


基于最新的性能指标比较以太坊 2.0 主网上 5 个主要客户端。
原文标题:《以太坊 2.0 主网客户端性能比较》
撰文:Afri Schoedon
翻译:ETH 中文站
2020 年 12 月以太坊 2.0 信标链发布之后,现在是时候介绍以及比较现有的协议实现了。本文作为该系列文章的第一部分,将按照字母排序比较 5 个主要客户端的信标链节点性能和资源利用率。
-
Lighthouse (Rust, Sigma Prime)
-
Lodestar (TypeScript, ChainSafe Systems)
-
Nimbus (Nim, Status)
-
Prysm (Go, Prysmatic Labs)
-
Teku (Java, ConsenSys Quorum)
以太坊 2.0 主网基础设施由三个主要组件组成:
-
信标链是 PoS (权益证明) 链。当前的以太坊 1.x 链 (共识为 PoW) 与以太坊 2.0 合并之后,信标链将成为保障以太坊安全的主干网。
-
验证就好比 PoS 共识中的矿工。所有人都可以质押 32 ETH 成为验证者,有权提议新区块、对区块敲定进行投票,然后获得奖励。
-
罚没者正监视验证者是否作恶,以防攻击事件发生。任何一名验证者违反规则,都会受到惩罚并被移出网络。
需要注意的是,本文主要关注第一点,信标链是以太坊 2.0 网络的基础。研究人员可以在 Github 上找到所有相关的脚本、数据和绘图,以便进一步分析:
byz-f / eth2-bench-mainnet
本文将重点列出这些发现?
同步指标
第一个也是最令人兴奋的问题:同步以太坊 2.0 信标链节点信息需要多长时间,结果见下图。
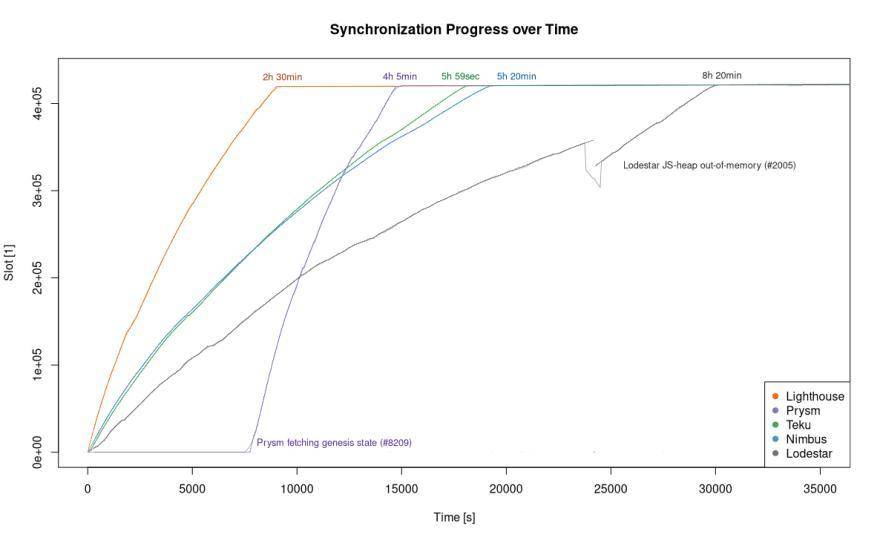
在上表中,通过比较客户端同步相同的 slot 需要花多少时间来比较其同步进程。在评选结果之前 (虽然这不是本文的讨论范围),关于该图表我们需要知道三件事。
