一文读懂以太坊新升级方案Danksharding:设计思路、意义及未来展望



来源:Mirror
作者:Mtyl
前言
Danksharding于2021年末被Dankrad提出,引发了以太坊社区讨论的热潮。Danksharding帮助以太坊实现了“中心化出块 + 去中心化验证 + 抗审查性”,并将以太坊打造成了结算层与数据可用性层,为L2的计算性能提升留下空间。有人评价:“Danksharding将让新公链黯然失色”。
当前华语圈关于Danksharding的详细讲解非常少,多为英文资料的翻译,而英文资料往往默认读者已经知道许多前置知识、学习曲线陡峭。因此,笔者希望能够尽可能通俗、清晰的讲清楚Danksharding的基本思想和其意义,供感兴趣的朋友们阅读交流。
摘要
-
分片 是公链L1扩容中最有前景的分案;之前的以太坊分片1.0分案因为数据同步和MEV的问题,目前已经被废弃
-
Danksharding的意义:实现了“中心化的出块 + 去中心化的验证 + 抗审查性”,将以太坊打造成结算层与数据可用性层,为L2的计算性能提升留下空间
-
Danksharding的核心设计:通过RS编码和KZG承诺,解决了数据可用性问题,实现了网络验证的去中心化;通过出块者-打包者分离(PBS),解决MEV问题;通过抗审查清单(Crlist),解决了抗审查问题
-
Proto-Danksharding:Danksharding的第一步实现,对交易引入新特征,预计2023年实现
-
公链发展趋势展望:“去中心化验证”和“模块化”或成为叙事焦点
一、分片:公链L1扩容中最有前景的方案
以太坊是当前所有支持智能合约的公链中使用率最高、去中心化程度最好的。但是以太坊每秒能处理的交易数(TPS)只有15-20笔,其性能也是主要公链中最低的。这进一步带来了许多衍生的问题,比如高Gas费、区块拥堵等。
不过这其实也是值得理解的 —— 毕竟以太坊现在架构的基础是2014年自比特币改良而来的,当时整个区块链领域都没有多少成熟的设计思想可供借鉴。早在2017年ICO浪潮之时,就有许多人切身体会到了以太坊原生架构设计的弊病,开始关注研究以太坊的性能提升问题,也就是扩容。
扩容的解决方案分为两大阵营:链下扩容与链上扩容。链下扩容即是现在通称的Layer2,包括状态通道、Plasma、Rollups等,它们不直接改动区块链本身的规则(区块大小、共识机制等),而是在其之上再架设一层来完成具体的工作;链上扩容需要直接修改区块链的基础规则,包括区块大小、共识机制等,这也被称为L1扩容。
分片(Sharding),是当前众多L1扩容方案中被公认为最有前景的。分片本质上是一种并行计算或者说分治的思想:原本网络中的验证者都干着同质化的工作,如果能让他们分工完成不同的任务,那单位时间内处理的任务数自然就增多了。根据具体分工对象的不同,分片可被进一步划分为网络分片、交易分片、状态分片等。
