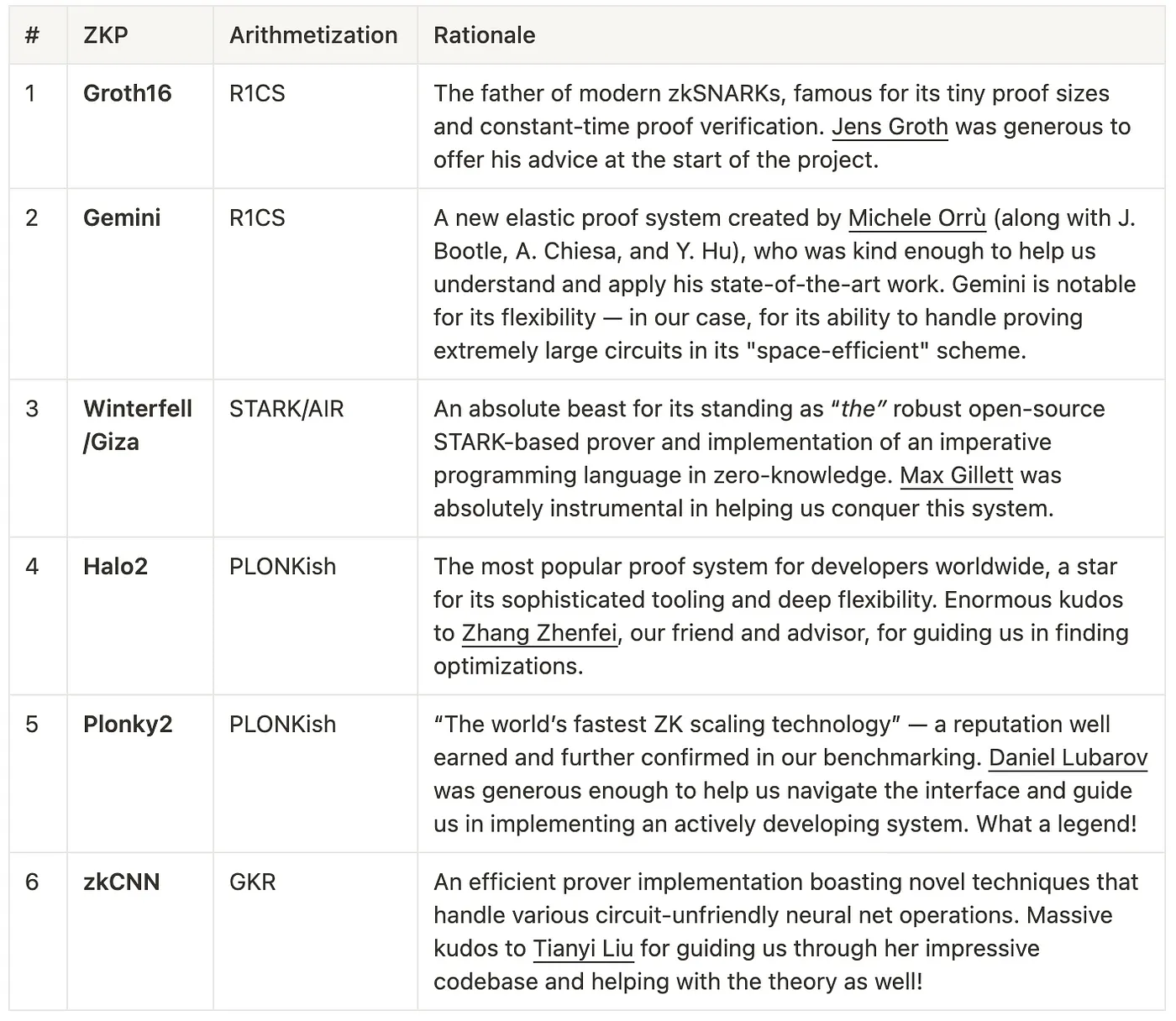
Paper0 测试的证明系统汇总表,以及协助我们的作者
最后,我们创建了两套用于基准测试的多线性感知器(MLP)——值得注意的是,MLP 相对简单,主要由线性运算组成。这包括一套随着参数数量增加而扩展的架构(最多 1800 万参数和 22 GFLOP),以及第二套随着层数增加而扩展(最多 500 层)的架构。如下表所示,每个套件都测试了证明系统以不同方式扩展的能力,并大致代表了从 LeNet5(6 万参数,0.5 MFLOP)到 ResNet-34(2200 万参数,3.77 GFLOP)的知名深度学习(ML)架构的规模。
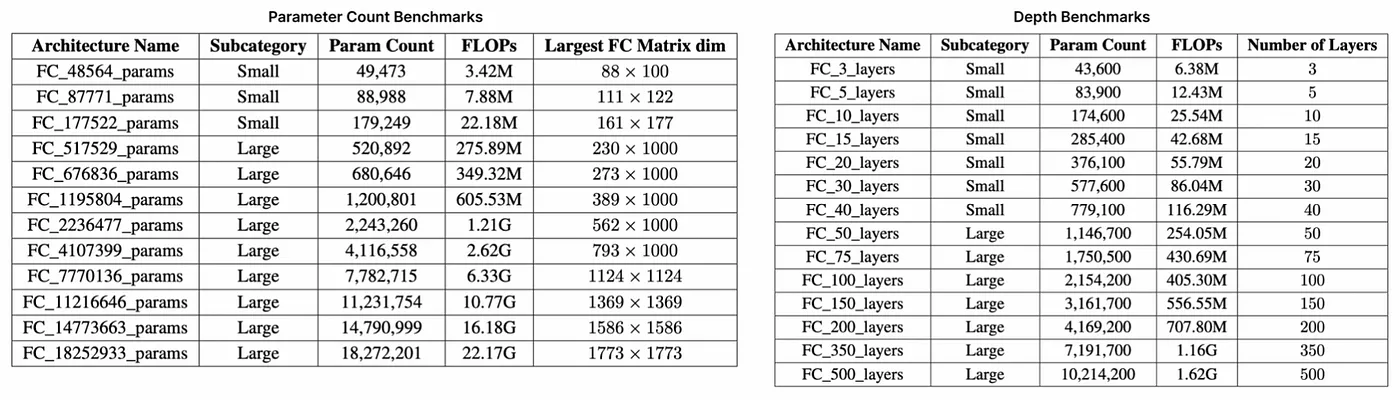
参数和深度基准套件
结果:迅如闪电
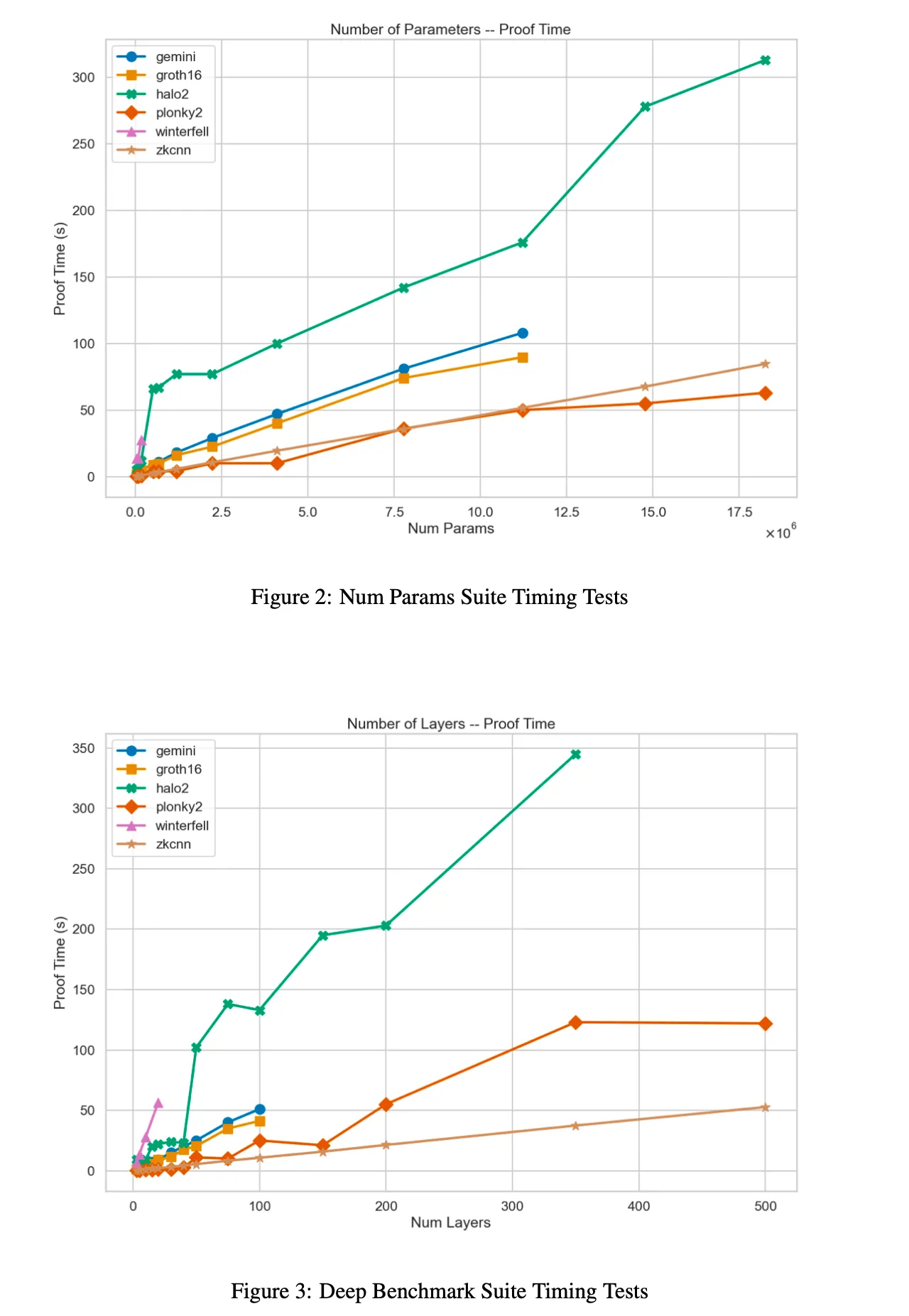
对于以上 6 个证明系统的参数和深度范围的证明生成时间结果
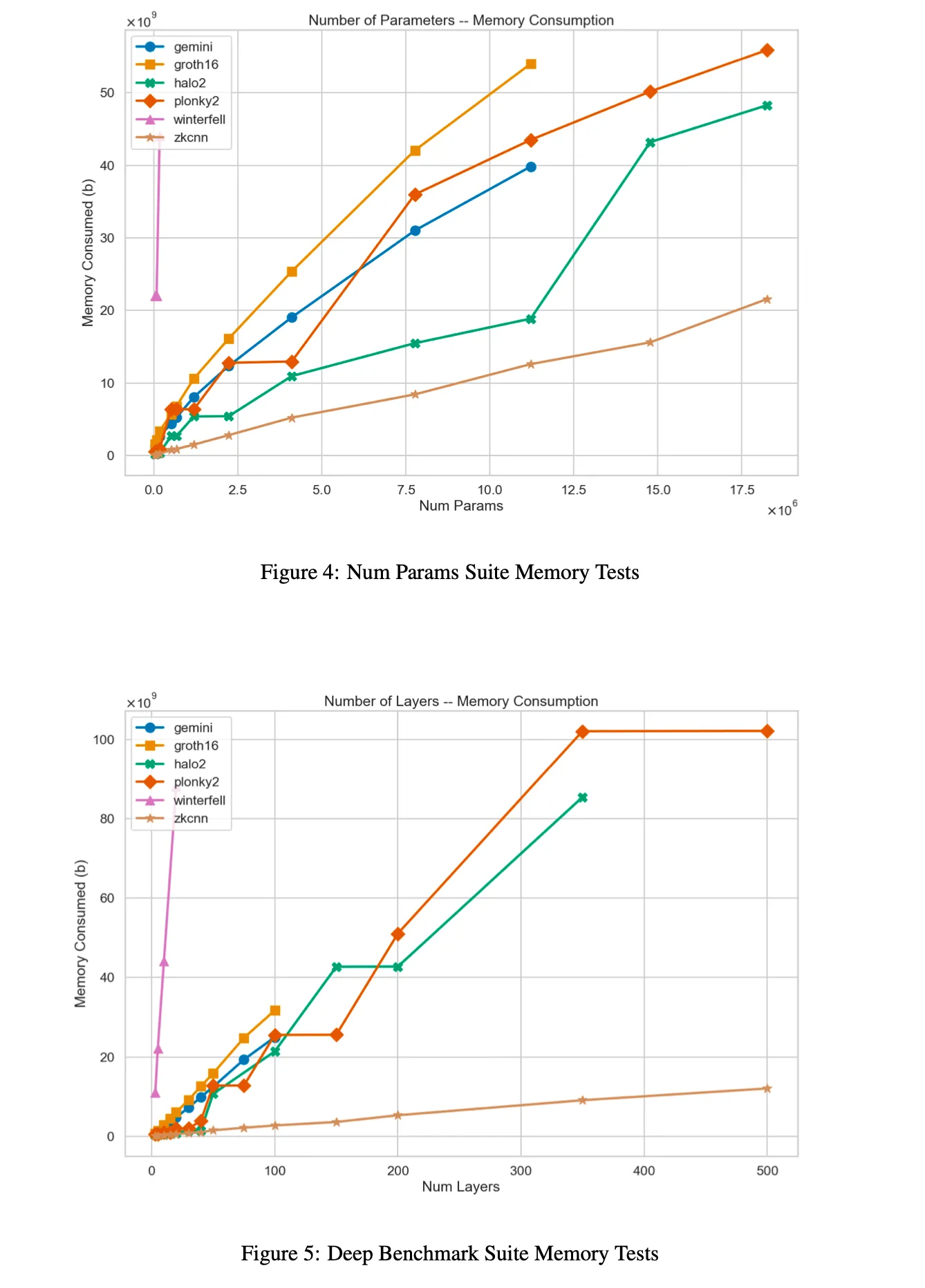
对于以上 6 个证明系统的参数和深度范围内的峰值内存结果