1. Prysm (紫色线) 有个特殊的地方是,它会连接以太坊 1.x 节点,从验证者信息登记处获取所有 ETH 存款,然后从 Eth1 状态下构建 Eth2 创世。虽然从安全的角度来看,这一特性蛮有用的,因为用户不必信任 Prysm 的开发者以获得正确的创世状态,但是这一过程需要些时间。因此,客户端启动与同步启动的时间有明显的偏移。(#8209)。
2. 由于出现 JavaScript 堆内存不足的问题,在基准测试时 Lodestar (灰色线) 出现了崩溃 (#2005)。但是,它在 10 秒后由脚本自动重启。
3. 不可见:在初始同步时,Loderstar 还没有完全验证所有签名 (#1217)。因此,目前尚不清楚 Loderstar 与其他客户端的比较情况。
上面的图表中,我们可以看到 Lighthouse (橙色线) 整体表现出色,Prysm、Teku (绿色线) 和 Nimbus (蓝色线) 在保持速度方面表现出色。但是,让我们再来看看下面的图表:
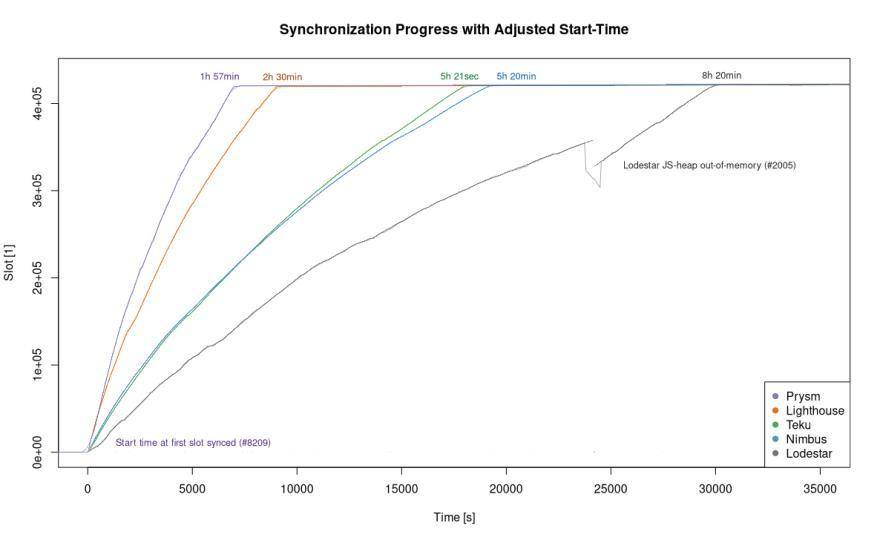
在这个图表中,我们把 Prysm 客户端启动和同步启动 (即第一个信标链区块产生) 之间的时间偏移删去。那么可以看出,单纯比较同步速度的话,Prysm 的表现略优于 Lighthouse,不到两个小时就能同步完成,而 Lighthouse 需要两个半小时。Teku 和 Nimbus 大概需要五个小时。
值得注意的是,Eth2 TypeScript 实现 (Lodestar 使用的语言) 并不是仅为了成为运行一个全信标链或者验证者节点的首选客户端。相反,Lodestar 将为以太坊 2.0 去中心化应用的所有 web、浏览器和基于插件的组件提供基础设施。
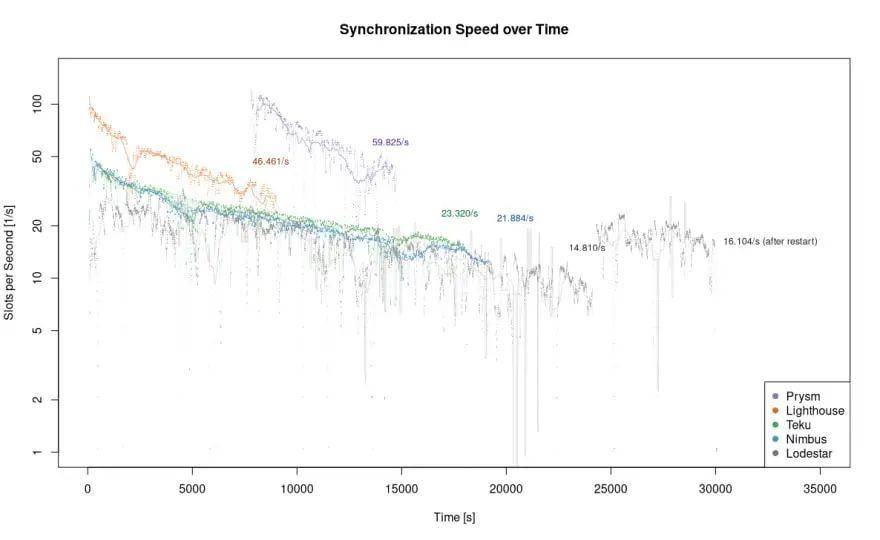