许多新公链的设计都是以分片为核心的,比如Near、Harmony等,他们目前也取得了不小的成就和影响力。在这样的背景下,分片和“PoW转PoS”一起,共同构成了以太坊2.0(现称“以太坊合并”)叙事的核心。
二、以太坊分片1.0设计:思路与缺陷
Sharding 1.0,是对Danksharding出现之前的以太坊分片设计方案的统称,对此做些大概了解是有必要的。不过该方案目前已经被废弃,所以并非本文介绍的重点。
2.1 状态分片
Sharding 1.0希望实现状态分片。状态,指的是每个以太坊账户地址的余额,或者是智能合约地址的代码内容和变量数值;它可以被视为一个大账本,所有验证者都需要实时维护、不断更新它。而如果能把这个大账本分成多份(比如64份),验证者也随机分为多组,每组只负责一个账本相关交易的记账,那么速度无疑会加快很多。如下图所示:
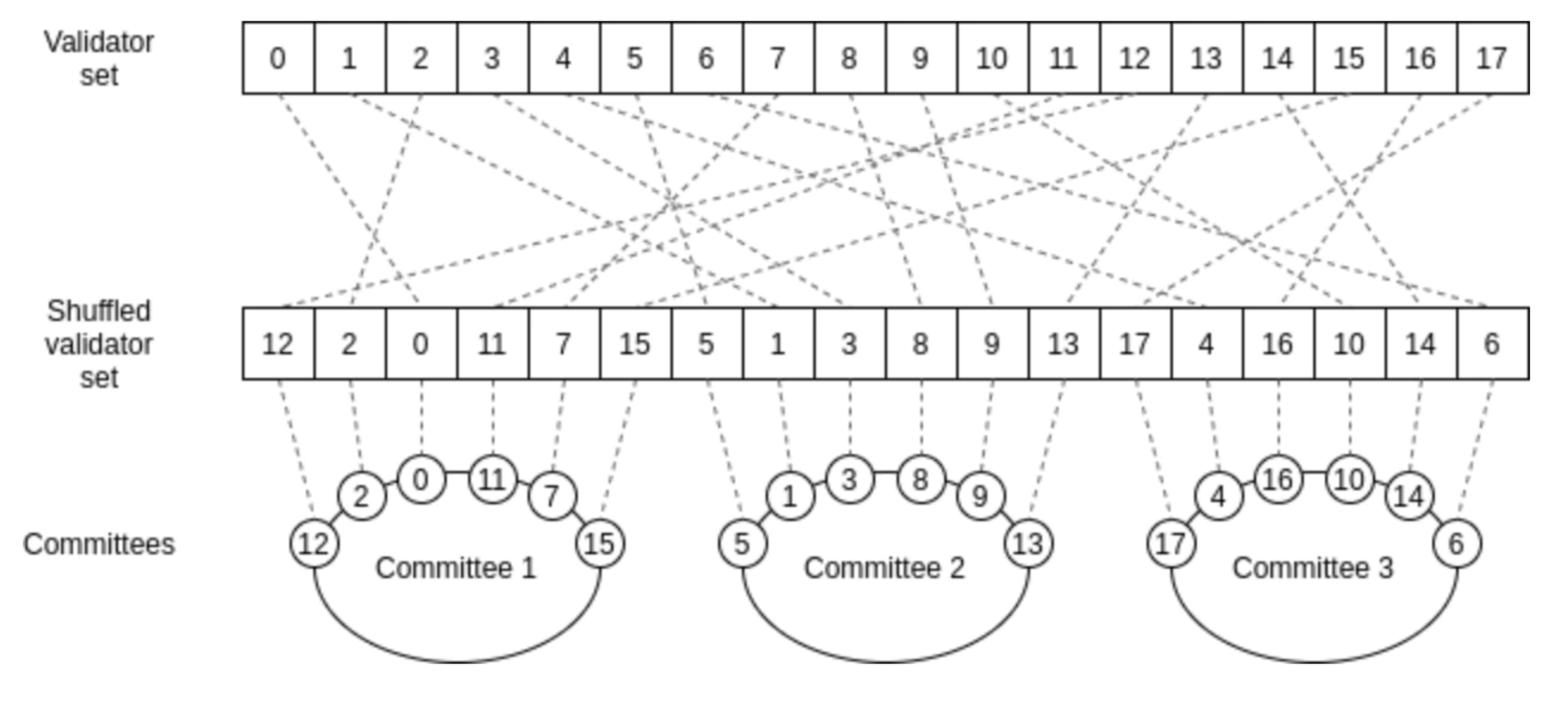
下面这个三个村庄的故事有助于更好的理解状态分片:有一个渔村、一个猎户村、一个农夫村,村庄内和村庄间常常有交易,但没有货币,大家记账。以前是用一个账本记三个村子的账,速度有点慢,现在改成三个账本记,那么由哪个账本来记哪些帐?一个方法是,渔村有一本账,猎户村有一本账,农夫村有一本账,账本中都只有自己村庄的账户信息,也只记录自己村庄内的交易。如此一来三个账本就可以同时记账,记账效率高,存储需求少。这正是以太坊采用的分片方法:状态分片,每个分片存储且只存储属于自己分片的账户状态。三个村庄的账本可以视作三个并行的分片链,在分片内部达成共识的过程与原先相仿。
显然,这个分案在设计之初就必须要解决跨分片(跨村庄)交易的可行性问题,这也是所有状态分片设计中所面临的重难点之一。
2.2 实现思路
Sharding 1.0计划把以太坊分为64个分片链,每个链至少分配128位验证者(即总验证者数量至少为16384),采用PoS共识。
为了协调不同分片链之间的通信,Sharding 1.0的设计中引入了信标链(Becon Chain):它是Sharding 1.0设计的核心,可以为整个系统提供统一的时间轴,并且跨分片交易提供最终确定性。如下图所示:
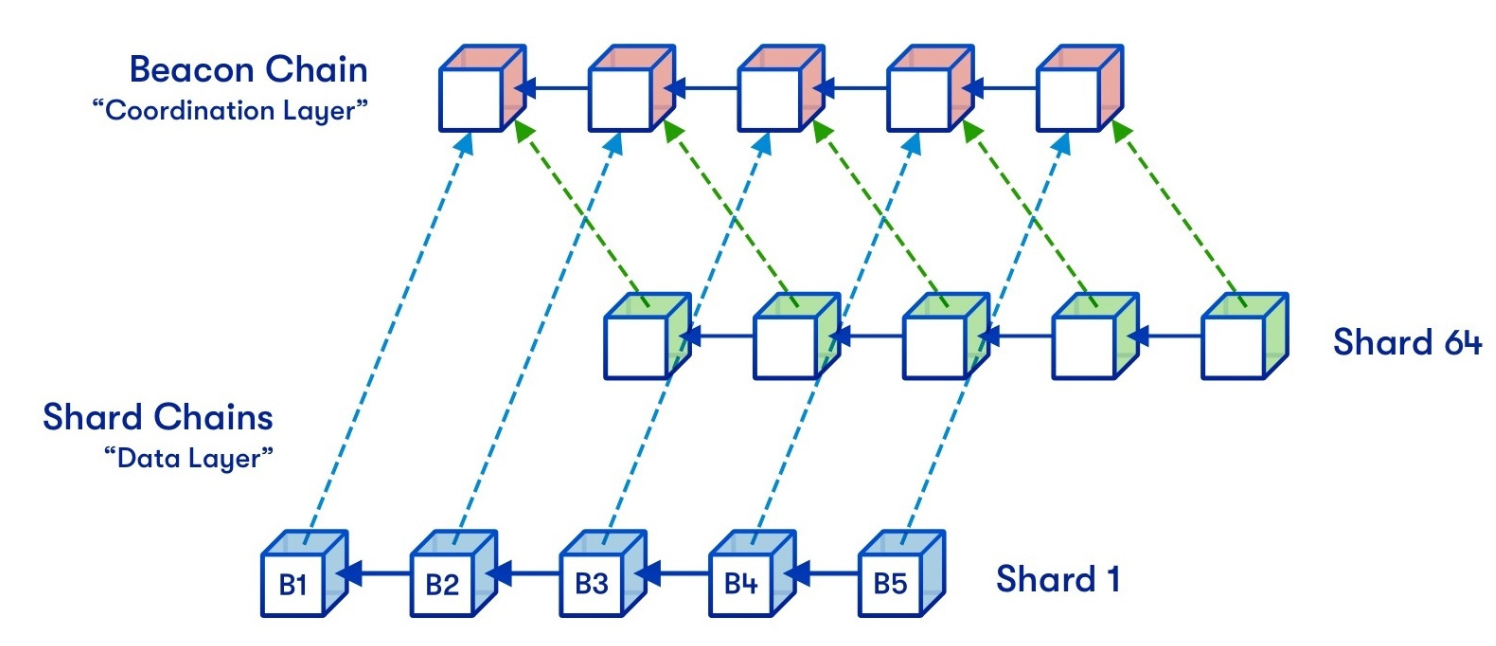
每过6.4分钟(称作1个epoch),每个分片链所对应的验证者就会被打乱重排。这么做,是为了防止攻击者对分片链的蓄意攻击,毕竟如果1个分片链的验证者一直不变的话,想在这个分片链上作恶只需买通128个验证节点的大多数,这个成本其实并不高。但如果有了这个打乱重排的机制,那么攻击者需要至少买通30-40%的验证者才有机会事先发动攻击。
(如果对Sharding 1.0相关细节设计感兴趣的朋友,可以参考:https://ethos.dev/beacon-chain/,https://vitalik.ca/general/2021/04/07/sharding.html)
2.3 核心问题:数据同步
了解以上Sharding1.0的简单机制,就可以大致理解它面临的问题了。