有关这些结果的完整内容,以及对每个系统内瓶颈的深入分析,请参阅 paper0 的第 4 节。
用例和最终要点
好吧,以上是一些非常简洁的图表,而以下则是要点:
“在证明时间方面,Plonky2 是迄今为止表现最好的系统,因为它使用了基于 FRI 的多项式承诺和 Goldilocks 域。 事实上,对于我们最大的基准架构,它比 Halo2 快 3 倍。
然而,这是以 prover 内存消耗为显著代价的,Plonky2 的性能始终较差,有时会使 Halo2 的峰值 RAM 使用量翻倍。
在证明时间和内存方面,基于 GKR 的 zkCNN prover 似乎最适合处理大型模型——即使没有优化的实现。”
那这在实践中究竟意味着什么? 我们将重点介绍 2 个示例:
1、Worldcoin:Worldcoin 正在构建世界上第一个“隐私保护身份证明协议”(或 PPPoPP),换句话说,通过将身份验证与一种非常独特的生物特征(虹膜)联系起来来解决女巫攻击问题。这是一个疯狂的想法,它使用卷积神经网络来压缩、转换和证明存储的虹膜数据。虽然他们当前的设置涉及 orb 硬件中安全飞地内的可信计算环境,但他们希望改为使用 ZKP 来证明模型的正确计算。