假设我们知道了客户端的信标头区块当前所在的 slot 高度,并且可以查看在这 60 秒之前区块头的高度的话,我们就可以通过展示各客户端每秒同步的 slot 数 (用点表示),来计算过去 60 秒的移动平均值以比较各客户端的同步速度。移动平均值超过 10 分钟的则用实线表示。
结果与前一个图表一致。尽管 Prysm 因为要花时间获取 Eth1-状态,它仍是同步速度最快的客户端,每秒同步 60 slots。Lighthouse 紧跟其后,每秒同步 46 slots。稍显落后的是 Teku (23/ 秒) 和 Nimbus (22/ 秒)。
然而什么是 slot 呢?在传统的区块链如比特币和 Eth1 链中,要么有区块要么没有。那么当比较这些链上的客户端性能时,我们会以块数 / 秒为单位来比较其同步速度。这跟以 slot 数 / 秒 为单位有何不同呢?
在以太坊 2.0 中,每 12 秒总有一个指定的 slot。如果验证者被分配到一个 slot 中提议区块,该 slot 便有一个区块。然而,如果验证者错过该 slot,那么便是个空 slot (没有区块),但尽管如此,slot 的计数将继续进行。因此,在以太坊 2.0 中,我们以 slots/ 秒 为单位计算同步速度。
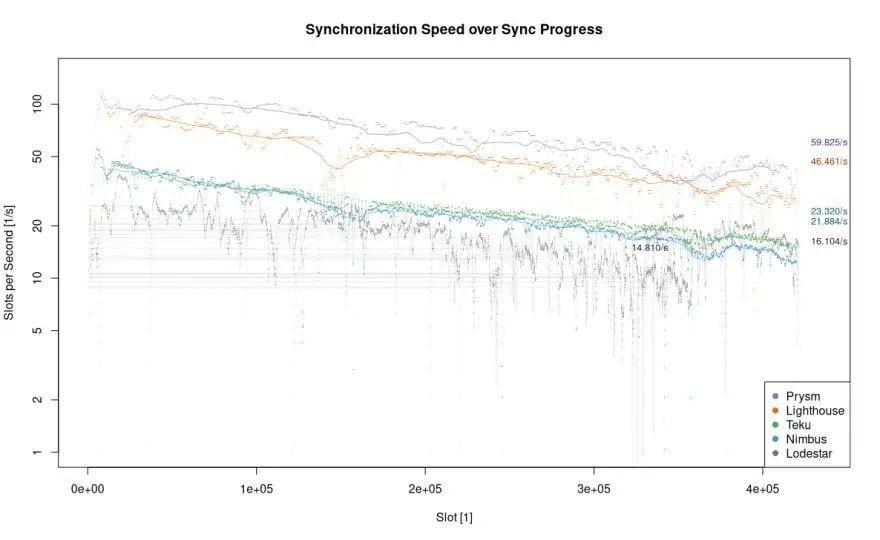
在这个图表中,我们把 (时间) 这一变量删去,横坐标为已同步的 slot 数,并把上一个图表中的同步速度映射到该图表中。所有客户端都显示一个趋势:随着 slot 的增加同步速度下降。由于该数据是在以太坊 2.0 主网上搜集的,我们知道有一条验证者队列正排队等候进入 2.0 网络。在撰写本文时,等候队列上有 13_458 名验证者,按照每天新增 900 名验证者的速度来算,需要等待将近 15 天。
了解了以太坊 2.0 主网验证者数量呈线性增长之后,我们可以假设活跃验证者集的规模变大使得同步速度减缓。
计算资源指标
在上半部分中,我们仅分析了同步指标,选出同步最快的客户端。但是哪个客户端在资源利用方面快且高效呢?