我们可以看到,每一个epoch过后,每个验证者就需要切换自己所负责的分片链。然而,处理新分片链,就需要拥有新分片链的状态和对应的交易数据,这需要进行一次大范围的网络节点数据同步。这是相当复杂的,实际上,很难保证验证者们能够在规定时间节点完成同步 —— 这会带来网络延迟和糟糕的用户体验。虽然后续也有一些简化方案,但他们又要面临一些针对性攻击的问题,从而又需要进一步的打补丁。这使得整套解决方案变的相当麻烦。
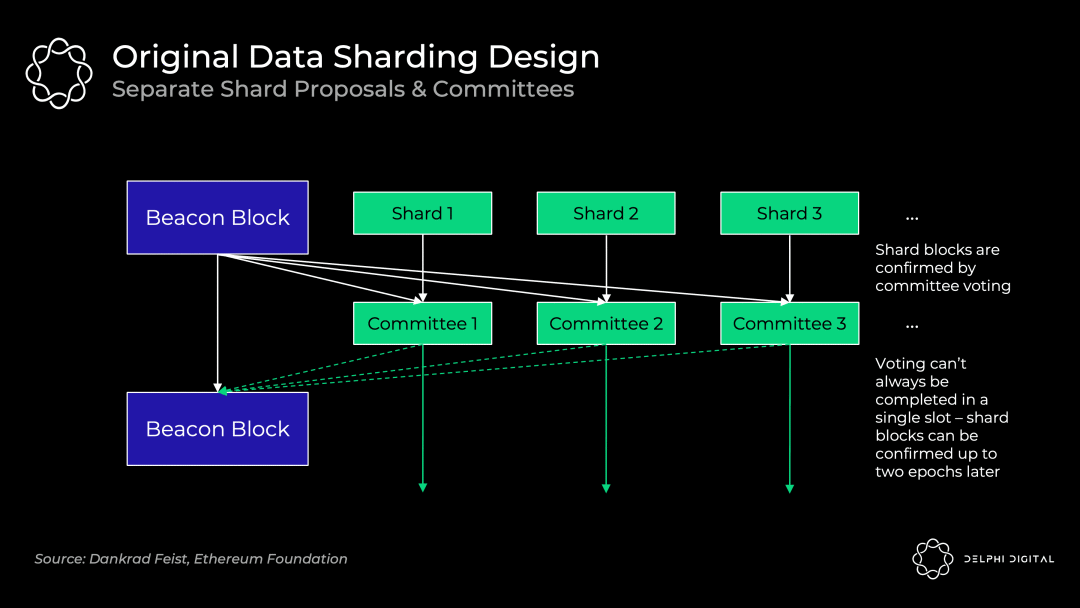
那如果放弃状态分片,让所有验证者都同步存储所有分片的历史交易数据,又会怎样呢?这个看似在当下是可行的,毕竟现在以太坊的全部历史交易数据加起来也不过约170G,大多数节点都能胜任。但是,随着分片后以太坊性能的大幅提升,存储数据的积累势必大大加快,这必然导致对节点的存储性能要求节节攀升,从而降低网络的去中心化程度。因此这个方案最多只能作为一个过渡。
2.4 另一个问题:不断增长的MEV
MEV ,是“矿工可提取价值”的简称。它的存在,是由于验证者(矿工)能够事先看到用户的交易,从而他们可以针对性的提出自己的交易,通过控制交易排序的方式让自己获利。
这是一个严重的问题,不少人已经发出警告,认为这可能会导致以太坊的失败:“这就像是聘请黑手党老大们当公务员,让他们来管理国家”。(参考阅读:MEV Auctions Will Kill Ethereum)
然而,之前的PoW转PoS和Sharding 1.0不仅不能帮忙解决这个问题,反而可能会进一步加剧它的严重程度。这主要是因为ETH发行率降低、验证集中化程度提高等问题导致的。相关细节可以参考:MEV in eth2 - an early exploration
三、Danksharding详解
和之前一系列以太坊分片相关的提案不同,Danksharding并不试图改进Sharding 1.0分片链的方案,而是另辟蹊径,用一套新分案来具体化“分片”这一思想。
Danksharding的核心思想,非常契合V神在《Endgame》一文中对以太坊甚至公链L1未来发展的畅想:中心化的出块 + 去中心化的验证 + 抗审查性。具体而言,它主要做了下面三件事:
-
通过数据可用性采样(DAS),大大降低了参与网络验证的成本,保持了网络验证的去中心化;
-
通过出块者-打包者分离(PBS),原先维护以太坊所有历史状态数据的全节点,被进一步划分成两个角色:出块者(Proposer)和打包者(Builder)。这不仅为大量数据包的传输提供了可能,也解决了MEV问题。
-
通过抗审查清单(Crlist),避免了交易被审查的可能性。
3.1 数据可用性采样(Data Availability Sampling)
3.1.1 数据可用性
数据可用性,指的是区块生产者(矿工/验证者)必须公布并提供他们生产区块的交易数据,以便全节点来检查他们的工作。如果区块生产者不提供这些数据的话,全节点就无法检查他们的工作,从而无法确保他们有在遵守区块链规则。