这将允许用户对自己的生物特征数据进行自我保护,并提供加密安全保证(只要在用户的硬件上进行处理,比如手机)。
现在具体一点:Worldcoin 的模型具有 180 万参数和 50 层。 这是区分 100 亿个不同虹膜所必需的模型复杂性。 哎呀!
虽然在计算优化的云 CPU 上证明 Plonky2 等系统,可以在几分钟内为这种规模的模型生成推理证明,但证明者的内存消耗将超过任何商用移动硬件(数十 GB 的 RAM)。
事实上,没有一个测试系统能够在移动硬件上证明这个神经网络……
2. AI Arena:AI Arena 是一款类似于《任天堂明星大乱斗》风格的链上平台格斗游戏,其具有一个独特的特点:玩家并不是操作化身实时进行对抗,而是让玩家拥有的 AI 模型相互竞争和战斗,是的,这听起来很酷。
随着时间的推移,AI Arena 的出色团队正努力将他们的游戏转向一个完全无需信任的锦标赛计划。但问题是,这涉及验证每次游戏数量惊人的 AI 计算的挑战。
比赛以每秒 60 帧的速度运行,持续 3 分钟时间。这意味着每轮比赛,两个玩家模型之间的推理结果超过 20000 个。以 AI Arena 的一个策略网络为例,一个相对较小的 MLP 需要大约 0.008 秒来执行一次前向传递,使用 zkCNN 证明该模型需要 0.6 秒,即,每采取一次动作就需要增加 1000 倍的计算。
这也意味着计算成本将增加 1000 倍。随着单元经济对链上服务变得越来越重要,开发人员必须平衡去中心化安全的价值与证明生成的实际成本。

无论是上面的例子,ZK-KYC,DALL-E 风格的图像生成,还是智能合约中的大型语言模型,ZKML 的世界中都存在着一个完整的用例世界。然而,要真正实现这些,我们强烈认为 ZK prover 仍需要大量改进。特别是对于自我完善的区块链的未来。
那么,我们该何去何从?
我们有具体的表现数据,我们知道在证明神经网络时哪些技术往往表现最好。当然,我们开始发现各种用例,这些用例激励了我们不断成长的社区。

我想知道接下来会发生什么……
很快就会为你们提供更多更新;)
原文:https://medium.com/@ModulusLabs/chapter-5-the-cost-of-intelligence-da26dbf93307