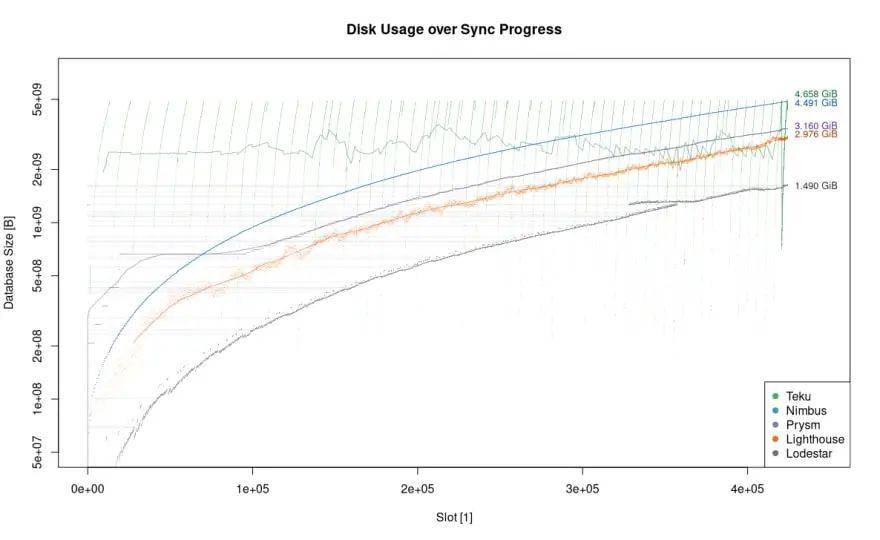
上面的图表中,随着同步 slot 的数量增加,比较各客户端的数据库容量。值得注意的是,关于完全同步主网节点 (420_000 slots),Lodestar 的占用空间最小,总共只有 1.49 GiB。Lighthouse (2.98 GiB) 和 Prysm (3.16 GiB) 的结果也不错。
我们知道 Eth1 节点存储完整的区块历史数据。尽管如此,Eth1 节点还是移除了历史状态以最小化数据库所需的磁盘空间。Eth2 节点与这个概念相当。在磁盘上储存所有块的同时,他们会删除最终状态。两者的主要区别为:为了方便起见,应将历史状态存储于时段边界中 (epoch boundaries)。目前,Nimbus 每 32 个 epoch 在时段边界存储状态,然而 Lodestar 每 1024 个 epoch 将状态记录在磁盘中。在图中可以清楚地看出差异。
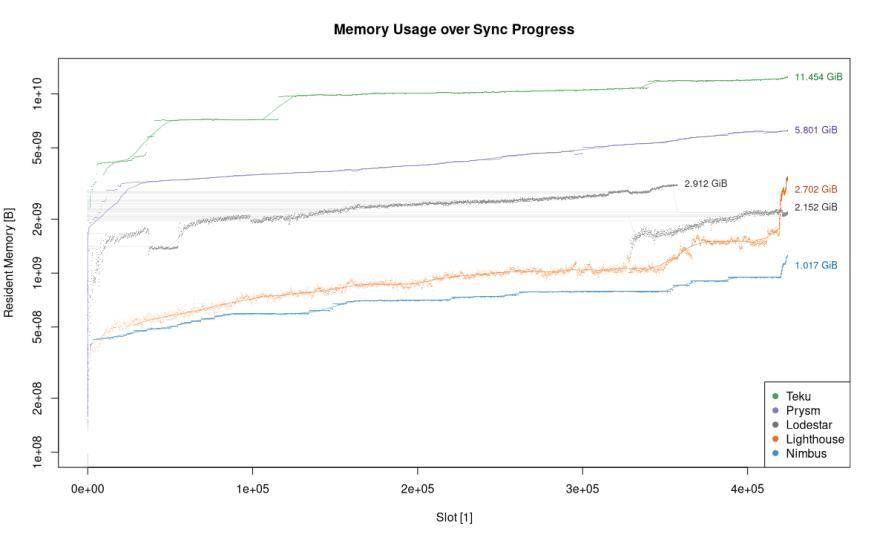
该图表相同,但是绘制了同步期间每个客户端的常驻内存集的大小。从图中得出,Nimbus 客户端非常高效,在信标链主网的整个处理过程仅需要约 1 GiB RAM。紧接其后的是 Lighthouse 和 Lodestar,均略低于 3 GiB。
注意:Java 分配给 Teku 的堆外内存不在客户端开发者的控制范围之内。JVM 对可用内存的消耗量特别大。Teku 的指标结果在可用内存总量不同的情况下差异十分大。
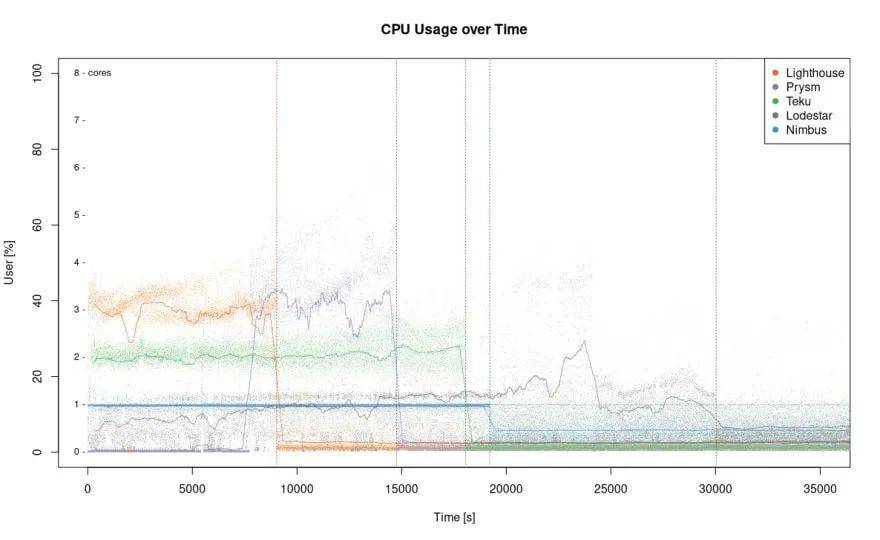