数据可用性问题一直以来也是区块链扩容所面临的挑战之一,因为随着区块链的扩容,下载数据并做验证对节点的性能要求也会越来越高,这会导致去中心化程度的降低。
3.1.2 数据可用性抽样(DAS)
数据可用性抽样(DAS),是一种减轻节点验证数据可用性的负担的方案。
它的主要思想是通过一定的数学设计,让验证节点只需要检查部分数据碎片,就可以从概率上证明一个大数据块的可用性,而不需要验证节点去检查全量的数据。这样,对验证节点的性能要求就大大降低了。
Danksharding使用RS编码和KZG承诺来实现数据可用性抽样,让我们来看看它们的大致思路:
3.1.3 Reed-Solomon(RS)编码
RS编码是一种纠删码的具体方案,而纠删码(Erasure Coding)是一种编码容错技术,通过将数据分割成片段并做扩充,来实现在网络中的冗余传输。
为了更好的理解RS编码的原理和作用,先看一个非常简单而直观的例子:
-
现有2个数m、n,希望能够通过RS编码在不可靠的网络中进行冗余传输
-
我们构造一次函数 f(x) = ax + b,任取4个x值(下文以0、1、2、3为例)
-
我们令:m = f(0) = b、n = f(1) = a + b,这样可以解出a = n - b、b = m;即通过m、n两个数,唯一确定了一个一次函数
-
我们设:p = f(2)、q = f(3),计算出 p = 2a + b = 2n - m, q = 3a + b = 3n - 2m
-
我们将m、n、p、q四个数在网络中分发
-
根据初中关于二元一次方程的知识,不难理解m、n、p、q中任意成功收到2个,都能够计算出m和n;也就是说,哪怕我们在传输中丢失了50%的数据,我们依然可以重构原始数据。
RS编码具体应用于数据可用性抽样的思路大致是这样的:
-
把原来待检查的大数据块分成X个碎片,冗余编码成2X个碎片,其中任意X个碎片都可以复原出原来的大数据块。
-
验证节点做验证的时候,不再需要下载全部数据,而只需要从网络中采样并检查k个碎片,来查看它们是否可用、且是否为合法的编码。(k值视具体对安全性的需要进行选取,下文取k=30)
-
如果它们都可用且编码合法,那么就说明网络中无法找到X个碎片从而复原数据的概率小于0.5^30,进而说明数据分发节点成功隐藏原始数据的可能性小于0.5^30。(更严谨一些的表述:数据可用性<50% 的概率小于0.5^30)
-
而0.5^30,是一个相当小的、实用中可以被接受的概率
RS编码能够恢复数据背后的数学原理,就是通过构造出2X个只有X个未知数的方程组,其中任意X个方程都可以解出这X个未知数。具体的构造形式可以说理解是一种多项式构造的方法:通过X个碎片,就可以构造出一个X-1次的多项式函数,如同前文通过两个数构造一次多项式。给定2X个变量取值(比如0,1,2,…2X-1),就可以计算出2X个函数值,知道任意X个值,都可以复原出原先的X个碎片。
这里我们还剩下面的问题有待解决:如何使得编码人在不向验证人披露原始数据的情况下,证明他确实按照预先设定的多项式规则编码了?
KZG多项式承诺,就是用来解决这个问题的。
3.1.4 KZG多项式承诺
KZG承诺是一个密码学技术,大致原理如下:
-
对多项式f(x),证明者通过椭圆曲线密码学技术,对该多项式做出承诺 C(f):对于这个多项式的任意值 y = f(z),证明者可以计算出一个 "证明" π(f,z)
-
对于验证者,已知承诺 C(f),给出证明 π(f,z)、变量z、取值y 三个数据,验证者可以证实 f(z)= y,即(z,y)确实在这个多项式函数上
-
这个证明无需验证者知道这个多项式具体是什么,并且它的时间开销近似为常数,因此具备高度的实用性和可扩展性
因此,通过KZG承诺的计算与分发,我们就实现了编码合法性的证明。
3.1.5 降低重构数据的难度 —— 2D RS编码与KZG承诺
如果把一个大区块的数据直接打包,切成碎片后(比如256个)做RS编码后分发,这会遇到什么问题呢?主要问题是,无法满足重构能力的去中心化:重构数据的时候需要组装全部的数据,这对重构节点的要求就会非常高,相当于要求重构节点拥有媲美做切数据的中心化出块者的性能。这和做DAS的初衷就矛盾了 —— 因为我们希望那些性能不高的节点也能够重构数据。
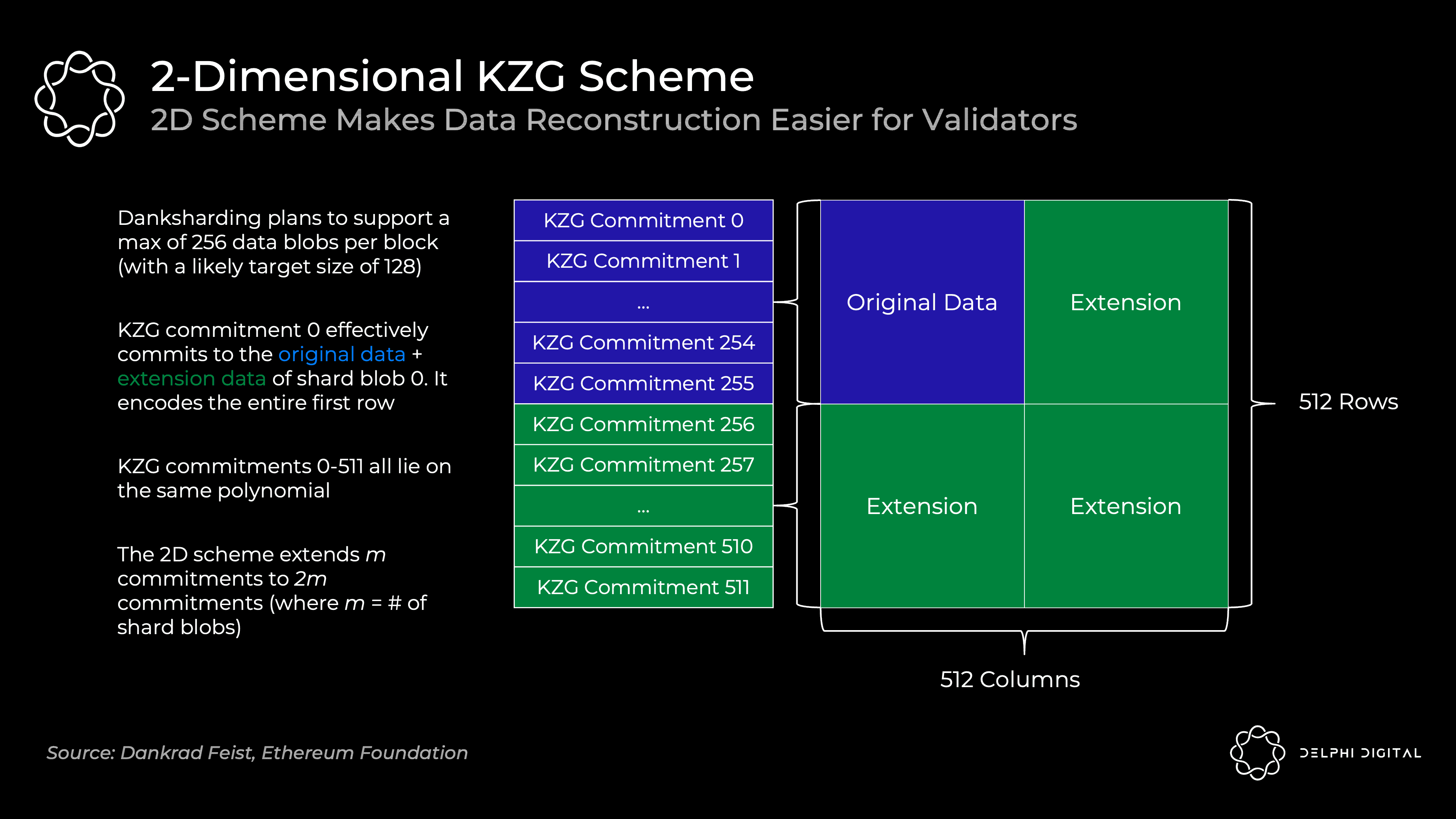
针对这个问题,Danksharding进一步提出了RS编码的二维扩展。从“分片”视角可以更好的理解这种二维扩展:
-
如下图所示,我们先把大数据块分成256个分片
-
对每个分片,我们把它分成256个碎片,用RS编码扩展成512个碎片,对每个碎片进行1,2,3,…,512的编号
-
将编号相同、但处于不同分片的碎片重新分为一组,这样我们一共得到512组,每组有256个碎片
-
再对每组中的256个碎片,用RS编码扩展成512个碎片
-
这样,我们就相当于把被分成256x256个碎片的原数据块,给扩展成了512x512个碎片