最后但同样重要的一点是,让我们看一下 CPU 的利用率。在上面图表中可以看到客户端之间的一些有趣差异。
区块链属于一种高度分层的数据结构。同步区块链数据、验证区块以及计算最新状态,大部分工作都是按序列进行的。因此,客户端面临的挑战便是尽可能地使该进程平行化。图表显示的结果与同步速度指标相当,Prysm 和 Lighthouse 领先 (数值更高意味着更加有效),而 Teku 保持良好。
FAQ
Q: 文章不错,但请问为什么你没有比较流量指标呢?
A: 我有比较,只是没有对所有指标比较都进行评论。你可以在 Github 上找到没有进行注释的点对点、流量指标,想要进一步研究的话 访问
Q: 你个人来说推荐哪个客户端?
A: 这个问题很难回答。靠感觉走的话,我选择 Lighthouse,我觉得它的总体用户体验、性能、功能以及工具可用性都很好。然而,Prysm 仍是最成熟并且是目前最快的客户端。Teku 的使用体验也很好,我认为所有客户端都是产品级别的。
Q: 信标链数据库大小会超过 1 TiB 吗?
不,首先,与 Eth1 相比,信标链本身相对较小。驱动数据库大小的主要因素是信标状态。然而,与 Eth1 相比,Eth2 并不需要将所有状态存储在磁盘中,因为用户总是可以从本地运行的区块中重建任何状态。
除此之外,PoS 有敲定这一工序,而 PoW 没有 (reorgs, 51% 攻击)。一旦区块被敲定,该区块永远不会被篡改。敲定的意思是,将来客户端不用再从创世开始同步链的数据,而是获取最后敲定的 epoch 的最新链头的数据。
来源链接: dev.to