二维方案在验证的时候,由于只有当75%及以上的碎片可用的时候,才能确保原始数据的恢复(例如考虑下图极端情况,>25%缺失的数据都集中在红色区域,有可能会导致原始数据中“蓝红相交”的那一部分无法被恢复)。所以,验证节点需要保证75%及以上的数据大概率可用。要实现与一维分案采样30次相同的安全性,需要验证节点采样75次。(0.5^30和0.75^75处于一个数量级)
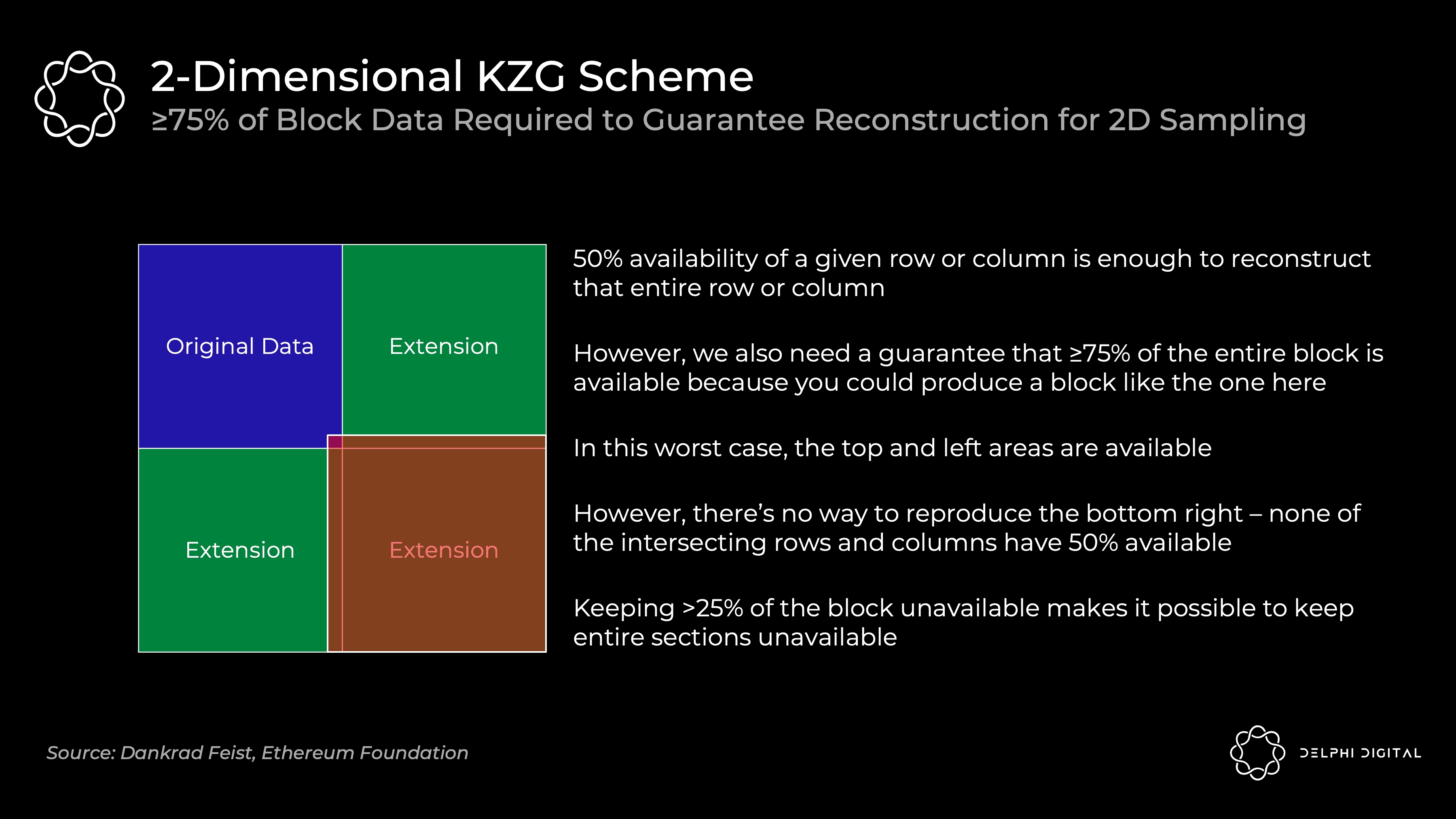
综合来看,采用二维方案的好处,就是进一步降低了验证节点进行验证的成本:
-
减轻了节点验证数据的负担。在刚才的例子中,二维分案虽然需要采样75次而不是30次,但是它的碎片大小只有一维方案的1/256,这就降低了对节点的带宽要求。
-
减轻了节点重构数据的负担。因为,如果哪个分片出了问题,就只需要重构对应的分片即可,而不是重构全部原始数据,大大降低了重构的工作量;即使需要重构全部数据,也可以让不同的节点并行合作,分别重构不同的行/列,进而复原数据。
3.2 出块者-打包者分离(Proposer-builder Separation)
通过二维RS编码和KZG承诺,我们已经解决了最棘手的数据可用性问题,实现了低配置要求、去中心化的节点验证。
但是,我们也可以看到,这个方案也提高了全节点的性能要求,加剧了全节点的中心化程度和MEV问题。这个时候,原本因解决 MEV 问题而提出的“出块者-打包者分离”(PBS,Proposer-builder Separation)恰好派上了用场:
3.2.1 角色分离抗MEV的原理
回顾一下现在的以太坊中的全节点,它实际上同时承担了“打包者”和“出块者”两个角色:即,他们既要构建区块的内容,也要负责对出块进行验证+投票。PoW中的矿工在前一个区块上构建以进行 "投票";合并转PoS之后,验证者将直接投票来决定区块是否有效。
而在PBS中,这两个角色是分开的:
-
原先的全节点若仍想参与区块打包,配置要求将进一步提高,转变为“打包者”;它们通过竞价的方式,来争取下一个区块的打包记账权。
-
从众多低配置要求的验证者中,轮换随机选出一个“出块者”;它根据“价高者得”,来选哪一个“打包者”获得真正的记账权,并即刻获得“打包者”的竞价作为收益。
-
打包者完成打包以后的区块,依然需要全体验证节点来进行验证,以决定其是否合法、有效;但无论验证结果怎样,“出块者”的收益都是已经实现、不需要退回的。
通过这种角色分离,就解决了当前的MEV价值分配问题:打包者依然可以通过交易排序,提取 MEV。但在一个有效市场中,区块打包者们会开始“内卷”,出价到它们能从区块中提取的全部价值(减去它们的摊销成本,如硬件开支等)。而所有的这些价值,都分配给了去中心化的验证者们、而不是那些中心化的打包者们,这符合以太坊发展的理念。
3.2.2 可能的PBS初步实现:双槽PBS
PBS的确切实现依然在讨论中,采用“承诺-披露”机制的双槽PBS是最有可能的方案,它的实现如下图所示:
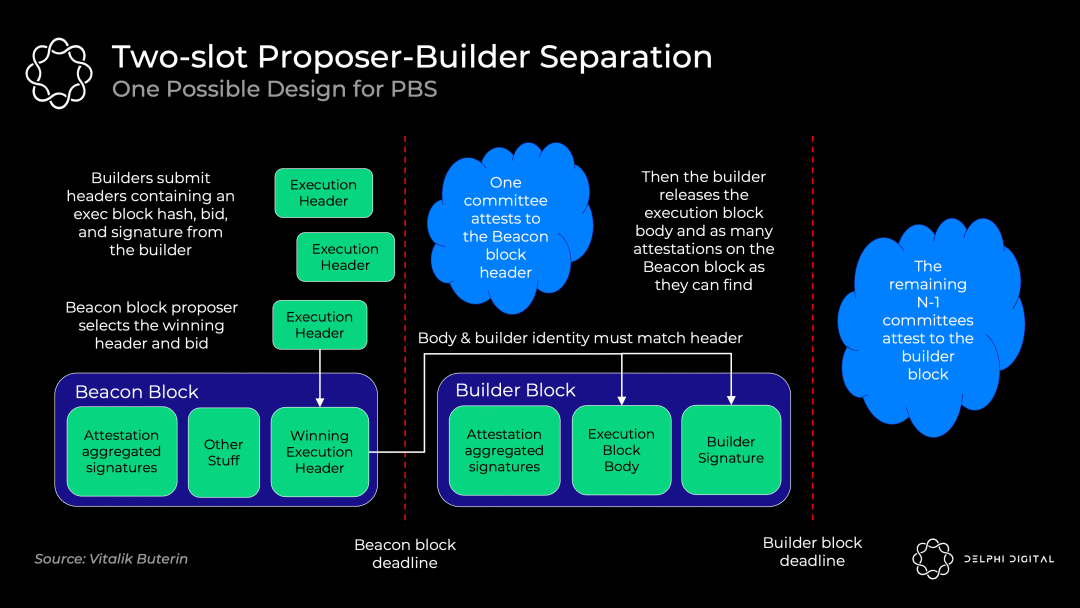
-
打包者们提出它们各自的区块头和出价
-
出块者选择获胜的区块头和打包者,并将无条件得到中标费(即使区块打包者未能生成有效区块)
-
验证委员会确认获胜的区块头
-
打包者披露获胜的区块体
-
验证委员会确认获胜的区块体(如果中标的区块打包者不出示区块体,则投票证明该区块体不存在)
如果直接让打包者们用完整的区块体竞标,不仅需要消耗大量的带宽,还会有MEV盗取问题——如果一个区块打包者提交它的完整区块,则另一个区块打包者可以观察到并找出策略,进而迅速发布一个更好的区块。承诺-披露方案规避了这些问题。
延时,是这种 "双槽" 设计的缺点。如果我们12秒进行一次投票出块,那么进行一次真正的有效出块需要 24 秒的时间(两个 12 秒的插槽)。如何把这个时间进行缩短也是一个正在研究的问题。
3.3 抗审查清单(crList)
现在还剩下的问题是,PBS 增强了区块打包者审查交易的能力:区块打包者可以故意忽略某些合法的交易。
抗审查清单(crList,Censorship Resistance List)就是用来解决这个问题的,它要求出块者指定一个在存储池中看到的所有符合条件的交易列表;区块打包者在出价的时候需要证明自己看到了这个列表,打包的时候需要强制包含列表中的交易,如下图所示:
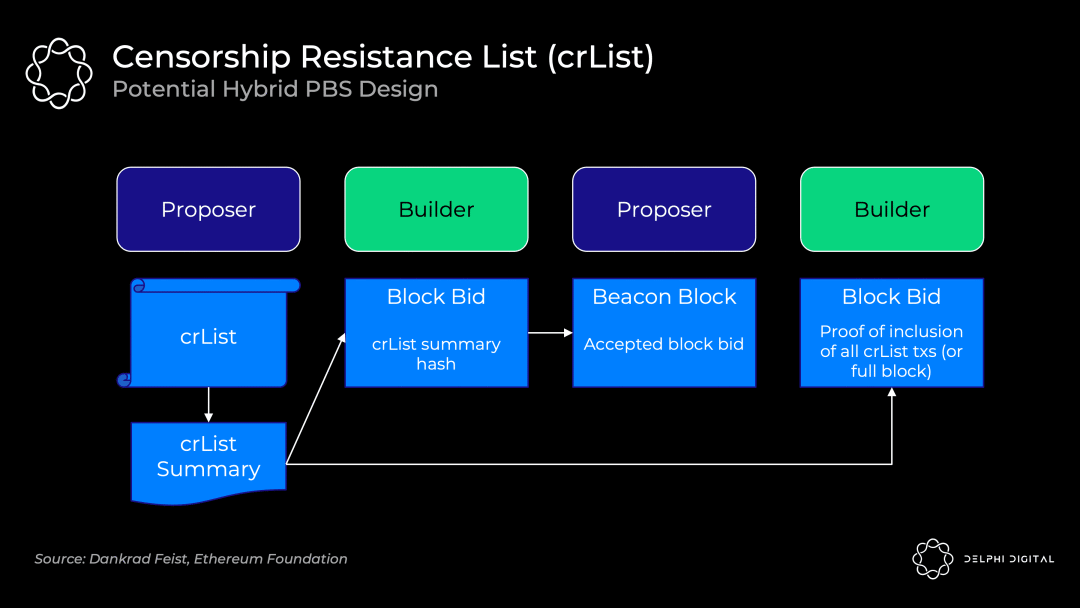
这里还有一些细节问题有待完善,比如对于刚才这种设计,对出块者而言的最优策略就是提交一个空列表,只要谁出价最高谁就能获胜。相关的完善设计也正在讨论中。
3.4 Danksharding还是分片么?
如果你对之前的各种分片方案有所了解,在理解了Danksharding的设计思路以后,你可能会有一个疑惑:这还是分片么?对什么分片了?
其实,有这个疑惑是很正常的。因为Danksharding做的事情确实不能被划进传统的“网络分片 - 交易分片 - 状态分片”的范畴。“分片”这种思想,主要是体现在数据的碎片化分发、验证节点无需下载全量数据上面,但也仅此而已了。在第五部分笔者也将介绍,Danksharding的第一步实现甚至和分片毫无关系。
不过,也不必过多纠结Danksharding“是不是分片”。毕竟,评价一个技术,关键还是看其是否足够高效实用。
四、Danksharding对以太坊的意义
通过实现了“中心化的出块 + 去中心化的验证 + 抗审查性”,Danksharding 最大的意义,在于把以太坊L1变成了一个统一的结算(settlement)和数据可用性(Data Availability)层,从而为L2的计算性能扩展留巨大空间。
结算和数据可用性本身都不是新概念。但当它们结合起来以后,就给了L2 Rollups很大的想象间:Rollups的工作原理核心是链下计算和数据压缩,这就需要空间来存储这些压缩数据,而 Danksharding 正提供了巨大的数据空间。因此若Danksharding真的实现,长远来看,Rollups 的 TPS 可以达到数百万。
这也是为什么有人会评价Danksharding会“令新公链黯然失色”的原因:如果以太坊有这个性能,那还有大多数的新公链什么事呢?
另外,Danksharding 还保留了 ZK-rollups 和 L1 以太坊执行之间的同步调用,也就是说,来自分片数据块的交易可以立即被确认并写入 L1,因为它们都发生在同一个区块中。
五、Proto-danksharding:实现的第一步
Proto-danksharding(又名EIP-4844)是一个提议,用于实现构成完整 Danksharding 规范的大部分逻辑和“脚手架”(例如交易格式、验证规则),是通往Danksharding的第一步。
Proto-danksharding 的主要特征是引入了新的交易类型,可以认为是对每个交易添加了一个新的特征,我们称之为携带 blob (Binary Large Object)的交易。携带 blob 的事务类似于常规事务,不同之处在于它还携带一个称为blob的额外数据。Blob可以非常大(~125 kB)。但是,EVM 的执行无法访问 blob 数据;EVM 只能查看对 blob 的承诺。
Proto-danksharding实际上没有实现任何分片。因为在 proto-danksharding 实现中,所有验证者和用户仍然必须直接验证完整数据的可用性。
由于所有相关升级都需要在PoW转PoS之后完成,在乐观的情况下,我们可以在2023年看到Proto-danksharding的实现。
六、对公链发展趋势的展望
中心化出块 + 去中心化验证 + 抗审查,似乎真的是当下公链L1突破”不可能三角”的最可能的路径;其实,不少新公链的设计在一些思路上也可以看到Danksharding中一些元素的影子。
另外,通过Danksharding,以太坊把L1做成了一个结算层和数据可用性层,而把真正的计算性能提升交给了L2。这其实是一种公链模块化的思路:将系统分解为多个模块组件,每个模块都是一条区块链,它们会负责不同的功能(例如执行层、共识安全层、数据可用性层、DEX应用链、稳定币应用链、 NFT 应用链、衍生品应用链等等),这些模块可以随意剥离出来,也可以重新组合在一起。具体一点说,可以是通过高速的Rollup执行交易,安全的结算层负责结算,低费用大容量的数据可用性层用负责保障。Celestia等模块化公链也有类似的设计思路。
目前公链的综合性能,离成为“下一代互联网的基础设施”还有相当远的距离。不过,在众多Web3 builder的努力下,相关解决方案也将会被不断提出。“去中心化验证”和“公链模块化”这两个关键词,也许我们会在接下来一段时间有关公链的技术文章中不断看到。


